3. Inverted File Index¶
约 2670 个字 35 行代码 预计阅读时间 14 分钟
3.1 倒排索引¶
倒排索引(inverted file index)是一种常见的文本检索技术,用于快速查找包含特定单词或短语的文档。它通过将单词或短语作为关键字,并将它们出现在文档中的位置记录在一个索引中,从而支持快速的文本检索。在搜索过程中,系统可以快速地定位包含指定单词或短语的文档,并返回它们的相关信息。倒排索引广泛应用于搜索引擎、数据库系统和信息检索等领域。
—— ChatGPT
Wiki: https://en.wikipedia.org/wiki/Inverted_index
Definition: Inverted file contains a list of pointers(e.g. the number of a page) to all occurrences of that term in the text.
所谓的倒排索引,所有的思想都凝结在了“倒”,也就是 inverted。如果可以,我觉得用“逆”更合适。这里的索引对象指的是“文档”和“单词”之间的关系,而倒排索引的意思是,对于每一个单词,我们记录它出现在哪些文档中,以及记录他们出现的次数(频率)。
搜索引擎是一个非常常见的,倒排索引的应用案例,我们通过输入我们关注的词语,来索引包含这个词的所有文档。 当然,在这里我们考虑的是英文。
区分TF 和 DF
- \(TF\)(term frequency):一个单词在某一个文档中出现的频率,\(TF\)值越大,区分能力越强
- \(DF\)(document frequency):一个单词在多少文档中出现过,\(DF\)越大,表明这个单词在很多文档中都出现过,区分文档的能力越弱
3.1.1 倒排索引的实现¶
知道了倒排索引的思想之后,其实现就变得非常直观了。我们可以用一个字典来描述一类关系,其主键为单词,键值为这个单词出现的所有位置。
最朴素的版本就是让键值为单词出现过的文档的序号序列,而如果我们还需要知道词汇出现的位置,则可以让键值是一个二元组的序列,其中第一个元素是文档的序号,第二个元素是单词在文档中出现的位置。
例如我们有如下文件集:
文档集
| Doc | Text |
|---|---|
| 1 | Gold silver truck |
| 2 | Shipment of gold damaged in a fire |
| 3 | Delivery of silver arrived in a silver truck |
| 4 | Shipment of gold arrived in a truck |
那么我们可以得到如下的倒排索引:
倒排索引
| No. | Term | Times; (Doc ID: Places) |
|---|---|---|
| 1 | a | {3; (2;6),(3;6),(4;6)} |
| 2 | arrived | {2; (3;4),(4;4)} |
| 3 | damaged | {1; (2;4)} |
| 4 | delivery | {1; (3;1)} |
| 5 | fire | {1; (2;7)} |
| 6 | gold | {3; (1;1),(2;3),(4;3)} |
| 7 | of | {3; (2;2),(3;2),(4;2)} |
| 8 | in | {3; (2;5),(3;5),(4;5)} |
| 9 | shipment | {2; (2;1),(4;1)} |
| 10 | silver | {2; (1;2),(3;3,7)} |
| 11 | truck | {3; (1;3),(3;8),(4;7)} |
前者为Term Dictionary, 后者为 Posting List
所以实际上非常简单,我们只需要扫描文档,然后存下每一个文件在哪里出现过即可。
while(read a document D)
{
while(read a term T in D)
{
if(Find(Dictionary, T) == False)
{
// 碰到新单词
Insert(Dictionary, T);
}
get T's posting list;
// 插入索引
Insert a node to T's posting list;
}
}
Write the inverted index to disk;
3.2 改进¶
那么到此为止了吗?非也。倘若毫无节制的将所有词都存到倒排索引中,那么我们的倒排索引就会变得非常大,其中必然有很多冗余信息存在,所以我们需要对倒排索引进行一些改进。
文件倒排索引建立的过程主要是:
-
从文件中读取词
-
将该词提取为词干(word stemming),即去除第三人称形式、过去式、进行时等形式,留下词干),并去除分词(stop word),即”a”, “is”等没有意义的词。
- 检查该词是否已经在词典之中。
- 若不在,则将该词添加入词典之中。更新索引信息。
- 建立完毕后,将索引文件存入磁盘。
索引信息包括:词语,词语出现的总次数,(文件号,在文件中该词的位置)
example:倒排索引信息实例 
3.2.1 停用词¶
我们观察到,我们存下来的这些内容中,有一些东西频繁地出现在所有文档中,在特定情况下,这些词可能并不会成为一个索引,例如正常的英文文章中的 a,the 等。所以,对于这一类词——我们称之为停用词(stop words),对于停用词,我们就不需要将他们存下了。
question "哪些词会成为停用词?"
一般一个词成为停用词,是因为它无法成为一个有效的检索关键字,它可能是在大量资料中大量出现,导致我们无法利用它找出我们想要的资料。换句话来说,一个共通点是它们通常都有着相当高的出现频率。
3.2.2 词干分析¶
词干分析(word stemming)是一种将单词转换为其词干的技术。例如,词干分析可以将单词 trouble,troubled,troubles,troubling 都转换为 trouble(甚至是 troubl,核心目的是让它们变成同一个单词)。相同词干的词有着类似的含义,在检索 troubled 的时候,当然也可能想找到包含 trouble 的文档。这种技术也可以让多个单词共享同一条索引记录,在存和找的过程中都能优化效果。
不过在具体操作方面,这个东西就显得比较繁杂和暴力了,我们只能根据语法规范进行暴力匹配和判断,这里我们就不展开了。
3.2.3 分布式¶
分块最后merge
BlockCnt = 0;
while ( read a document D )
{
while ( read a term T in D )
{
if ( out of memory )
{
Write BlockIndex[BlockCnt] to disk;
BlockCnt ++;
FreeMemory;
}
if ( Find( Dictionary, T ) == false )
Insert( Dictionary, T );
Get T’s posting list;
Insert a node to T’s posting list;
}
}
for ( i=0; i<BlockCnt; i++ )
Merge( InvertedIndex, BlockIndex[i] );
当倒排索引文件较大时,没有足够的内存,无法存在一台主机上,此时需要倒排索引分布式存储技术。
- 术语区分索引(term-partitioned index)
按照关键词将文件存在于不同的主机上,全局建立索引
- 文档区分索引(Document-partitioned index)
按照文件号将文件存在不同主机上,在每台主机上建立局部索引
而这里有两种分布式的策略,其一是根据单词的字典序进行分布式,其二是根据文档进行分布式。

显然根据单词的内容进行分布式,能够提高索引效率,但是这样的话,我们就需要将所有形式接近的单词都存储在一个地方,这样就会造成单点故障,容灾能力很差,所以这种方式并不是很好。
而第二种办法则有较强的容灾性能。即使一台机器无法工作,也不会剧烈影响到整个系统的工作。
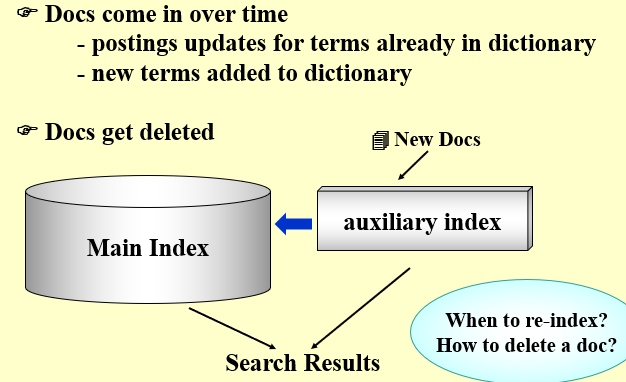
3.2.4 Dynamic indexing 动态索引¶
当前情况,最索引的文档集可能是动态变化的,例如添加新文档、删除现有文档
索引需要定时更新,并建立主索引和辅助索引
解决方法:周期性地对文档集从头开始进行索引重构
- 一个大的主索引,保存在磁盘中,另一个小的辅助索引,用于存储新文档信息,存储在内存中
- 检索时可以同时遍历两个索引,并将结果进行合并
- 文档的删除记录在一个无效位向量,在返回检索结果之前,可以利用它过滤已经删除的文档。
- 每当辅助索引很大时,就将它合并到主索引
3.2.5 compression 索引文件压缩¶
一般来说,对索引文件进行压缩不但可以减小空间,并且可以提高索引效率。这是因为,采用高效的压缩算法,虽然将耗费一定时间在内存中进行解压,但因为能提高cache的利用率,并能提高从磁盘到内存的读取效率,所以总体来说效率将得到提升。
采用差分压缩的方法——$docID$的存储只记录与上一项$docID$的差值来减少$docID$存储长度
posting list 过大,后一项减去前一项

3.2.6 Threshold 阈值¶

仅检索文档按权重排名的前 X 个文档
- 会因为截断而错过一些相关文档
对搜索关键词进行排序
- 按查询词的频率按升序对查询词进行排序;仅根据原始查询词的一定百分比进行搜索
3.3 性能评估¶

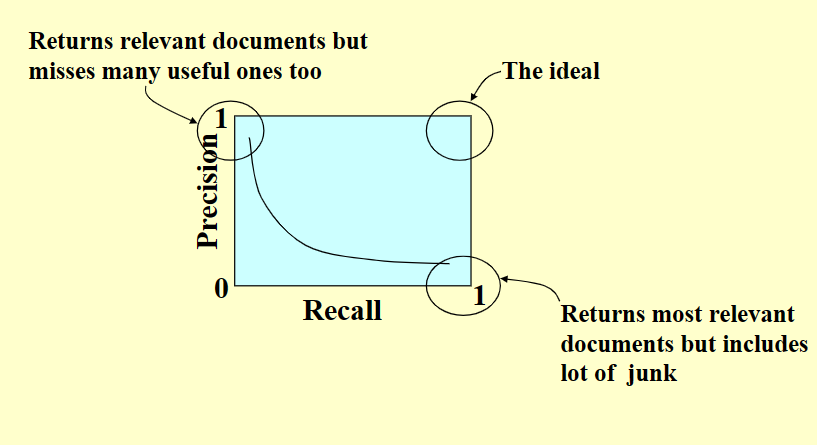
衡量与评价文件倒排索引系统的性能:
区分Data Retrieval 和Information Retrieval;

主要从精确度(Precision)与召回度(Recall)进行衡量。
-
精度高:返回相关文档,但也遗漏了许多有用的文档
-
精度低:返回最相关的文档,但是包含了很多垃圾
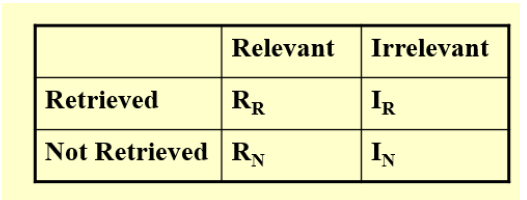
Retrieved 召回的 Relevant 相关的
相关的,召回的部分:\(R_R\)
相关的,未召回的部分:\(R_N\)
不相关的,召回的部分:\(I_R\)
不相关的,未召回的部分:\(I_N\)
精确度precision 表示所有召回的部分里面,相关的所占的比重。
$$
precision P = R_R / (R_R + I_R)
$$
召回度recall表示所有相关的部分中召回的所占的比重
$$
recall R = R_R / (R_R + R_N)
$$
3.4 习题训练¶
In distributed indexing, document-partitioned strategy is to store on each node all the documents that contain the terms in a certain range.
False : 这是 term-partitioned 策略
因为分布式索引的方式是按文档序号排序的,如果按包含的terms分类,在储存故障时,关于这个terms的文档(in a certain range)全没了,不抗风险。
When evaluating the performance of data retrieval, it is important to measure the relevancy of the answer set.
- False : 召回率和整个答案集的相关性无关。
- 这个说的是data retrieval,错。Information retrieval才需要measure the relevancy of the answer set。

- data 数据更为宽泛,评价指标是 响应时间和索引范围
- information 可以理解为经过筛选后的信息,细化,测量答案集的相关度
1. Precision is more important than recall when evaluating the explosive detection in airport security.
- False: 安全之上.机场安全,应该是返回的全面度更重要,精确性不算重要
2. While accessing a term by hashing in an inverted file index, range searches are expensive.
- True,这个是和B+树比的,对
3. 【习题】While accessing a term, hashing is faster than search trees.
- 答:True,因为hash表是直接使用hash函数定位的时间是常数的,而使用搜索树则是O(logn)的。但是hash表的储存不灵活有缺点。

-
精度高:返回相关文档,但也遗漏了许多有用的文档
-
精度低:返回最相关的文档,但是包含了很多垃圾

召回率是相关的部分中,召回的占比
准确率是召回的部分中,准确的占比
\(recall=4000/(4000+8000)=33%\)