2. Instructions: Language of the Computer¶
约 5184 个字 66 行代码 预计阅读时间 27 分钟
2.1 Introduction¶
Abstract
-
Language of the machine
- Instructions (Statement)
- Instruction Set (Syntax)
-
Design goal
-
Maximize performance
同样资源的情况下性能大
-
Minimize cost
同样性能的情况下成本低
-
Reduce design time
指令集简单,易于理解
-
-
我们使用的是 RISC-V 架构
Instruction Characteristics

指令集基本的结构:Operation 操作; Operand 操作数
- 不同指令集,指令的编码可以不同。如 000 表示加法,这也叫指令的 Encoding.
- 操作数位宽可以不同,可以是立即数/寄存器/内存。
通用存储器:
- register-register
- memory-register
2.2 Operation¶
-
Every computer must be able to perform arithmetic.
- Only one operation per instruction
- Exactly 3 variables e.g.
add a, b, c即 \(a\leftarrow b+c\)
注意结果放在第一个位置,这样易于解码
-
Design Principle 1 - Simplicity favors regularity. (简单源自规整,指令包含三个操作数)
-
C code
f = (g + h) - (i + j); -
RISC-V code
add t0, g, h add t1, i, j sub f, t0, t1
-
2.3 Operands of the Computer Hardware¶
2.3.1 Register Operands¶
-
Arithmetic instructions use register operands.
-
RISC-V has a \(32\times 64\)-bit register file
- Use for frequently accessed data
32-bit data is called a **word**. 64-bit is called a double word.- we call them
x0tox31
-
Design Principle 2 - Smaller is faster.
寄存器不是越多越好,多了之后访问慢。
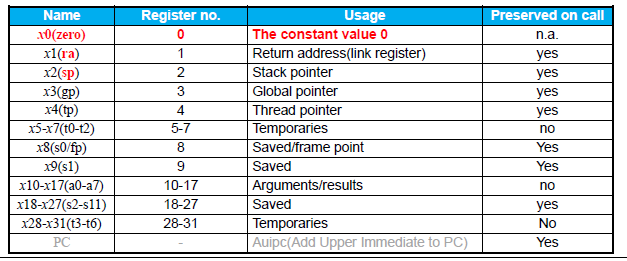
Name Register Name Usage Preserved on call? x0 0 The constant value 0 n.a. x1(ra) 1 Return address(link register) yes x2(sp) 2 Stack pointer yes x3(gp) 3 Global pointer yes x4(tp) 4 Thread pointer yes x5-x7 5-7 Temporaries no x8-x9 8-9 Saved yes x10-x17 10-17 Arguments/results no x18-x27 18-27 Saved yes x28-x31 28-31 Temporaries no "为什么寄存器
x0一直为 0 ? "Make the common fast. 因为经常有 0 参与计算,将其存在一个寄存器中,便于计算。
preserved on call 表示在使用之前需要保存原先数值
x8-x9 saved:用之前有数据,需要先将数据存入stack,运算结束之后,恢复原先的数据
x10-x17 argument/result:传递结果
2.3.2 Memory Operands¶
-
Data transfer instructions
Load: Load values from memory to register; load doubleword(ld)Store: Store result from register to memory; store doubleword(sd)
只有load和store指令能够访问内存 -
Memory is byte addressed. 字节寻址
RISC-V architecture 的地址是 64 位的,地址为字节地址,因此总共可以寻址 $2^{64} $个字节,即 \(2^{61}\) 个 double word
-
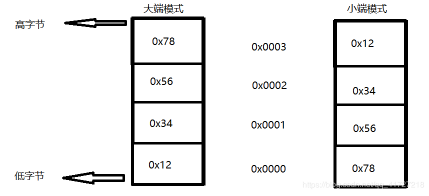
RISC-V is Little Endian
Example "Little vs Big Endian"
- 小端:数据的高字节(most significant bit)存放在高地址;数据的低字节(least significant bit)存放在低地址
- 大端相反
eg: 32位机器上存放 0x12345678 ,大小端模式存储如下:
-
RISC-V dose not require words to be aligned in memory
RISC-V 不要求内存对齐- words align: 一个字是 4 字节,我们要求字的起始地址一定要是 4 的倍数。
"Memory Alignment"
 第一个是对齐的,第二个是不对齐的。
第一个是对齐的,第二个是不对齐的。- 不对齐的好处是省空间, 缺点是有的变量无法一次性取出
Example "Memory Operand Example"
A[12] = h + A[8];
(默认数组是双字的, h in x21, base address of A in x22)
翻译为 RISC-V 代码得到
ld x9, 64(x22) // temporary register x9 get A[8]
add x9, x21, x9
sd x9, 96(x22) // store
地址是以 byte 为单位,所以要偏移 \(8\times 8=64\) bytes.
load 和 store 是唯二可以访问存储器的指令。

先计算偏移量,\(8 \times i\), 可以对\(i\)直接左移三位
2.3.3 Registers vs. Memory¶
-
Registers are faster to access than memory 寄存器更快
-
Operating on memory data requires loads and stores
对内存的操作需要store和load指令()唯二能够访问内存
-
Compiler must use registers for variables as much as possible
编译器尽量使用寄存器存变量。只有在寄存器不够用时,才会把不太用的值放回内存。
2.3.4 Constant or Immediate Operands¶
Immediate: Other method for adding constant
-
Avoids the load instruction
-
Offer versions of the instruction
e.g.
addi x22, x22, 4 -
Design Principle 3 - Make the common case fast. -
为什么内存是 \(2^{61}\) 个 doublewords?
可以表示的地址有这么多,因为我们以 64 位寄存器为基址,可以表示的双字就是 \(2^{64}/2^3=2^{61}\) (这里 \(2^3\) 表示 8 个字节,即双字). 即我们的
load指令可以访问的范围有这么大。
2.4 Signed and Unsigned Number¶





2.5 Representing Instructions in the Computer¶
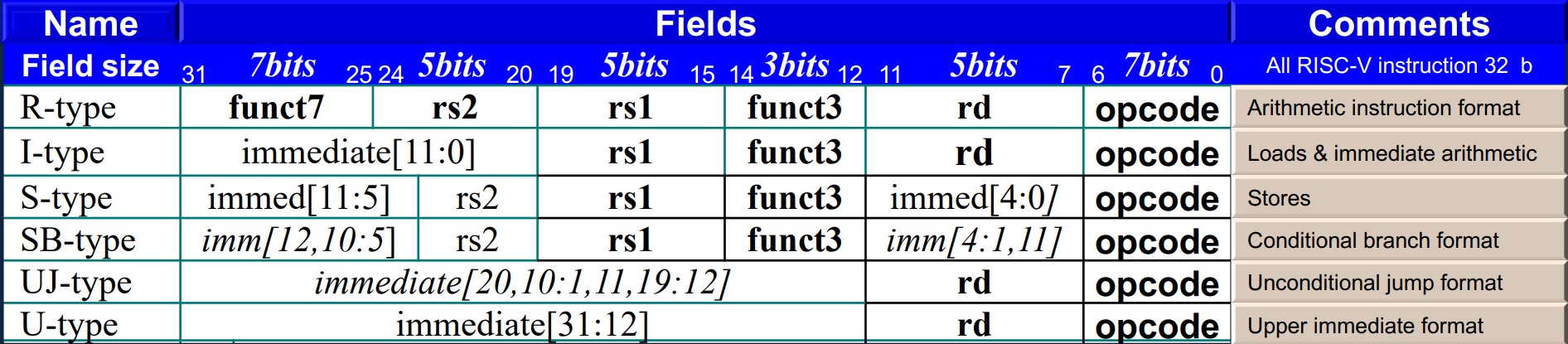
-
All information in computer consists of binary bits.
-
Instructions are encoded in binary called machine code (机器码)
-
Mapping registers into numbers
0 for register
x0, 31 for registerx31. e.t.c. -
RISC-V instructions
32 位指令编码。所有指令都是规则化的,即一部分是 opcode, 一部分是 operands 等等。

从右往左依次是: opcode rd fun3 rs1 rs2 fun7寄存器从右往左看 9 -> 20 -> 21
"Summary of RISC-V architecture"
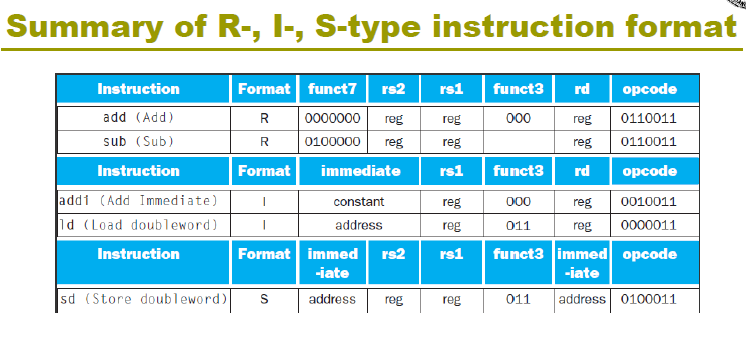
2.5.1 R-format¶

- opcode: operaion code
- rd: destination register number
- funct3: 3-bit function code(additional opcode) **
例如,我们加法减法可以做成一个 opcode, 然后利用 funct3 进行选择。** - rs1/rs2: the first/second source register number
- funct7: 7-bit function code(additional opcode)
All instructions in RISC-V have the same length
Design Principle 4 - Good design demands good compromises
2.5.2 I-format¶
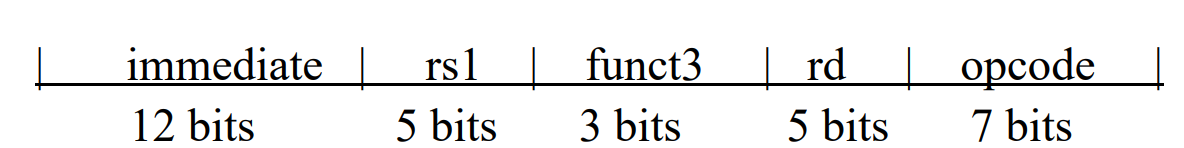
-
Immediate arithmetic and load instructions
e.g.addi,ld -
rs1: source or base address register number
-
immediate: constant operand, or offset added to base address
将 rs2, funct7 合并了,得到 12 位立即数
2.5.3 S-format¶

-
rs1: base address register number
-
rs2: source opearand register number
这边特别注意一下基址寄存器和源寄存器的位置,从右往左:opcode,基址寄存器,源寄存器

-
immediate: Split so that rs1 and rs2 fields always in the same place.
-
不再需要rd,rd被imm[4:0]取代,前者为imm[11:5] 为7 bits
\(S\_imm = {{20{inst[31]}}, inst[31:25], inst[11:7]}\)
A[30] = h + A[30] + 1
h 在 x21
base address of A is x10
ld x9, 240(x10) // temporary reg x9 gets A[30]
add x9, x21,x9 // temporary reg x9 gets h + A[30]
addi x9, x9, 1 // temporary reg x9 gets h + A[30] + 1
sd x9, 240(x10) // stores h + A[30] + 1 back into A[30]

\(240 = 7 \times 32 + 16 = 0000111 \_ 10000_2\)
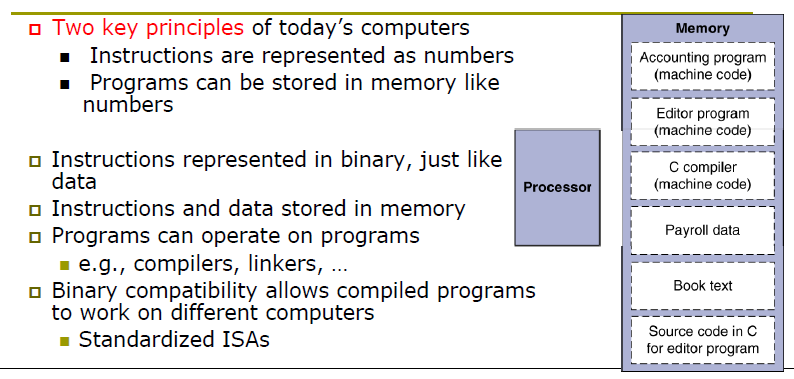
Stored-Program
-
Instructions represented in binary, like data.
-
Instructions and data stored in memory.
指令和数据存储在内存中
-
Programs can operate on programs. e.g. compiplers, linkers.
程序可以对程序进行操作。例如,编译器、链接器。
-
Binary compatibility allows compiled programs to work on different computers
二进制兼容性允许编译的程序在不同的计算机上工作
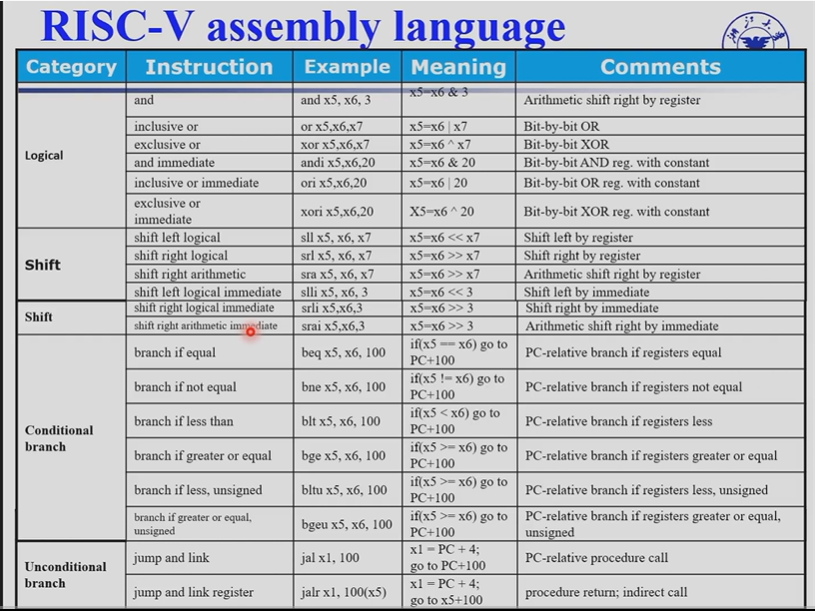
2.6 Logical Operations¶
逻辑移位不管符号位,全部添加0.算数移位添加符号位
| Operation | C | Java | RISC-V |
|---|---|---|---|
| Shift left | << | << | slli |
| Shift right | >> | >>> | srli |
| Bit-by-bit AND | & | & | and, andi |
| Bit-by-bit OR | | | | | or, ori |
| Bit-by-bit XOR | ^ | ^ | xor, xori |
| Bit-by-bit NOT | ~ | ~ | - |
bitwise NOT 要用异或实现(与全 F 异或)
2.6.1 Shift¶

-
I 型指令(immediate)
-
为什么还有
funct6?寄存器本身也就64位,不需要移位超过64次,所以6bit就能实现\(2^6-1 = 63\)次移位操作,移动64位,相当于直接置为0
-
左移 i 位相当于乘 \(2^i\), 右移 i 位相当于除 \(2^i\).
对于sll,
sll rd, rs1, rs2,移动的位数存放在rs2,被移动的数存放在rs1,结果存放在rd
2.6.2 AND¶

Select some bits, clear others to 0
It is bit-by-bit (bitwise-AND)
- Result=1 : both bits of the operands are 1
2.6.3 OR¶

Set some bits to 1, leave others unchanged
2.6.4 XOR¶

Set some bits to 1, leave others unchanged
2.7 Instructions for making decisions¶
2.7.1 Branc instructions¶
-
beq reg1, reg2, Label相等则跳转
-
bne reg1, reg2, Label不相等则跳转
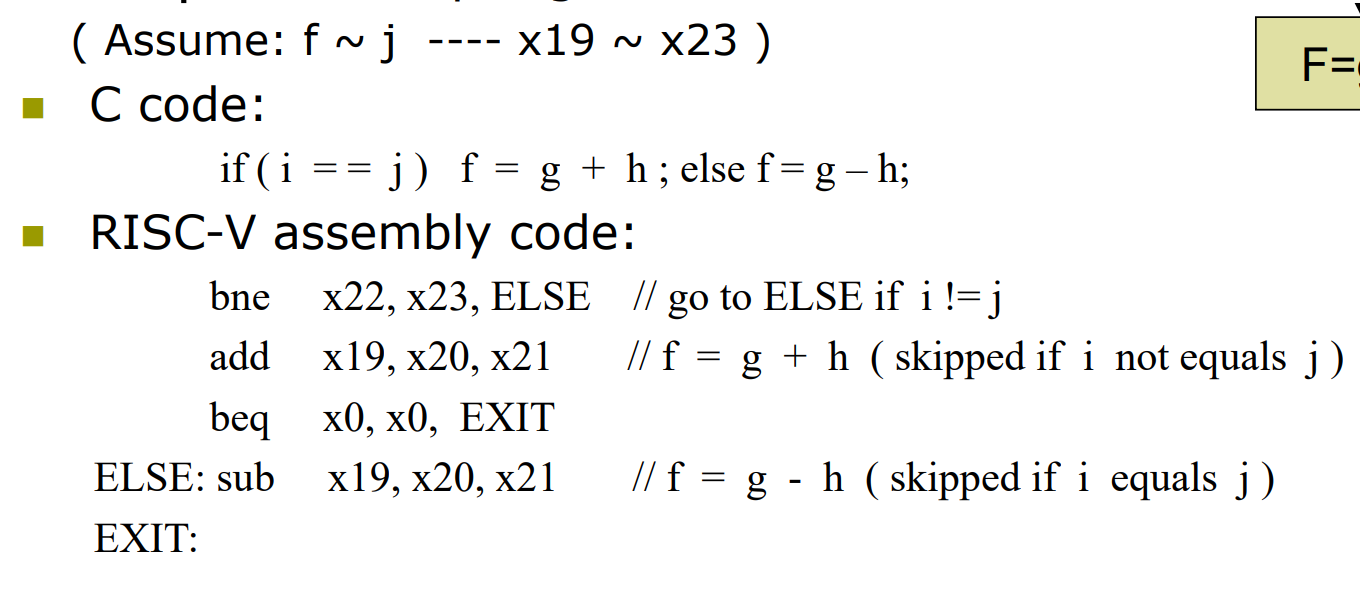
sd x9, 240(x10) // stores h + A[30] + 1 back into A[30]
store 的立即数是作为数据的地址, beq 的立即数是作为运算的地址(加到 PC 上)因此二者的指令类型不同。
跳转的范围有限制,因为立即数只有 12 位。(PC 相对寻址,以当前程序位置为基准前后跳)

i 存放在 x22, k 存放在 x24, save{]数组基地址存放在 x25
add x10, x10, x25计算的是数组元素的地址,还不是数组元素的值
所以还需要load指令将值取出来放置在临时寄存器x9中

blt: branch less than
bge: branch greater equal
-
blt rs1, rs2, L1若
rs1<rs2则跳到 L1 -
bge rs1, rs2, L1若
rs1>=rs2则跳到 L1
2.7.2 slt instruction¶
set on if less than.
slt x2, x3, x4 # x2=1 if x3 < x4
R 型指令
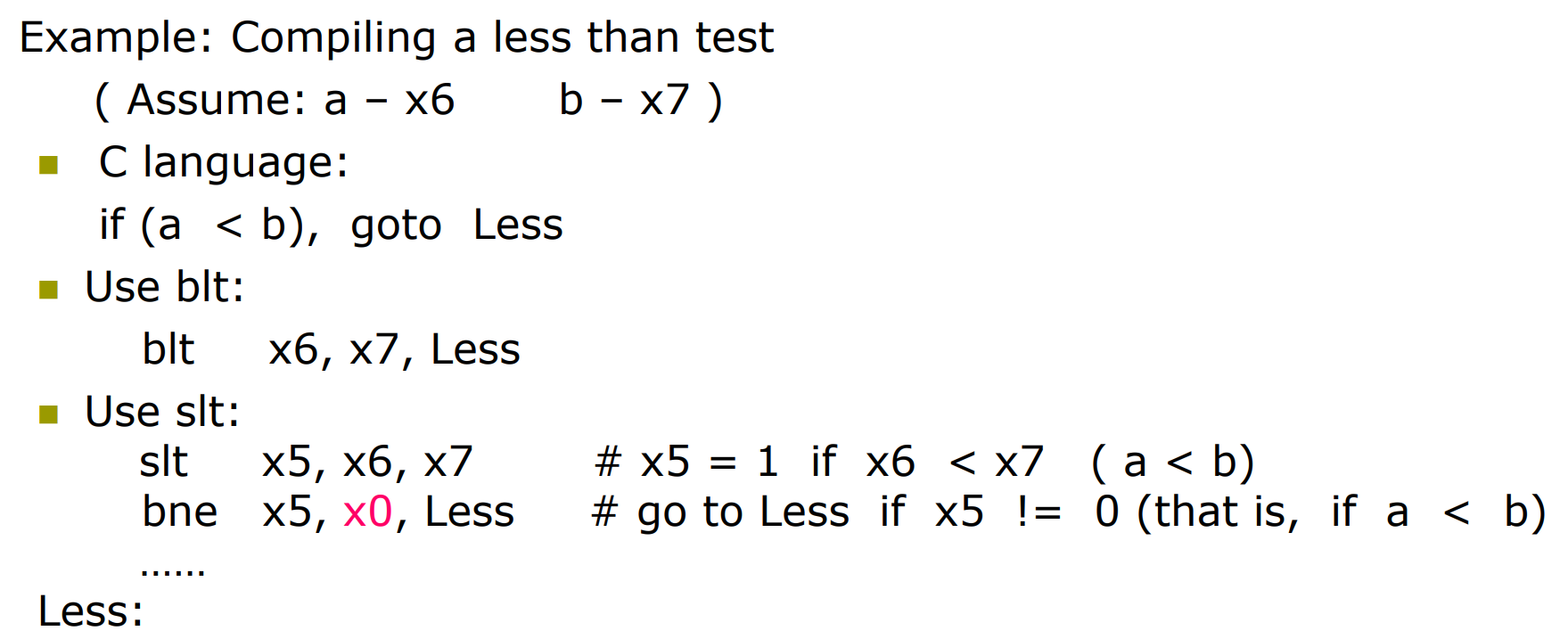
可以用 slt + bne 实现 blt的功能
2.7.3 Signed vs. Unsigned¶
默认是有符号数进行比较
- Signed comparison:
blt,bge - Unsigned comparison:
bltu,bgeu
set on less than immediate
slti :Set on less than immediate
sltiu :Set on less than unsigned immediate
与立即数immediate进行比较

边界检查:
关于使用bgeu同时实现 x20>=x11 & x20 < 0
-
bgeu x20, x21, IndexOutofBound根据题目的要求,\(x20 < 0 \ \& \ x20 >= x11\)说明\(x11,x20\)都是负数,那么此时的比较,完全可以转化为无符号数 -
对于无符号数111….111最大,转化为有符号数也是最大
无符号数从100000开始递增,有符号数也是从100000开始递增
这也就说明无符号数的大小关系可以迁移到有符号数
2.7.4 Case/Switch¶



\(x_6\) 是跳转表的基地址,\(x_7\leftarrow x_6+8*k\)
\(x7\)存放的是具体跳转的指令块的地址
jalr x1, 0(x7) I 型指令 把下一条指令的地址 PC+4放入x1寄存器,随后跳向[x7] + 0的地方。
执行完jalr之后,能够根据 x1保存的PC+4返回到主程序
这里我们 jalr x0, 0(x1) 因为我们不能改变 x0寄存器,所以这里仅用作占位,并没有实际存储返回地址。
2.8 Supporting Procedures in Computer Hardware¶
Procedure/function --- be used to structure programs
为了完成特定任务。易于理解,可以复用。
调用函数的步骤
-
Place Parameters in a place where the procedure can access them (in registers
x10~x17)将参数放在过程可以访问它们的位置(在寄
x10~x17存器中) -
Transfer control to the procedure
将控制权转移到子程序上
-
Acquire the storage resources needed for the procedure
获取过程所需的存储资源
-
Perform the desired task
-
Place the result value in a place where the calling program can access it
将结果值放在调用程序可以访问它的位置
x10~x17 -
Return control to the point of origin (address in
x1)将控制权返回到原先的主程序(地址在
x1)
2.8.1 Procedure Call Instructions¶
-
Procedure call: jump and link
jal x1, ProcedureLabel-
Address of following instruction put in
x1将下一条指令存放到x1,也就是PC+4
-
Jumps to target address
-
-
Procedure return: jump and link register
jalr x0, 0(x1)-
Like jal, but jumps to
0 + address in x1像 jal 一样,但跳到
0 + address in x1 -
Use
x0as rd (x0cannot be changed)x0在此处相当于占位符,并不能发生更改
-
Can also be used for computed jump
-
不能用 jal 跳回来,跳进函数的地址的是固定的, Label 一定。但是跳回来的地址不一定,要用 x1 存储才能跳回。
jal 和 jalr的区别在于:
有没有使用寄存器来协助跳转到procedural。且两者跳转的范围不同,前者依靠立即数imm,后者依靠寄存器和imm调整大小
2.8.2 Using More Registers¶
-
Registers for procedure calling
-
x10~x17(a0~a7): eight argument registers to pass parameters or return values8 个参数寄存器,用于传递参数或返回值(进入函数时,传参;函数结束,返回结果)
-
x1: one return address register to return to origin point一个返回地址寄存器,用于返回原先的主程序
-
-
Stack:Ideal data structure for spilling registers
- Push, pop
- Stack pointer (
sp):x2指向栈顶,即最后一个有效数据所在的位置
-
Stack grow from higher address to lower address
堆栈从较高地址增长到较低地址
- Push:
sp = sp - 8向下移 - Pop:
sp = sp + 8向上移


- Push:
-
进行栈指针减24,相当于push三次
- 执行完成目标操作之后,按照镜像顺序,依次恢复x20,x6,x5.最后恢复栈指针
- 跳转回主程序
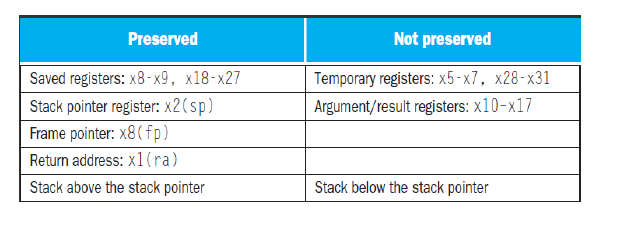
| Name | Register Name | Usage | Preserved or call? |
|---|---|---|---|
| x0(zero) | 0 | The constant value 0 | n.a. |
| x1(ra) | 1 | Return address(link register) | yes |
| x2(sp) | 2 | Stack pointer | yes |
| x3(gp) | 3 | Global pointer | yes |
| x4(tp) | 4 | Thread pointer | yes |
| x5-x7(t0-t2) | 5-7 | Temporaries | no |
| x8(s0/fp) | 8 | Saved/frame pointer | yes |
| x9(s1) | 9 | Saved | yes |
| x10-x17(a0-a7) | 10-17 | Arguments/results | no |
| x18-x27(s2-s11) | 18-27 | Saved | yes |
| x28-x31(t3-t6) | 28-31 | Temporaries | no |
| PC | - | Auipc(Add Upper Immediate to PC) | yes |
-
t0~t6临时寄存器,不需要在函数中保存 -
s0~s11saved registers
标有 Preserved 表明我们需要在函数开始时保存该寄存器的值,并在离开函数前恢复寄存器的值。

2.8.3 Nested Procedure¶
non-leaf procedure :在procedure中调用procedure
eg: nested procedure 递归
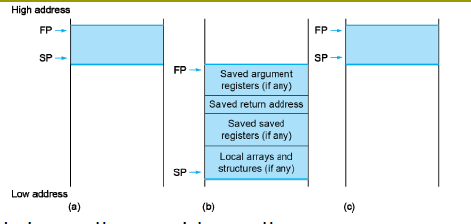


-
先对栈指针进行操作,push两个数,sp -16,一个是返回的地址x1,一个是参数n
-
执行x5 = x10 - 1 = n - 1操作之后,要判断n是否小于1,反过来只需要判断x5是否大于等于0
-
如果x5 = 0的话,此时n=1,就直接返回1,恢复栈指针,跳转回主程序。
否则,进入递归调用
对于递归程序L1:
- 先计算 x10 = x10 - 1,如此便能够计算fact(n-1)
- 计算完成后,由于原先的n值通过x10被压入栈中,我们先用x6承接fact(n-1),再利用x10取出n,最后计算n * frac(n-1)
- 最后跳转回到主程序
在过程调用中保留内容:寄存器(saved)、堆栈指针寄存器( sp )、返回地址寄存器( x1 ),堆栈指针上方的堆栈
在过程调用中未保留内容,临时寄存器、参数寄存器(x10~x17)、返回值寄存器( x10 ~ x17),堆栈指针下方
Local Data on the Stack
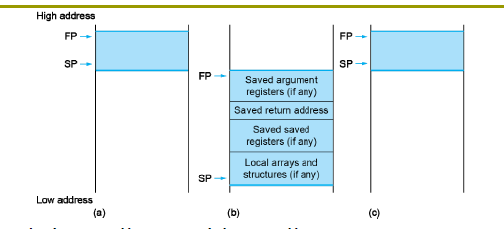
Procedure frame and frame pointer ( x8 or fp )
Global pointer ( x3 or gp )
一旦调用procedure,fp就会出现当前procedure的栈顶(以fp为基准相对寻址)
在过程调用中用到的指针(例如存放过程的数组)双重作用,sp不停的push和pop,fp仅仅在需要使用过程中的变量时移动(以fp为基址,相对访问)

编译完成之后的程序结果
- text: 程序代码
- 栈:自动分配,从上往下
- 堆heap:动态分配,从下往上

2.9 Communicating with People¶
-
Byte-encoded character sets
e.g. ASCII, Latin-1
-
Unicode: 32-bit character set
e.g. UTF-8, UTF-16
编码中有不同长度的数据,因此也需要有不同长度的 load 和 store.
-
Load byte/halfword/word:
Sign extendto 64 bits in rd
加载字节/半字/字:符号扩展到 rd 中的 64 位
* `lb rd, offset(rs1)`
* `lh rd, offset(rs1)`
* `lw rd, offset(rs1)`
* `ld rd, offset(rs1)`
同样是取 A[4] 的值,不同的数据类型 offset 不同。
char为 4,short int为 8,int为 16.
-
Load byte/halfword/word unsigned:
0 extendto 64 bits in rd加载字节/半字/字无符号:0 扩展到 rd 中的 64 位
lbu rd, offset(rs1)lhu rd, offset(rs1)lwu rd, offset(rs1)
-
Store byte/halfword/word: Store rightmost 8/16/32 bits
存储字节/半字/字:存储最右边的 8/16/32 位
-
sb rs2, offset(rs1) -
sh rs2, offset(rs1) -
sw rs2, offset(rs1)存储就不需要考虑扩充问题,我们不做运算,只是把对应部分放到对应位置。offset 可以是 3. 因为 RISC-V 是可以不对齐的。(实际上 sh offset 一般是 2 的倍数, sw 是 4 的倍数)
-
字符串


i 不应该分配给 s19, 分配给一个临时寄存器,就可以不用堆栈保存 s19 了。
对于一个 leaf procedure(不再调用其他 procedure) 编译器要尽可能用完所有的临时寄存器,再去用其他的寄存器。
为什么强调 leaf procedure? - 因为对于非 leaf 的函数,可能临时变量会被调用后的函数改变,这样就不能继续用了。
2.10 RISC-V Addressing for 32-Bit Immediate and Addresses¶
2.10.1 Wide Bit Immediate addressing¶
如何将一个寄存器初始化为一个任意的立即数。
lui rd, constant 可以把 20 位的常数放到寄存器中。(U-type)


注意这里,我们会把立即数放入寄存器rd的 [31:12] 位,低位会填充为 0.
Example "Loading a 32-bit constant"

我们最终想放入寄存器的值是 32 位常数 0x003D0. 先利用 lui 将高 20 位 976 放入寄存器中,随后利用加法指令加上 低 12 位,即 2304.
但是此处存在问题, addi存在符号扩充,对于负数会前置加1,导致加法影响最终结果
可以使用OR或者XOR,前面填充0 ori s3, s3, 2304
或者新的方法:
在已知加一个负数的情况下,需要一个数来对冲addi时的FFFFF…, 所以我们可以在lui操作的时候额外加上一个1,此时 00001000+FFFFF000 = 1_0000_0000,也就不会产生影响了
2.10.2 Branch Addressing¶
SB-type

func3用于区分跳转指令的跳转条件
-
PC-relative addressing
\(Target\ address = PC + Branch\ offset = PC + immediate \times 2\)
由于此处没有imm[0],默认最低位为0,所以offset = immediate x 2,相当于向左移动一位
跳转的范围: 12bit -> \(+-2^{12}\)byte 理解为有符号数,第一位符号位,后续12位表示范围\(2^{12}\)
2.10.3 Jump Addressing¶
UJ-type(只有
jal指令),Jalr指令是I型指令
可以观察到, 存在imm[20]作为符号位,imm[0]不存在,默认为0
20-bit immediate for larger range, 低位默认补 0, 故实际表示立即数为 [20:0] 共 21 位。
\(Target\ address = PC + Branch\ offset = PC + immediate \times 2\)
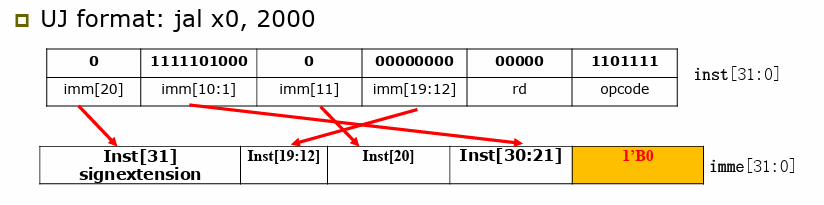
imm[20] 表示符号位 ,跳转范围: \(20bits ->2^{20}bytes = 1M\)
跳转范围最大的是 Jalr,(jalr x1, 0(x5)), 在寄存器x5中存放地址。I型指令


RISC-V 直接用 PC 算 offset, 而非 PC+4.
观赏上表,会发现rd/offset部分是01100,此处大有玄机,分别对应imm[4:1], imm[11]
bne指令的offset 是 0 0 000000 0110_0, 也就是 6 * 2 = 12
beq指令的offset 是 1 1 111111 0110_0, 也就是 -10 * 2 = -20

- All RISC-V instructions are 4 bytes long RISC-V 指令占4个字节
-
PC-relative addressing refers to the number of halfwords 采用PC相对寻址
While branch target is far away
-
Inserts an unconditional jump to target
无条件跳转语句 jal 能比 branch语句 跳转的范围更广,jal的imm有20位
Invert the condition so that the branch decides whether to skip the jump.
Example "Branching far away"

2.10.4 RISC-V Addressing Summary¶
寻址方式是指令集的核心区别。
- 立即数寻址
addi x5, x6, 4 - 寄存器寻址
add x5, x6, x7 - 基址寻址
ld x5,100(x6) - PC 相对寻址
beq x5,x6,L1
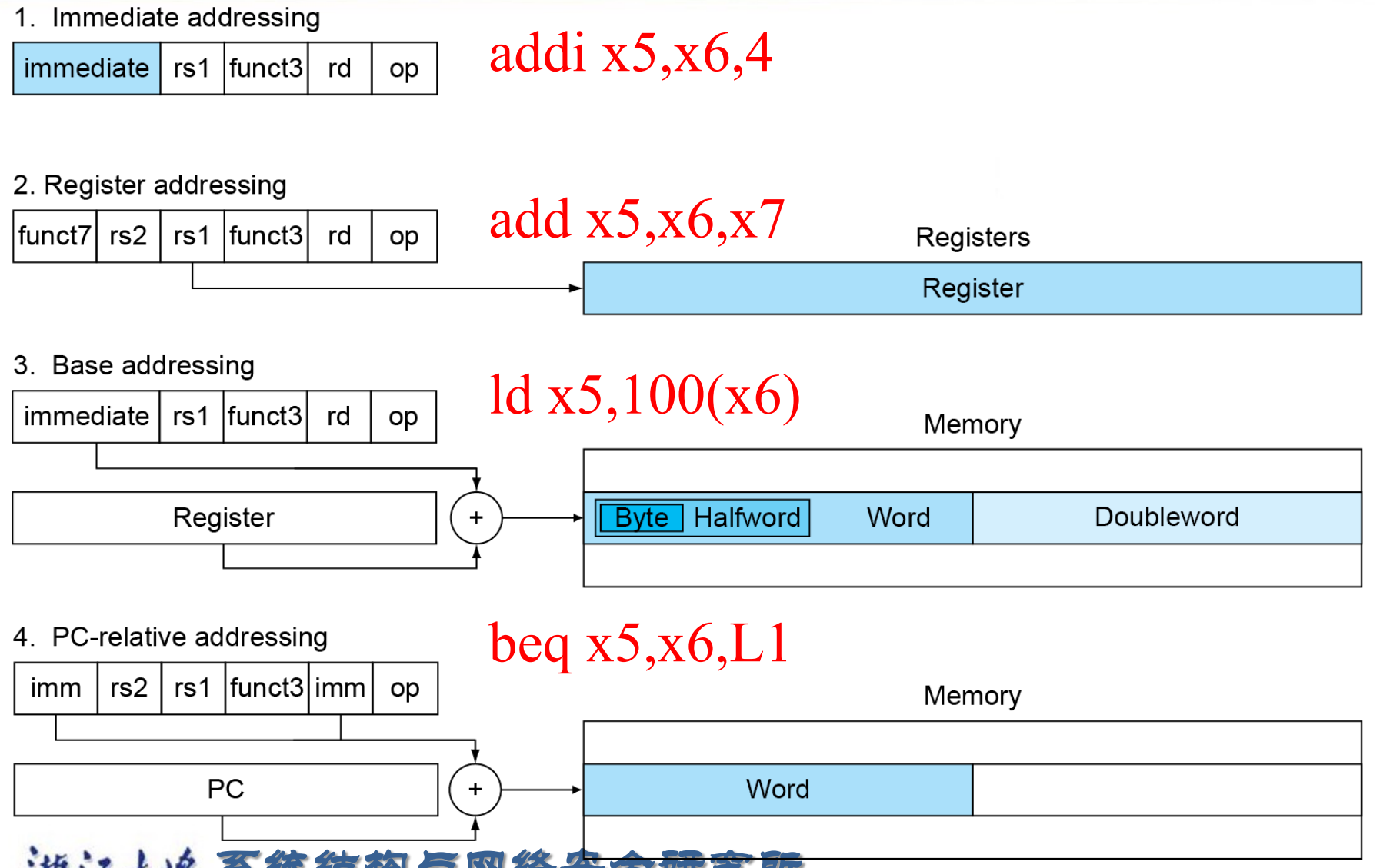
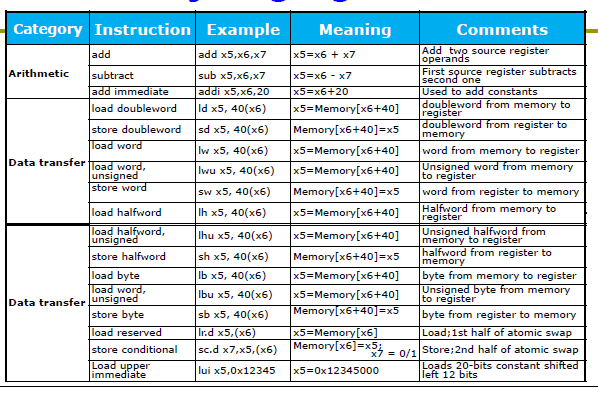

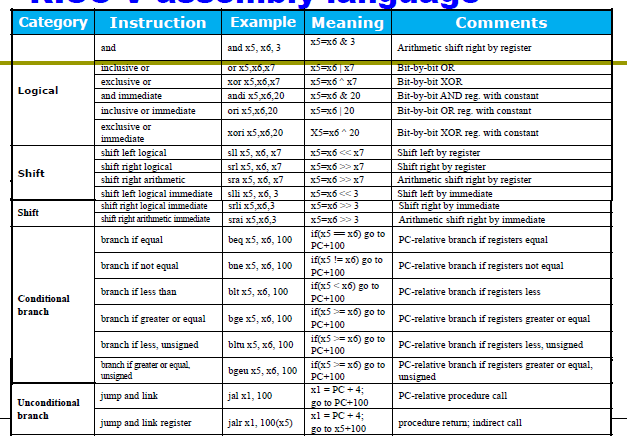
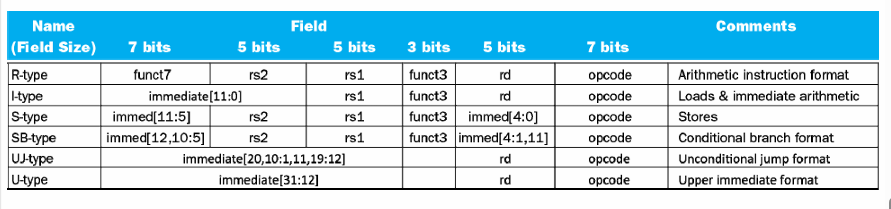
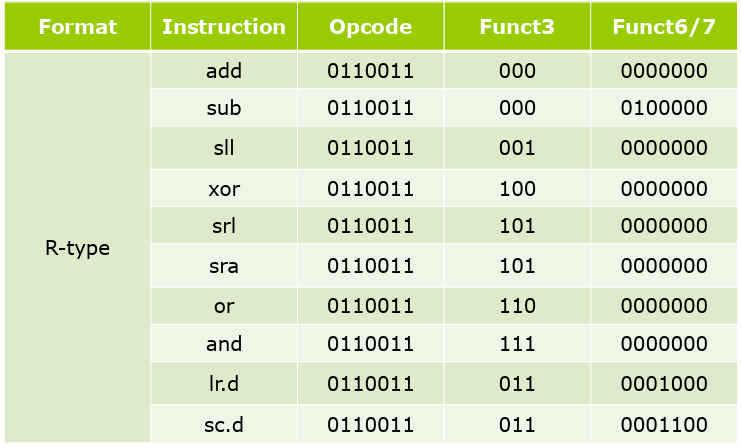

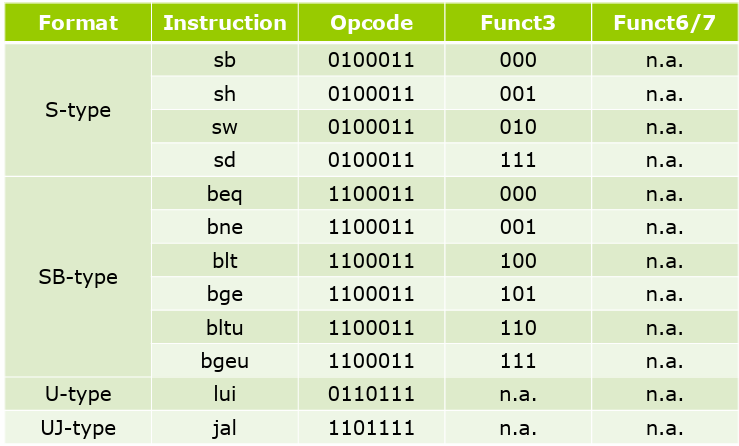
把机器码翻译为汇编指令。
-
opcode
先看 opcode, 确定是哪类指令,随后就可以进行具体划分了。
-
fun3和fun7
再看fun3和fun7,决定具体的指令职能

2.11 Synchronization in RISC-V¶
-
Two processors sharing an area of memory 两个处理器共享一个内存区域
- P1 writes, then P2 reads P1写入,然后P2读取
- Data race if P1 and P2 don’t synchronize 如果 P1 和 P2 不同步,则发生数据争用
- Result depends of order of accesses 结果取决于访问顺序
-
Hardware support required
Atomic read/write memory operation 原子读/写内存操作- No other access to the location allowed between the read and write 读和写之间不允许对该位置进行其他访问
-
Could be a single instruction
-
e.g. atomic swap* of register ↔ memory
寄存器↔存储器的原子交换*
-
Or an atomic pair of instructions
或一对原子指令
-

Load reserved: lr.d rd,(rs1)
把地址 rs1 的值放到寄存器 rd 中
Store conditional: sc.d rd,(rs1),rs2
把寄存器 rs2 的值放入地址 rs1. 如果成功那么 rd 里面是 0. 如果上条指令 load 后,这个地方的值被改变了,那么就失败了,返回 0.
Example "atomic swap"

-
将x20对应地址的值存入x10,x10 = memory[x20]
-
将x23的值放到x20对应的地址, x11表示状态是否store成果,memory[x20] = x23
-
如果x11 等于 0, 说明此时 store 成功, 执行下一条语句,x23 = x10
总体实现,memory[x20]与x23值的交换 -
如果x11 不等于0, 则这个地方的值发生了更改,重新返回lr.d
Example "lock"

- 第一步实现 \(x12 = x0 + 1 = 1\)
- x10 = memory[x20]
- 判断 x10 是否为0,如果不为0,表示当前memory[x20]处存放着数据,有锁的存在,不能store
- 如果x10 = 0,表示当前的锁是free的状态,能够进行store, x12 = memory[x20],用x11表示store的状态
- 如果x11 = 0表示store失败,重新会again。如果x11 = 1表示store成功
- 解锁只需要x20对应地址存放的数据为0
地址 x20 放的是锁,如果锁为 0, 说明我们现在可以存入数据,则我们获得锁随后存入,并释放锁(将锁的值置为0)。否则需要等锁释放了才能存。
2.12 Translating and starting a program¶
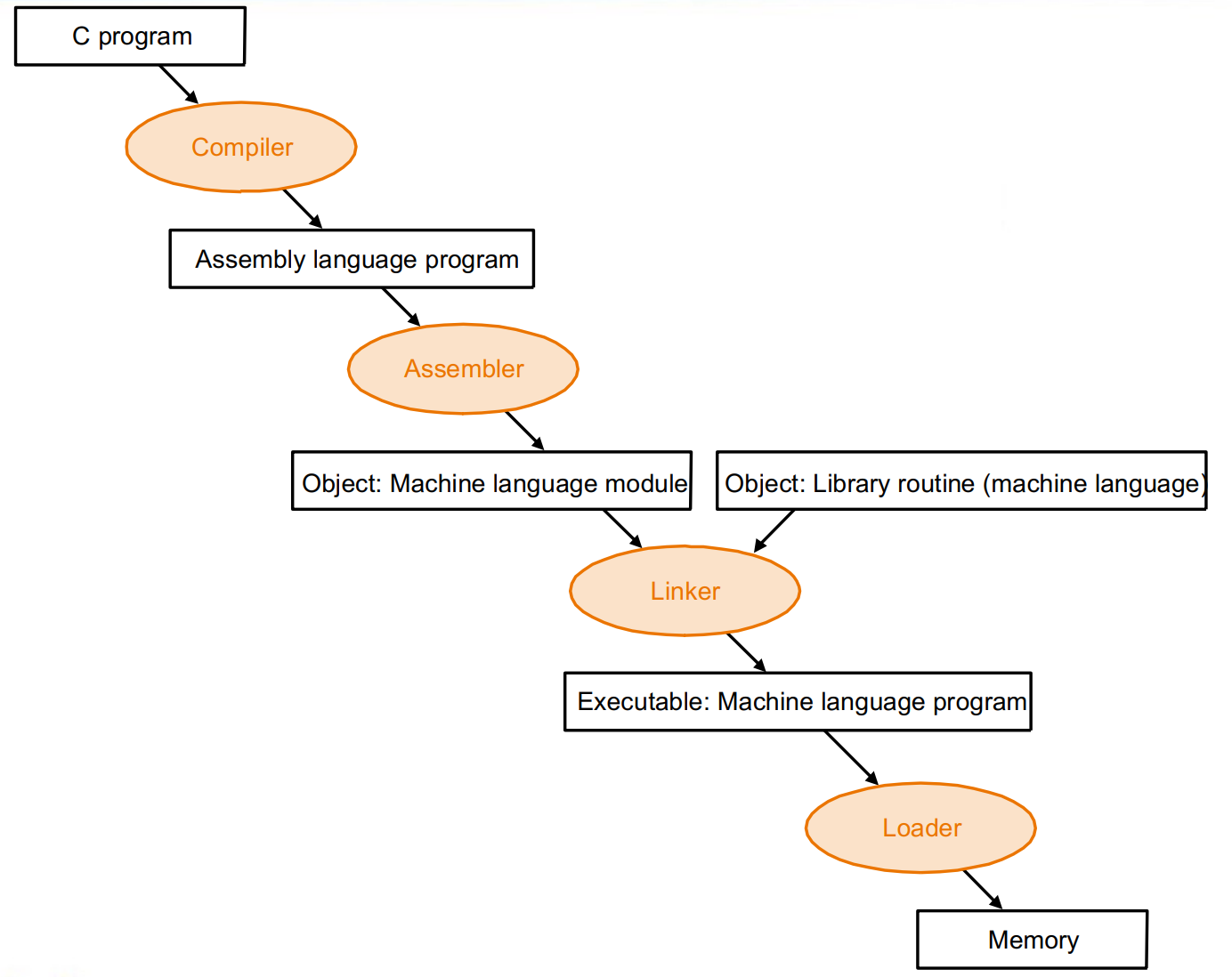
Linker 可以用于连接库函数,多文件编程
Producing an Object Module
Provides information for building a complete program from the pieces(Header).
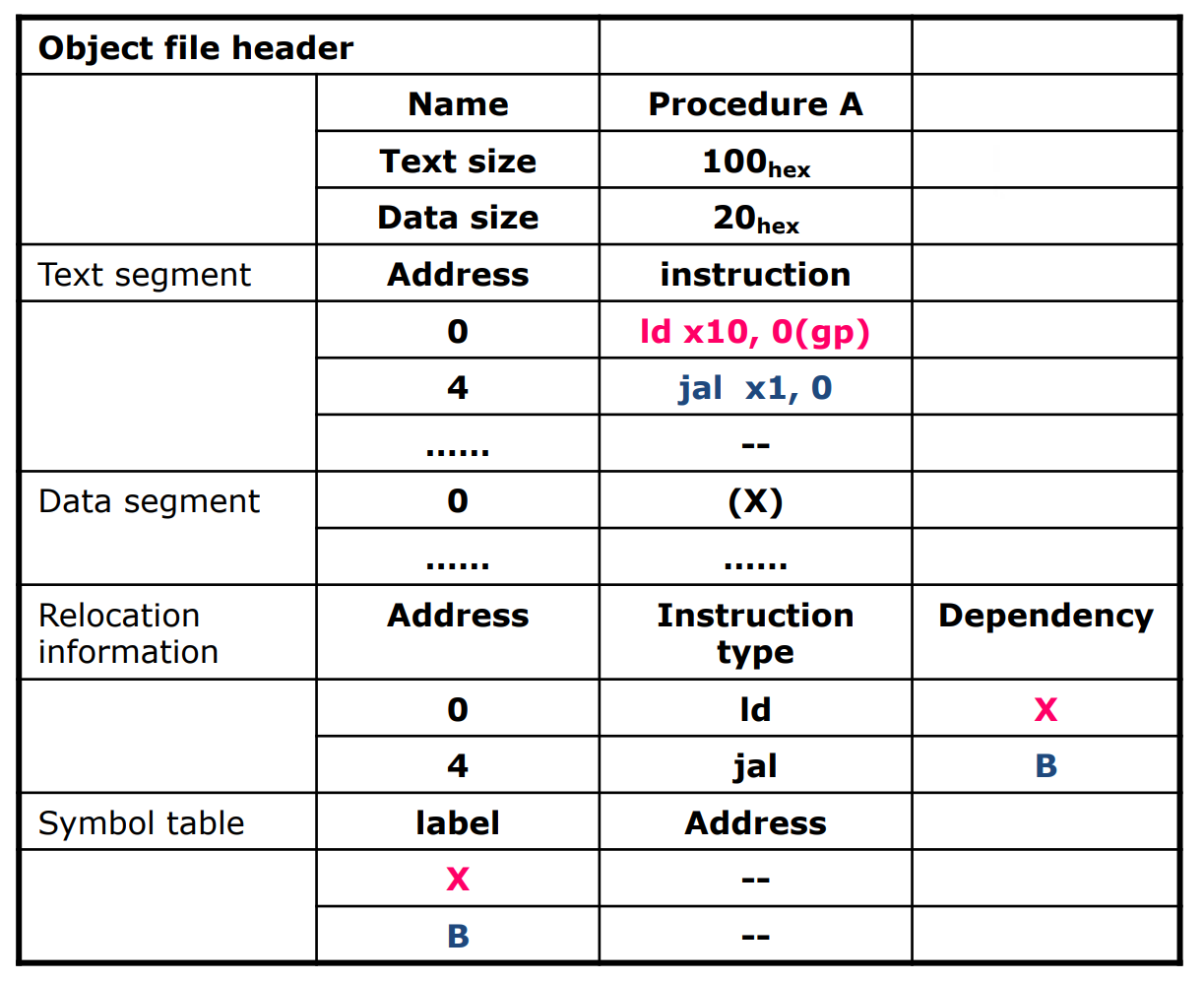
- Text segment: translated instructions
- Static data segment: data allocated for the life of the program
- Relocation info: for contents that depend on absolute location of loaded program
- Symbol table: global definitions and external refs
- Debug info: for associating with source cod
Link
Object modules(including library routine) \(\rightarrow\) executable program
- Place code and data modules symbolically in memory
- Determine the addresses of data and instruction labels
- Patch both the internal and external references (Address of invoke)
Loading a Program
Load from image file on disk into memory
- Read header to determine segment sizes
- Create virtual address space
- Copy text and initialized data into memory
Or set page table entries so they can be faulted in - Set up arguments on stack
- Initialize registers (including sp, fp, gp)
- Jump to startup routine
Copies arguments to x10, … and calls main pWhen main returns, do exit syscall
Dynamic Linking
Only link/load library procedure when it is called.
静态链接已经编入文件了,动态链接是在运行时链接,可以用到最新的代码
- Requires procedure code to be relocatable
- Avoids image bloat caused by static linking of all (transitively) referenced libraries
- Automatically picks up new library versions 自动获取新的库版本
2.13 A C Sort Example To Put it All Together¶
void swap(long long v[], size_t k)
{
long long temp;
temp = v[k];
v[k] = v[k+1];
v[k+1] = temp;
}
转换成RISC-V指令
// register alloction for swap
// v——x10,k——x11,temp——x5
swap: slli x6, x11, 3 // x6 = k * 8
add x6, x10, x6 // x6 = v + (k * 8) 是 v[k]的地址
ld x5, 0(x6) // x5 = v[k]
ld x7, 8(x6) // x7 = v[k+1]
sd x7, 0(x6) // 将v[k+1]保存到x6对应的地址,也就是v[k] = v[k+1]
sd x5, 8(x6) // 将v[k]保存到x6+8对应的地址,也就是v[k+1] = v[k]
jalr x0, 0(x1) // return to calling routine

# v - x10 n-x11 i-x19 j-x20
# saving registers
sort:
addi sp, sp, -40
sd x1, 32(sp) # return address
sd x22, 24(sp)
sd x21, 16(sp)
sd x20, 8(sp)
sd x19, 0(sp)
# procedure body
mv x21, x10 # x21 = x10 = v
mv x22, x11 # x22 = x11 = n
# outer loop
li x19, 0 # x19 = i = 0
for1test:
bge x19, x22, exit1 # i 与 n 进行比较
# inner loop
addi x20, x19, -1 # j = i - 1
for2test:
blt x20, x0, exit2 # j 与 0 进行比较
slli x5, x20, 3 # x5 = j * 8
add x5, x21, x5 # x5 = v + j * 8 也就是v[j]的地址
ld x6, 0(x5) # x6 = v[j]
ld x7, 8(x5) # x6 = v[j+1]
blt x6, x7, exit2 # 如果v[j] < v[j+1],说明v[j+1]之前都有序
# v[j] > v[j+1]
mv x10,x21 # x10 = x21 = v
mv x11,x20 # x11 = x20 = j
jal x1, swap
# inner loop
addi x20, x20, -1 # j = j -1
j for2test # 返回到循环2 for2test
exit2:
addi x19, x19, 1 # i = i + 1
j for1test # 返回到循环1 for1test
exit1:
ld x19, 0(sp)
ld x20, 8(sp)
ld x21, 16(sp)
ld x22, 24(sp)
ld x1, 32(sp)
addi sp, sp, 40
jalr x0, 0(x1) # return to calli
2.14 Arrays versus Pointers¶
指针是可以改变的,但是数组首地址不能改变,因此翻译成汇编的结果也有所不同。
Example "Clearing an Array"

上述代码的实现要求size >= 1,因为都是先进行运算,再进行边界检查
遍历数组元素——索引(索引+1)或者指针(地址+8)
可以看到指针运算的效率更高
2.15 Summary¶
寻址方式是指令集的核心区别。
- 立即数寻址
addi x5, x6, 4 - 寄存器寻址
add x5, x6, x7 - 基址寻址
ld x5,100(x6) - PC 相对寻址
beq x5,x6,L1