11. Approximation¶
约 6740 个字 预计阅读时间 34 分钟
在上一章中我们介绍了 P/NP 问题,而大家普遍认为 P ≠ NP,这就意味着对于某些问题,我们无法使用多项式时间解决,而在问题规模变大时,越发不可接受。
因此,我们考虑能否退而求其次,在多项式时间内求一个比较优的解。更具体的来说,我们尝试寻找一种多项式算法,使得其结果始终在关于最优解的可接受偏差范围内,对于这种算法,我们称之为近似算法(approximation algorithm)。
11.1 近似算法¶

我们设\(f(n, x)\)是对输入大小为\(n\)的情况下,对计算结果\(x\)所付出代价Cost的直观量化(例如 dist, weight...),若设\(x^*\)为最优解,\(x\)为给定算法结果,则我们定义近似比(Approximation Ratio) \(\rho(n)\):
则称给定算法为\(\rho(n)\)近似算法(\(\rho(n)\)-approximation algorithm)。
"近似算法 v.s. 随机算法"在看到近似算法时,我脑子里一下子浮现出了随机算法的概念,同样是求最优解的近似解,两者有何区别呢?
近似算法和随机算法最大的区别就是,当我们设计、分析、讨论近似算法的时候,我们关注的都是它的最坏情况。也就是说,
近似算法是完全可控的,而纯粹的随机算法则是通过概率来减少坏情况出现的可能,并没有严格的约束。近似算法最坏也就坏到\(\rho\),而随机算法最坏可以坏到海拉鲁大陆。
11.1.1 近似范式¶
定义11.1 假设有某类问题(例如背包问题),其中的一个具体实例记为I(当背包问题的参数给定的时候即为一个实例),且有一个复杂度为多项式的近似算法A。定义:
• A(I) 为算法A 在实例I 上得到的解;
• OPT(I) 为实例I 的最优解。
考虑到该类问题是最小化问题,所以若存在\(r \geq 1\),对任意的I都有\(A(I) \leq r \dot OPT(I)\),那么称A为该问题的r-近似算法,r就是近似比

近似范式(approximation scheme)指的是对于某个优化问题的一族相同模式的算法,它们满足对于确定的\(\epsilon > 0\),算法的近似比为\(1+\epsilon\)。
也就是说存在算法A,使得对任意的实例都有\(A(I) \leq (1+\epsilon)OPT(I)\)
可以粗糙地理解为:“范式”是一个输出为算法的特殊函数,而\(\epsilon\)是“范式”的一个参数,对于特定的\(\epsilon\),“范式”输出一个特定的算法(这些算法有着相同的模式),而这些“范式”输出的算法,都解决同一个问题,并且对于任意固定的\(\epsilon\)其近似比为\(1+\epsilon\)。
而关于\(\epsilon > 0\)这个约束,是因为近似比必定大于 1。
而此时,这一族的算法的复杂度可以表示为\(O(f(n, \epsilon))\),如\(O(n^{2/\epsilon}), O((\frac{1}{\epsilon})^2n^3)\)。当\(f(n, \epsilon)\)关于\(n\)是多项式时(也就是说算法的运行时间以问题规模|I|的多项式为上界),我们称其为多项式时间近似范式(polynomial-time approximation scheme, PTAS)。当\(f(n, \epsilon)\)关于\(n\)和\(\frac{1}{\epsilon}\)都是多项式时,我们称其为完全多项式时间近似范式(fully polynomial-time approximation scheme, FPTAS)。
为什么要区分 PTAS 和 FPTAS 呢?我们观察\(\epsilon\)对算法的影响:随着\(\epsilon\)的减小,近似比逐渐变小,即准确度提高;而\(\dfrac{1}{\epsilon}\)变大,而通常来说\(\dfrac{1}{\epsilon}\)与算法复杂度都是正相关的,因此会导致算法复杂度升高(可能指数级别增长)。
- 如果说这个近似范式是 FPTAS,那么为了提高准确度而缩小\(\epsilon\),导致的复杂度变化是相对可接受的(多项式级的变化,如\((\dfrac{1}{\epsilon})^2n^3\)关于\(\dfrac{1}{\epsilon}\)是多项式级的);
- 然而如果它不是 FPTAS,那么\(\epsilon\)的缩小可能带来恐怖的复杂度增加(如\(n^{2/\epsilon}\)关于\(\epsilon\)是指数级的)。
11.2 [案例] Approximate Bin Packing¶
装箱问题指的是,给定\(N\)个 item,第\(i\in [1,N]\)个 item 的 size 为\(S_i \in (0,1]\),一个 bin 的大小为\(1\),尝试寻找最少的,能够装载所有 item 的 bin 的数量。
eg "🌰 例子":
给定 7 个 item,size 分别为\(0.2, 0.5, 0.4, 0.7, 0.1, 0.3, 0.8\),则最少需要 3 个 bin(最优解):
- bin 1:$0.2 + 0.8$; - bin 2:$0.7 + 0.3$; - bin 3:$0.4 + 0.1 + 0.5$;
这是一个 NP hard 问题,现在我们考虑三种近似解法。需要注意的是,这三种都是在线(online)解法,即处理\(item_i\)时我们不知道\(item_{i+1}\sim item_{N}\)的情况。之后我们会再讨论离线(offline)做法,也就是我们知道所有 item 的情况以后再给出策略。
11.2.1 (online) Next Fit (NF)¶
NF 策略总是选择当前最后一个 bin,若能够容纳,则将当前 item 放入其中,否则新开一个 bin。
void NextFit ( )
{
read item1;
while ( read item2 )
{
if ( item2 can be packed in the same bin as item1 )
place item2 in the bin;
else
create a new bin for item2;
item1 = item2;
} /* end-while */
}
【Theorem】 Let M be the optimal number of bins required to pack a list I of items. Then next fit never uses more than 2M – 1 bins. There exist sequences such that next fit uses 2M – 1 bins.
逆反命题:If Next Fit generates 2M (or 2M+1) bins, then the optimal solution must generate at least M+1 bins.
proof :
我们从 NF 的结果出发,证明当 NF 的结果为需要\(2M+1\)或\(2M\)个 bin 时,最优解为至少需要\(M+1\)个 bin。
假设\(S(B_i)\)表示第\(i\)个 bin 的 size,则根据 NF 的定义,有:\(S(B_{i}) + S(B_{i+1}) > 1\)(只有当第i个bin装不下东西了,才能启用第i+1个bin,也就是说第i个bin的剩余空间不允许第i+1个bin所装的物品的体积)。或者使用反证法,假设\(S(B_{i}) + S(B_{i+1}) \leq 1\),这说明无论\(B_{i+1}\)中有多少 item,都一定能放进\(B_i\),而这与 NF “\(B_i\)放不下了才开始放\(B_{i+1}\)” 的性质相违背。于是我们将所有桶两两配对:
1.当 NF 的结果是需要\(2M\)个 bin 时:
即 item 的总 size 至少为 M+1,即最优解至少需要\(M+1\)个 bin。
2.而当 NF 的结果是需要\(2M+1\)个 bin 时,可以转化为\(2M\)的情况,显然2M+1个bin所装物品的体积大于2M个bin所装物品的体积。
Next Fit的近似比约为2,上界来源于上方的计算,\(\rho = \dfrac{A(I)}{OPT(I)} \leq \dfrac{2M+1}{M+1} \approx 2\)
下界来自实例:所有的物品大小为\(\dfrac{1}{2},\epsilon,\cdots,\dfrac{1}{2},\epsilon\),一共有m组\(\dfrac{1}{2},\epsilon\),其中\(\epsilon\)充分小,m充分大,那么NF的解为m,最优解为\(\dfrac{m}{2}+1\),\(\rho > \dfrac{m}{\frac{m}{2}+1} \approx 2\)
11.2.2 (online) First Fit (FF)¶
FF 策略总是选择第一个能放下当前 item 的 bin,若所有 bin 都无法容纳当前 item,则新开一个 bin。
void FirstFit ( )
{
while ( read item )
{
scan for the first bin that is large enough for item;
if ( found )
place item in that bin;
else
create a new bin for item;
} /* end-while */
}
【Theorem】Let M be the optimal number of bins required to pack a list I of items. Then first fit never uses more than 17M / 10 bins. There exist sequences such that first fit uses 17(M – 1) / 10 bins.
FF 策略总是使用不超过\(\lfloor 1.7M \rfloor\)个 bin,并且存在一族能对边界取等的输入,其中\(M\)表示最优解的 bin 数量。
11.2.3 (online) Best Fit (BF)¶
BF 策略总是选择能够容纳当前 item 且剩余空间最小的 bin(即 tightest),若所有 bin 都无法容纳当前 item,则新开一个 bin。
NF 策略也总是使用不超过\(\lfloor 1.7M \rfloor\)个 bin,并且存在一族能对边界取等的输入,其中\(M\)表示最优解的 bin 数量。
看似BF有比FF更高的bin利用率,但是事实并非如此。
考虑下面5 个物品的实例:0.5、0.7、0.1、0.4、0.3。此实例FF 需要2 个箱子,而BF 则需要3 个;考虑下面4 个物品的实例:0.5、0.7、0.3、0.5,此实例用FF 需要3 个箱子,而BF 只需要2 个。
这两个例子说明不会存在“BF 总比FF 好” 或者“FF 总比BF” 好的结论。

此外,关于在线做法(在处理当前item时,不能得知后面的item情况。并且一旦做出决策便无法修改),有一个结论:You never know when the input might end. No on-line algorithm can always give an optimal solution.
【Theorem】There are inputs that force any on-line bin-packing algorithm to use at least 5/3 the optimal number of bins.
对于装箱问题,如果限定使用在线做法,则最优的近似解法,其最坏情况的结果也至少需要最优解的\(\frac{5}{3}\)。
11.2.4 (offline) First Fit Decreasing (FFD)¶
离线做法的优势在于它能够获得所有 item 的信息以求统筹规划。
solution: 将 item 按照 size 降序排序,而后使用 FF(或 BF,由于单调性,两者等价)。给定 7 个 item(同之前的 🌰),经过排序后,它们的 size 分别为$0.8, 0.7, 0.5, 0.4, 0.3, 0.2, 0.1,则最少需要 3 个 bin(最优解):
- bin 1:$0.8 + 0.2$; - bin 2:$0.7 + 0.3$; - bin 3:$0.5 + 0.4 + 0.1$;
【Theorem】Let M be the optimal number of bins required to pack a list I of items. Then first fit decreasing never uses more than\(11M / 9 + 6/9\)bins. There exist sequences such that first fit decreasing uses\(11M / 9 + 6/9\)bins.
proof:
假设所有的物品为\(a_1 \geq a_2 \geq ... \geq a_n > 0\), 考虑第\(j = \lceil \dfrac{2}{3}FFD(T) \rceil\)个bin\(B_j\)
-
如果它包含了一个\(a_i > \dfrac{1}{2}\)的物品,那么\(B_j\)前面的bin中物体的体积都超过1/2,由于排在\(a_i\)前面的物体体积都超过了1/2,因此至少有\(j\)个体积超过\(\dfrac{1}{2}\)的物品,这些物品被放在不同的箱子里,于是
\[ OPT(I) \geq j \geq \dfrac{2}{3}FFD(I) \] -
若不然,也就是说\(B_j\)中没有体积超过1/2的物品,那么除了最后一个箱子\(B_{FFD(I)}\),\(B_j\)及其之后的箱子内都至少有两个体积不超过1/2的物品。于是至少有\(2(FFD(I)-j)+1\)个物品无法放入前\(j-1\)个箱子,所以
\[ \begin{aligned} OPT(I) &> min\{j-1,2(FFD(I)-j)+1\}\\ & >min\{\lceil \dfrac{2}{3}FFD(I)\rceil -1, 2(FFD - (\dfrac{2}{3}FFD + \dfrac{2}{3})) + 1 \}\\ & = \lceil \dfrac{2}{3}FFD(I)\rceil -1 \end{aligned} \]
11.3 [案例] Knapsack Problem¶

背包问题(fractional version):给定一个容量为\(M\)的背包,以及\(N\)个 item,第\(i\)个 item 的重量为\(w_i\),其利润为\(p_i\)。其中\(x_i\)表示装入物品的比例(也就说一个item可以拆分只占一部分,这部分的利润是\(p_ix_i\)),要求在不超过背包容量的前提下,使得背包中的利润最大化。
根据每一个物品能否自由拆分,背包问题分为 fractional version 和 0-1 version 两类。
11.3.1 Fractional Version¶
如果我们记\(x_i\in[0,1]\)为第\(i\)个 item 的选中量(即假设 item 都是连续可分的),则约束条件可以表述为\(\sum_{i}^N w_ix_i \leq M\),现在求\(\sum_{i}^{N} p_ix_i\)的最大值。
假设现在\(M = 20.0\),并且\(N = 3\),分别是:
- item 1:\(w_1 = 18.0, p_1 = 25.0\);
- item 2:\(w_2 = 15.0, p_2 = 24.0\);
- item 3:\(w_3 = 10.0, p_3 = 15.0\);
则最优解为\(x_1 = 0, x_2 = 1, x_3 = \frac{1}{2}\),此时\(\sum_{i}^{N} p_ix_i = 31.5\)。
由于\(x_i\in[0,1]\),非常朴素的一个想法就是,尽可能多地选择“性价比”高的物品。也就是说,我们可以按照\(\dfrac{p_i}{w_i}\)(PPT 称之为 profit density)降序排序,而后从大到小依次选择物品,直到背包装满为止。(该算法就是最优解)
11.3.2 0-1 Version¶
相较于 fractional version,0-1 version 要求\(x_i \in \{0,1\}\),换句话说每一个物品要么选要么不选。这是一个经典的 NPC 问题,我们尝试使用近似算法来求较优解。
11.3.2.1 贪心做法¶
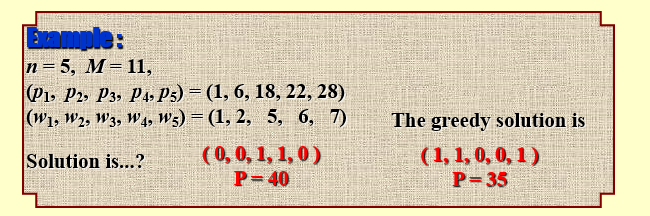
我们可以使用贪心算法,贪心策略可以是总是选可以放得下的、还没放入中的,利润最大的或\(\frac{p_i}{w_i}\)最大的。这些做法的近似比(approximation ratio)都是 2。 我们用\(p_\text{max}\)表示所有 item 中最大的利润,用\(P_\text{optimal}\)表示最优解,\(P_\text{greedy}\)表示我们使用贪心做法得到的答案。在该问题中,近似比的计算表达式为:
下面是证明过程:
将\((2)\)式两侧同除以\(P_\text{greedy}\)得:
将\((3)\)式两侧同除以\(P_\text{greedy}\),并代入\((4)\)得:
\[ p_\text{max} \leq P_\text{greedy} \leq P_\text{optimal} \leq P_\text{frac} \]其中\(P_\text{frac}\)指的是同样的数据下 fractional version 的答案。
补充结论:背包问题具有 FPTAS。
11.3.2.2 动态规划做法¶
\(W_{i,p} = \text{the minimum weight of a collection from } \{1, …, i\} \text{ with total profit being exactly } p\)
- take i:\(W_{i,p} = w_i + W_{i-1,p-p_i}\)
- skip i:\(W_{i,p} = W_{i-1,p}\)
- impossible to get p:\(W_{i,p} = \infin\)
由于p_i > p, 如果将item i 放入背包,利润就大于指定的 p 了,所以要跳过item i。对于otherwise情况,显然我希望求的是相同利润下物品的重量最小,这样才能装最大价值的物品
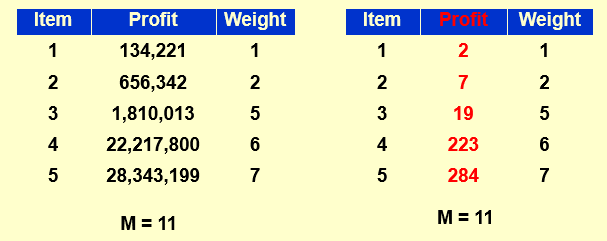
如果\(p_\text{max}\)很大,可以考虑将它们近似取整,类似于将浮点数向上取整。
warning "注意"
这里讨论的背包问题有一个非常重要的特点就是,容量和利润都是实数,更直白的来说,你没办法通过将容量或利润作为状态来 dp 求最优解。
也就是说,上述计算的时间复杂度O(N^2 P_max),其中p_{max}是未知量可以无穷大,指数级别,这样就不是多项式时间复杂度了
11.4 [案例] The K-center Problem¶
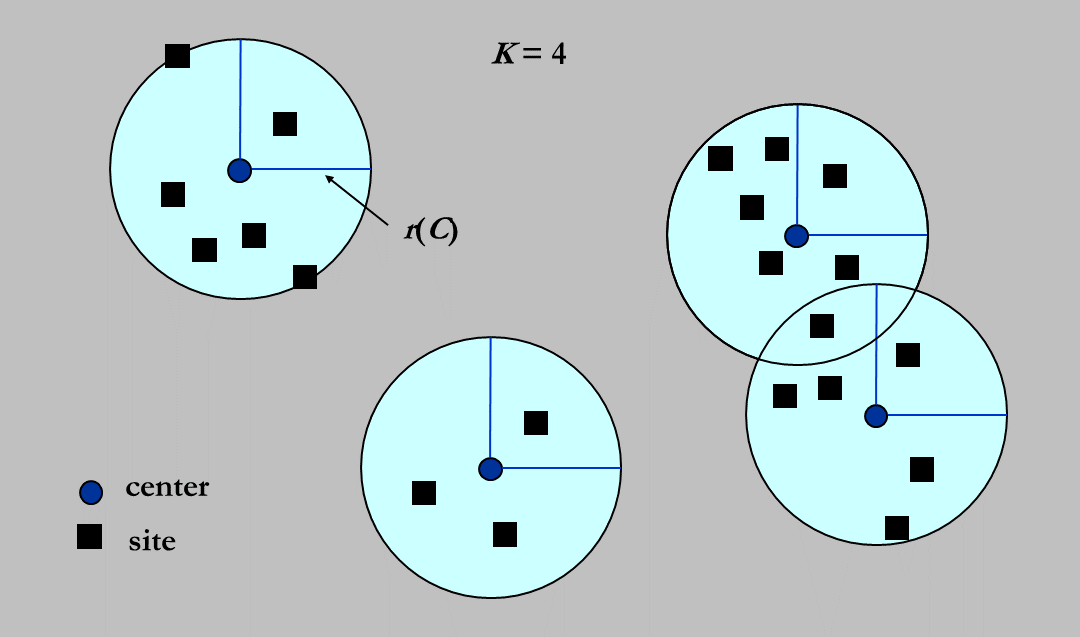
(二维)K 中心问题指:给定平面上的一系列 site(即点),在平面中找出\(k\)个不同的 center,记\(site_i\)到离它最近的 center 的距离为\(dis_i\),求\(\max \{dis_i\}\)的最小值。 设\(C = \{c_1, c_2, ..., c_k\}\)为\(k\)个 center,\(S = \{s_1, s_2, ..., s_n\}\)为\(n\)个 site,我们定义 site 到关于 center 的集合\(C\)的距离为: $$ dis(s_i, C) = \min_{c_i\in C} { dis(s_i, c_i) } $$
即\(s_i\)到距离它最近的 center 的距离。
定义最大的最小覆盖半径为:
现在要寻找一个\(C\)使得\(r(C)\)最小(\(|C| = k\))。
平面的问题我们就用平面的思路来看,就是一个平面上有一堆点,现在我要在上面找\(k\)个中心去画圆,使得这\(k\)个圆能覆盖所有的点。现在要求最大的那个圆的半径最小能多小。
11.4.1 Naive Greedy¶
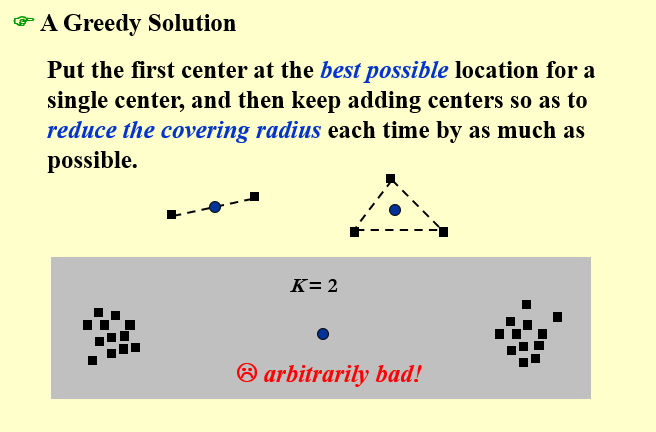
一个做法是,我们每次都选择最可能成为中心的那个点,具体来说:
- 如果是第一个点,就选取所有点的中心;
- 如果不是第一个点,就选取能一个最能让\(r(C)\)下降的;
这个做法的 bug 比较大,假设我们的点是聚类非常明显的两个点云,那么第一个点就会落在两个点云之间
注意,随着 center 的增加,原来以\(c_i\)为 center 的 site 很可能以最新插入的\(c_j\)为 center。
11.4.2 2r-Greedy¶
既然正向做很困难,那我们能不能反着做呢?有一种套路叫二分答案,即先猜答案,再验证是否是答案。在这个问题中我们可以迁移这个思想,即先猜一个\(r\),然后尝试用\(k\)个半径为\(r\)的圆去覆盖剩下的所有点。
更具体的来说,假设最优解对应的一个 center 集合为\(C^*\),那么\(\forall r(C_x) \geq r(C^*)\)的\(C_x\)都必定存在覆盖方案;反过来说,如果我们能够验证对于\(C_x\)能够覆盖所有的点,那么就可以约束最优解\(r(C^*) \leq r(C_x)\)。
success "hint: 近似算法"
于是我们的近似算法就可以大展拳脚了。但是需要注意,这里所谓的近似算法,指的是使用二分答案求解\(r(C)\)这个算法,而非判断\(k\)个半径为\(r\)的圆能否覆盖所有点的算法。这一点非常重要!

首先,我们再次梳理一下这个算法,它包含内外两层,首先外部通过在答案的候选区间(即\((0, r_\text{max}]\),\(r_\text{max}\)为最远的两个点的距离)二分候选值,接着通过判定算法来判定接下来的二分方向。初始状态的\(r_x = (0 + r_{max})/2\),其中\(r_{max}\)在实时计算,\(r_x\)也在实时计算
设\(C_x\)表示选中的 center,\(S_x\)表示尚未被任何圆覆盖的 site,\(r_x\)表示当前二分出来的,要我们判断的半径,\(S\)依然表示所有 site 的集合:
- 初始化\(C_x = \emptyset\);
- 当\(S_x \not = \emptyset\)时(即还有点没被覆盖时),重复这些操作:
- 随机选取一个 site\(s_i \in S_x\),将其插入\(C_x\)(即将\(s_i\)当作一个 center),并从\(S_x\)中将\(s_i\)删除(即\(s_i\)必定被覆盖);
- 删除\(S_x\)中所有距离\(s_i\)不足\(r_x\)的点(即删除满足\(dis(s_i, s_j) \leq r_x\)的所有\(s_k \in S_x\));
- 当所有点都被覆盖后:
- 如果\(|C_x| \leq k\),则返回 yes;
- 否则返回 no;
如果返回 yes,则下一个\(r_x\)应当取更小的\(r_x\);如果返回 no,下一次应该取更大的\(r_x\)。
现在对其做进一步解释。这是一个启发式的做法,旨在每次寻找还没被覆盖的点作为新的 center,用一个半径为\(2r_x\)的圆去覆盖剩下的点(要想覆盖所有的点,必须采用最远的两个点的距离作为半径,同时2\(r_x = r_{max}\))。通过判断这样所需要的 center 数量是否超过\(k\)来判断是否能够覆盖。接下来很绕,请一步一步的看:
- 当这个启发式搜索成功时,说明\(2r_x \geq r(C^*)\),即\(k\)个\(2r_x\)的圆可以覆盖所有点;
- 当这个启发式搜索失败时,不能说明\(2r_x \geq r(C^*)\),即\(k\)个\(2r_x\)的圆不能覆盖所有点,因为启发式方案并不是最优方案;但是能说明必定不存在\(r_x\)的覆盖,即\(r_x \leq r(C^*)\)(证明见下方 lemma);
property "lemma
假设半径为\(r\),以\(c\)为圆心的圆\(C\)覆盖了\(S\)中的所有点。那么,对于固定的半径\(r'\),要想取任意的\(s_i \in S\)为圆心,形成的圆\(C_i\),总是能覆盖\(S\)中的所有点,则\(r' \geq 2r\)。
证明的关键是考虑两点分布在直径两端的情况。
这个引理的附加结论就是:\(\forall i \quad C \subset C_i\)
即以\(r\)为半径的最优覆盖圆,一定能被以任意\(s_i\)为圆心、\(2r\)为半径的圆所覆盖。
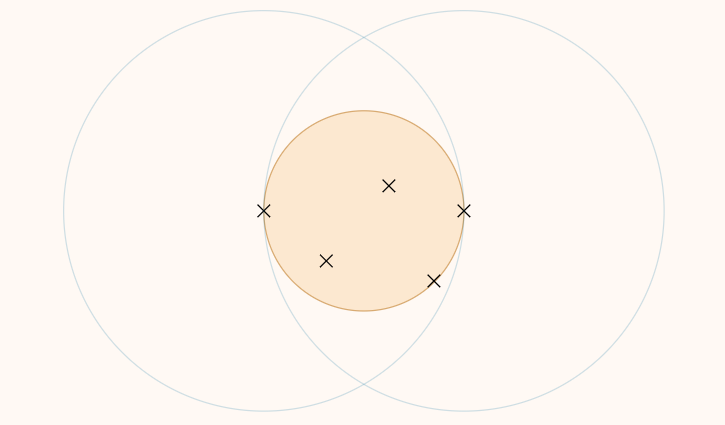
当我们发现我们处于情况 1. 时,我们开心的发现我们确实得到了一个距离\(r(C^*)\)更近的上界\(2r_x\),由于二分的性质,我们每次通过 1. 确定的上界,总是越来越紧的。
当我们处于情况 2. 时,我们不知道\(2r_x\)和\(r(C^*)\)的大小关系,但是知道\(r_x\)和\(r(C^*)\)的关系,由于二分的性质,我们每次通过 2. 确定的下界,也总是越来越紧的。
而最终,我们会得到一个最终的\(r_{x_0}\),满足:\(r_{x_0} \leq r(C^*) \leq 2r_{x_0}\)(式中哪边能取等取决于最后落在 1. 还是 2.)。
而我们最终给出的答案是\(2r_{x_0}\)(因为\(r_{x_0}\)不满足条件,不是解,更不是近似解)。
现在,我们来计算近似比:
11.4.3 Smarter Greedy¶
我们关注到,上面那个做法总是随机的选取新的\(c_i\),但是对于 center 的选取,我们其实可以总是选择距离已有的 center 最远的点,此外,当\(|C| > k\)时,我们也没必要继续做了。
section "流程描述" 1. 初始化\(C_x = \emptyset\),\(S_x = S\); 1. 随机选取一个 site\(s_i \in S_x\),将其插入\(C_x\),并从\(S_x\)中将\(s_i\)删除; 2. 当\(|C_x| \leq k\)且\(S_x \not = \emptyset\)时,重复以下步骤: 2. 选取一个 site\(s_i \in S_x\),这个 site 满足\(\forall s_j \in S_x \quad dis(s_i, C_x) \geq dis(s_j, C_x)\)(即这个点是还没被覆盖的点中距离\(C_x\)最远的点); 1. 将\(s_i\)插入\(C_x\),并从\(S_x\)中将\(s_i\)删除; 3. 如果\(|C_x| \leq k\)且\(S_x = \emptyset\),则返回 yes;否则返回 no。
由于这个做法实际上只是优化了一下启发式的策略,并没有改变内核,所以其近似比仍然是\(2\)。
11.5 总结¶
关于算法的设计,我们考虑这三个维度:
- 最优性(optimality):即算法要找到确切的最优解;
- 高效性(efficiency):即算法是否高效(通常是在多项式时间内运行);
- 普遍性(all instances):即算法是否普遍适用于所有的情况,解决所有的问题;
倘若一个解法:
- 同时满足最优性和高效性,那么这个算法对特殊情况能高效求最优解,(舍弃普遍性)能为一些问题的特例找到解决方法;
- 同时满足最优性和普遍性,那么这个算法对所有情况都能求最优解,(舍弃高效性),例如对于数据量不大的情况下使用回溯算法;
- 同时满足高效性和普遍性,那么这个算法可能是个近似算法,(舍弃最优性),高效地找到一个和最优解相差不大的答案;
就算 N=NP 成立,我们仍然无法保证三个愿望一次满足。
11.6 习题集¶
-
Suppose ALG is an α-approximation algorithm for an optimization problem Π whose approximation ratio is tight. Then for every ϵ>0 there is no (α−ϵ)-approximation algorithm for Π unless P = NP.
对于一种算法而言,近似比为 𝛼α ,那么 ∀𝛽>𝛼∀β>α ,都可以说 𝛽β 是其近似比。如果 𝛼α 是 tight 的,则 𝛼α 是一个下确界。
但这都只是对这一种算法的分析,一个 tight 的近似比只能说明你对这种算法的分析到位了,而不能说明这个问题没有更好的算法。这里完全是两码事。
-
As we know there is a 2-approximation algorithm for the Vertex Cover problem. Then we must be able to obtain a 2-approximation algorithm for the Clique problem, since the Clique problem can be polynomially reduced to the Vertex Cover problem.
F。
首先,确实有 Clique problem\(≤_𝑝\)Vertex Cover problem,Vertex Cover problem 也确实有 2-approximation 算法,但是这两个 problem 衡量 Cost 的标准是不一样的。
在 Vertex Cover problem 中的 2- 近似算法得到的解,在 Clique problem 约化成的 Vertex Cover problem 中得到的解虽然符合 Vertex Cover problem 的 Cost 标准下的 2- 近似,却并不一定符合 Clique problem 标准下的 2- 近似。
-
回顾团问题 (Clique problem) 的描述:寻找最大完全子图,那么寻找到的完全子图中顶点数 (𝐶1) 越多越好。
-
回顾顶点覆盖问题 (Vertex Cover problem) 的描述:寻找最小规模的顶点覆盖,那么寻找到的顶点覆盖中顶点数 (𝐶2) 越少越好。
回顾约化方法:
\[ |max \ clique \ of \ 𝐺∣= 𝐾 ⟺ ∣max \ vertex \ cover \ of \ 𝐺‾∣=∣𝑉∣−𝐾 \]设 Vertex Cover problem 的 2- 近似算法得到的顶点覆盖规模为 𝑇,最优规模为 𝑇∗,则
\[ \rho_2 = \dfrac{C_2}{C_2^*} = \dfrac{T}{T*} = 2 \\ \rho_1 = \dfrac{C_1*}{C_1} = \dfrac{|V| - T^*}{|V| - T} = 1 + \dfrac{1}{\frac{|V|}{T^*} - 2} \]可见 𝜌1 是不可控的。
-
-
For the bin-packing problem: let S=∑Si. Which of the following statements is FALSE?
A. The number of bins used by the next-fit heuristic is never more than ⌈2S⌉
B. The number of bins used by the first-fit heuristic is never more than ⌈2S⌉
C. The next-fit heuristic leaves at most one bin less than half fullD. The first-fit heuristic leaves at most one bin less than half full
-
对于A,设 next-fit 算法最终生成 2𝑀 或 2𝑀+1 个 bin,则
\(S = \sum_{i =1}^{2m}S(B_i) \geq \sum_{i=1}^m[S(B_{2i})+S(B_{2i-1})]>\sum_{i=1}^m 1 = m\)
所以如果NF需要2M或者2M+1个bin,那么最优解至少需要M+1个bin
-
first-fit(1.7-approximation) 优于 next-fit(2-approximation),因此 B 也正确。
-
对于 D,如果存在两个少于半满的 bin,那么在产生第二个少于半满的 bin 时,不可能在对前面 bins 的扫描中找不到放不进去的 bin(第一个少于半满的 bin 肯定能放进去),因此最多只有一个少于半满的 bin ,D 正确。
-
对于 C,两个少于半满的 bin 只要不是相邻出现就是可能的(0.2,0.9,0.2),因此 C 错误。
-
-
To approximate a maximum spanning tree\(T\)of an undirected graph\(G=(V,E)\)with distinct edge weights\(w(u,v)\)on each edge\((u,v)\in E\), let's denote the set of maximum-weight edges incident on each vertex by\(S\). Also let\(w(E')=\sum _{(u,v)\in E}w(u,v)\)for any edge set\(E'\). Which of the following statements is TRUE?
题目的意思是,如果把每个点最大权值的边加入一个集合,那么这个集合的权值和最大生成树权值之比是多少。注意,点的最大权值边集合意味着集合里相同的边最多出现一次。A.\(S=T\)for any graph\(G\)
B.\(S\neq T\)for any graph\(G\)
C.$w(T)\geqslant w(S)/2$for any graph$G$D. None of the above

-
In the bin packing problem, we are asked to pack a list of items L to the minimum number of bins of capacity 1. For the instance L, let\(FF(L)\)denote the number of bins used by the algorithm First Fit. The instance\(L′\)is derived from L by deleting one item from L. Then\(FF(L′)\)is at most of\(FF(L)\).