4. The Processor¶
约 8606 个字 预计阅读时间 43 分钟

4.1 Introduction¶
- Instruction count Determined by ISA and compiler 如同样的功能用 Intel 和 RISC-V 的处理器实现,英特尔的指令用的更少(因为更复杂)
- CPI and Cycle time Determined by CPU hardware
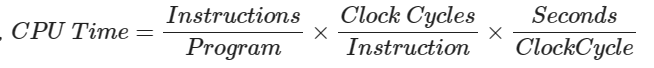

唯一的性能标准是CPU Time
For every instruction, the first two steps are identical 对于每条指令,前两个步骤都是相同的
- Fetch the instruction from the memory 从内存中获取指令
- Decode and read the registers 解码和读取寄存器
Next steps depend on the instruction class 后续步骤取决于指令类
- Memory-reference 内存参考
load, store - Arithmetic-logical 算术逻辑
- branches 分支
均需要ALU的参与
Depending on instruction class
-
Use ALU to calculate
-
Arithmetic result
-
Memory address for load / store
-
Branch comparison
-
-
Access data memory for load / store
-
PC \(\leftarrow\) target address PC + 4
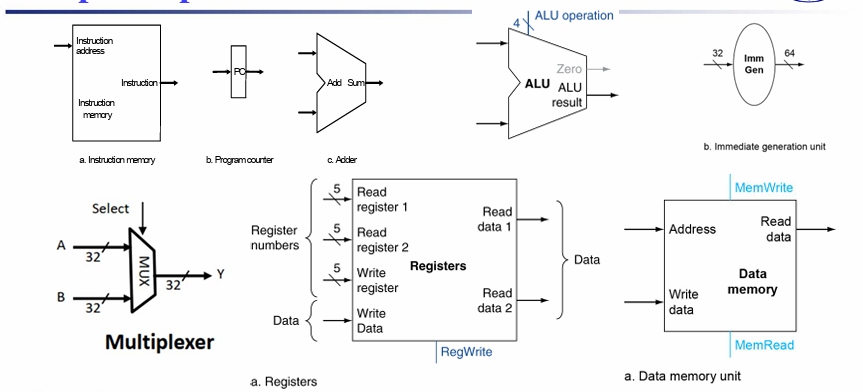

先写后读,能够实现读取最新的数据
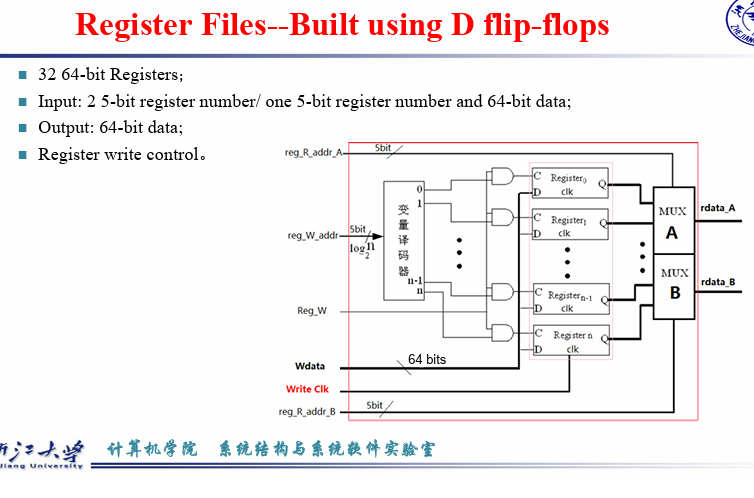
寄存器堆能够同时实现读取两个寄存器,和写入一个寄存器(对应R型指令)
reg_R_addr_A, reg_R_addr_B 是mux的选择信号
reg_W_addr 选择对那个寄存器进行load操作
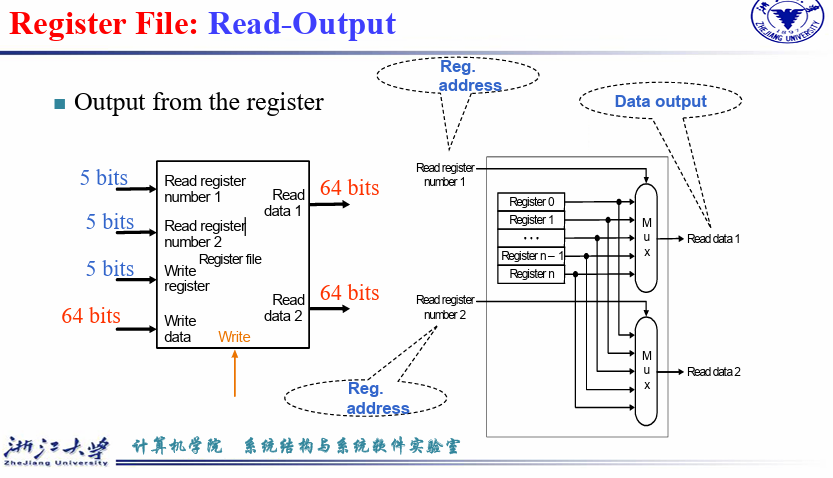
Read register number 1作为 mux 的选择信号,得到对应的 Read Data
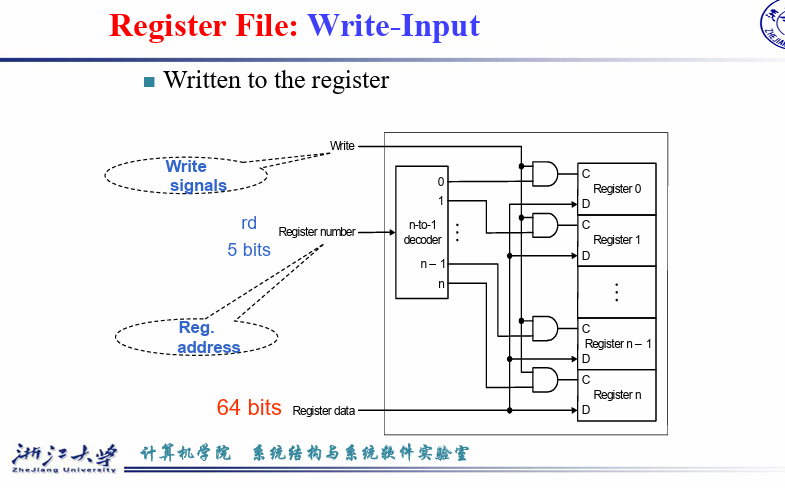
Write 决定能否写入, Register number 决定哪个寄存器进行写入,双重作用AND,
Immediate generation unit

- 根据指令类型(
ImmSel),选取特定的bit位生成相应的立即数 - 立即数字段符号扩展为64位结果输出

利用整个opcode,选择立即数的生成方式
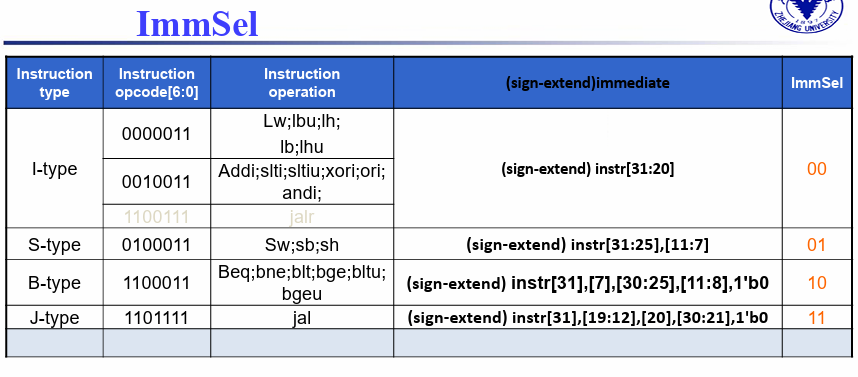
U-type 0110111 lui rd imm {instr[31:19], 12’b0}
4.2 CPU Overview¶
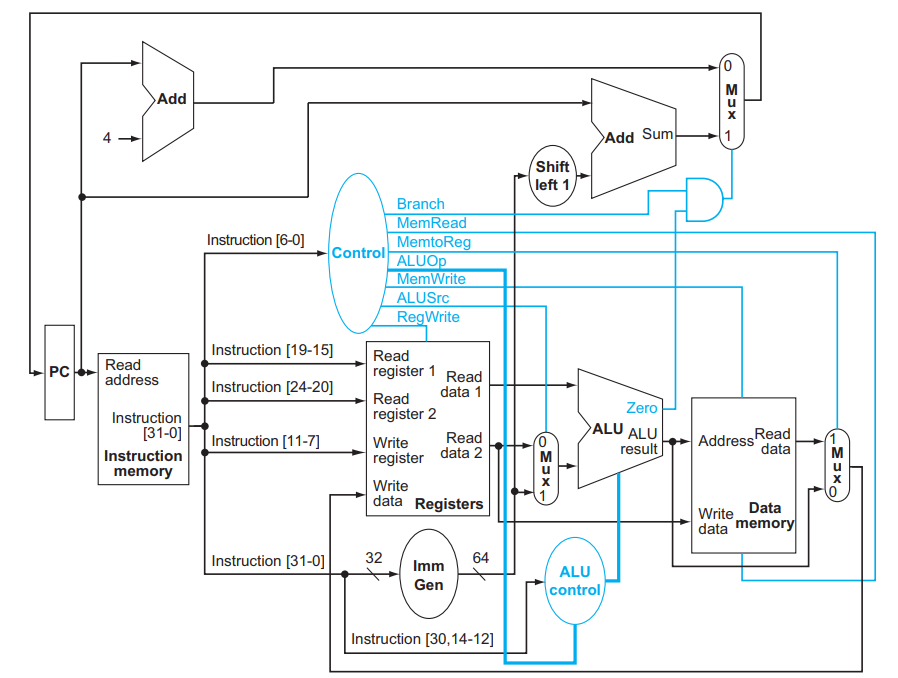
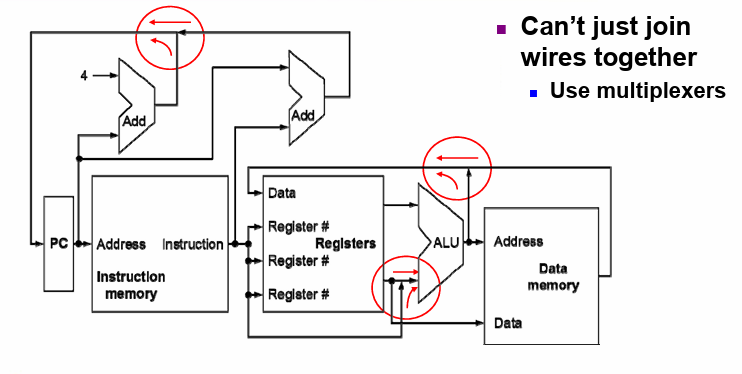

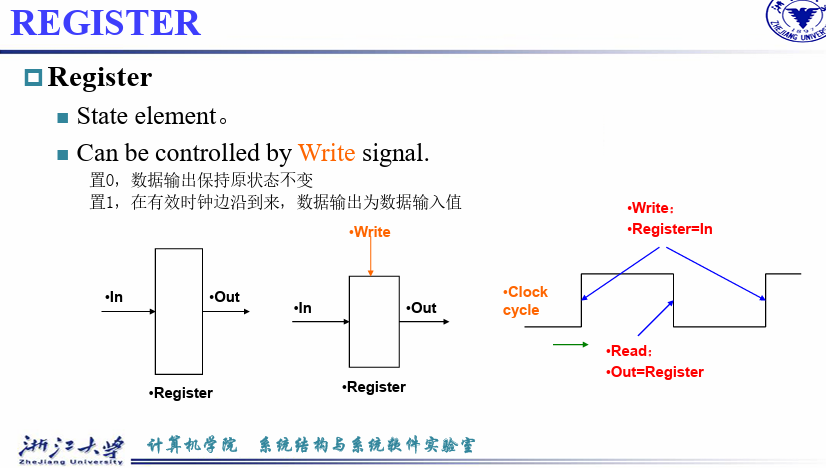
edge triggered 边沿触发
在上升沿到来时,取出state element, 后续进入combinational logic进行运算,在下一个上升沿到来后,存储state element
4.3 Building a datapath¶
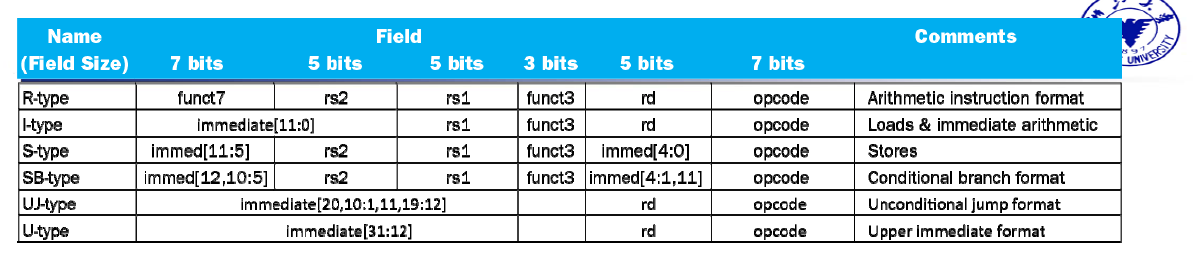
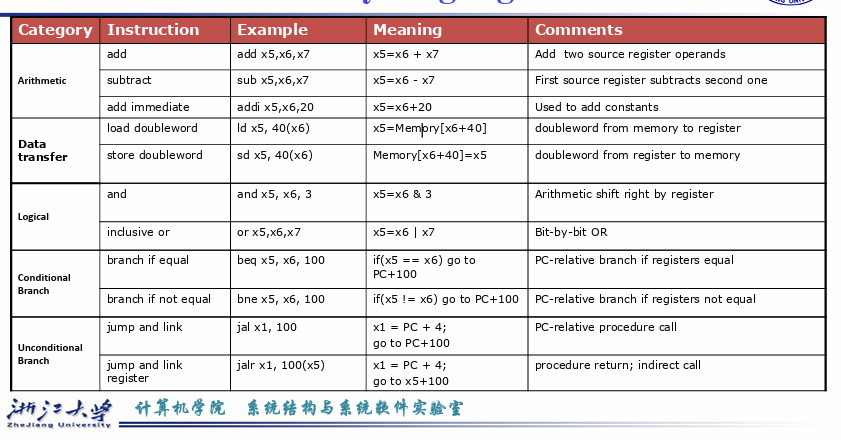
- opcode:basic operation of the instruction.
- rs1: the first register source operand.
- rs2: the second register source operand.
- rd: the register destination operand.
- funct: function,this field selects the specific variant of the operation in the op field.
- Immediate: address or immediate
 、
、
4.3.1 Instruction execution in RISC-V¶
-
Fetch 获取
- Take instructions from the instruction memory 从指令存储器中获取指令
- Modify PC to point the next instruction 修改 PC 以指向下一条指令
-
Instruction decoding & Read Operand
指令解码和读取操作数:
- Will be translated into machine control command 将转换为机器控制命令
- Reading Register Operands, whether or not to use 读取寄存器操作数,是否使用
-
Executive Control 执行控制:
-
Control the implementation of the corresponding ALU operation
控制相应 ALU 操作的实现
-
-
Memory access 内存访问:
- Write or Read data from memory 从内存中写入或读取数据
- Only ld/sd 只有 ld/sd
-
Write results to register 写入结果进行注册:
-
If it is R-type instructions, ALU results are written to rd
如果是 R 型指令,则将 ALU 结果写入 rd
-
If it is I-type instructions, memory data are written to rd
如果是 I 型指令,则内存数据将写入 rd
-
-
Modify PC for branch instructions 修改 PC 以获取分支说明
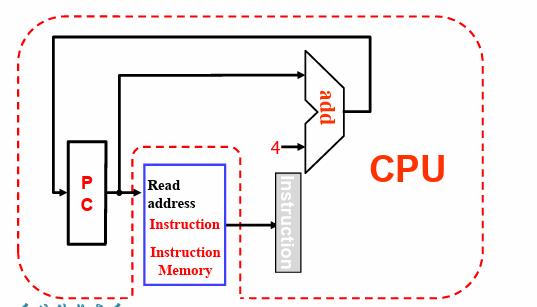
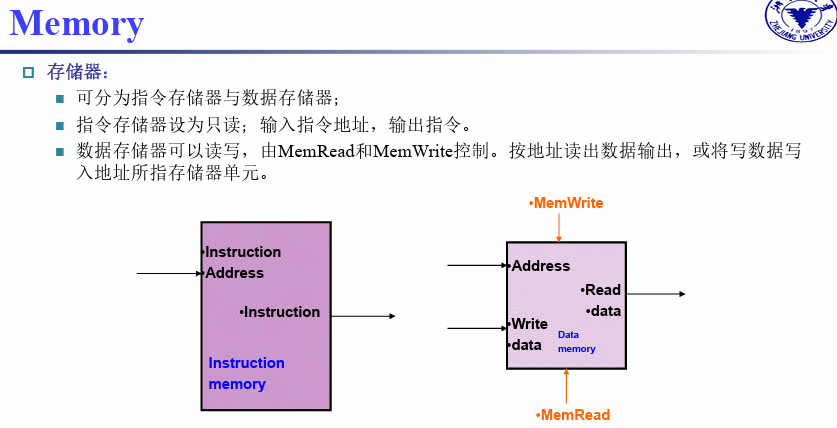
PC地址对应的数据(指令的地址),直接进入内存读取指令,此处不需要控制read 还是 wirte
为什么PC + 4? 因为一条指令有32位,一个字节8位
4.3.2 R型指令¶
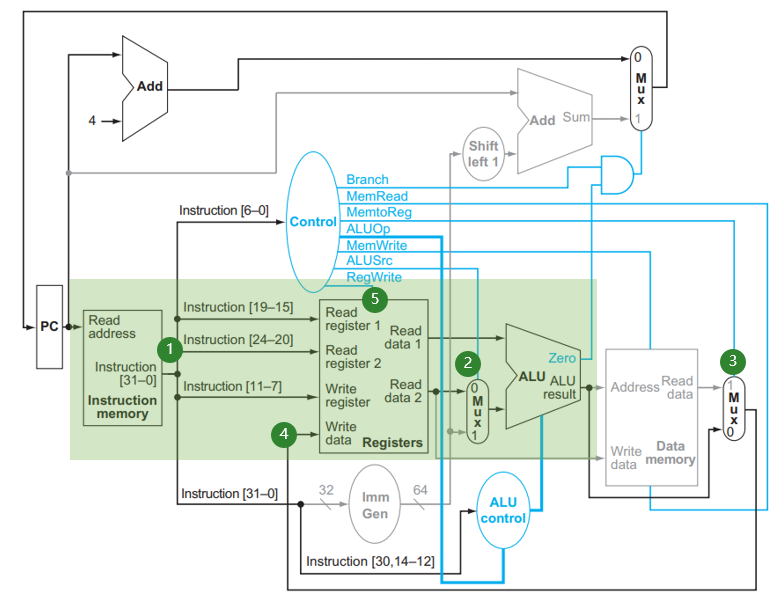
- (1) 处取出指令,
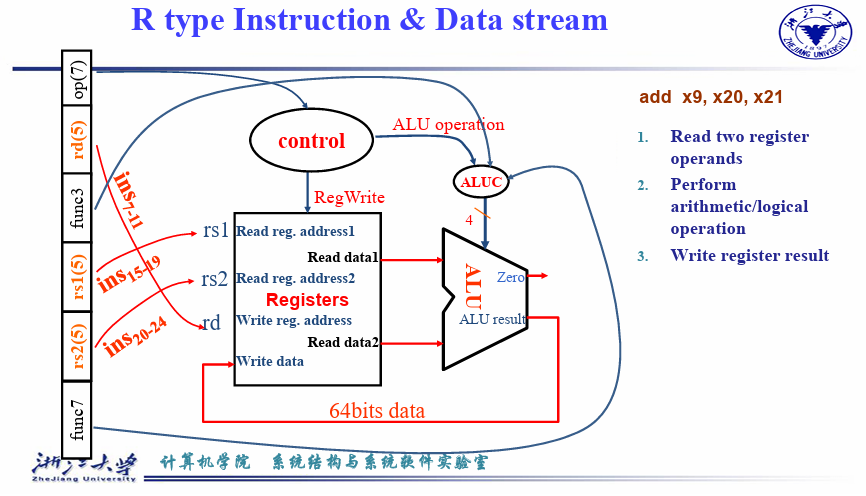
[6:0](opcode)被送到 Control 产生对应的控制信号,我们稍后可以看到;[19:15](rs1),[24:20](rs2),[11:7](rd)分别对应rs1,rs2,rd,被连入 Registers 这个结构,对应地Read data 1和Read data 2两处的值即变为rs1,rs2的值; - (2) 处 MUX 在
ALUSrc = 0的信号作用下选择Read data 2作为 ALU 的输入与Read data 1进行运算,具体的运算由ALU control提供的信号指明(我们在 4.1.3 小节 讨论这个话题)。运算结果在ALU result中。 - (3) 处 MUX 在
MemtoReg = 0的信号作用下选择ALU result作为写回 Register 的值,连到 (4) 处;在 (5) 处RegWrite = 1信号控制下,该值写入到rd寄存器中。
4.3.3 I型指令¶
addi && ld
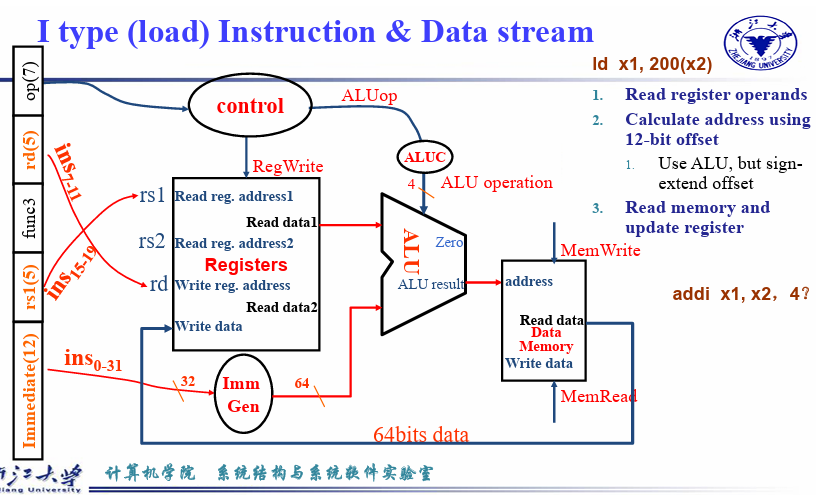
- 对于addi,在ALU前,需要添加mux,区分imm和sourse register
- 对于load, 在ALU计算之后,计算出地址,进入到data memory取数据,取出来之后需要存储到rd,所以在ALU之后还需要一个mux,一个存储内存取出的data,一个是ALU直接计算的data
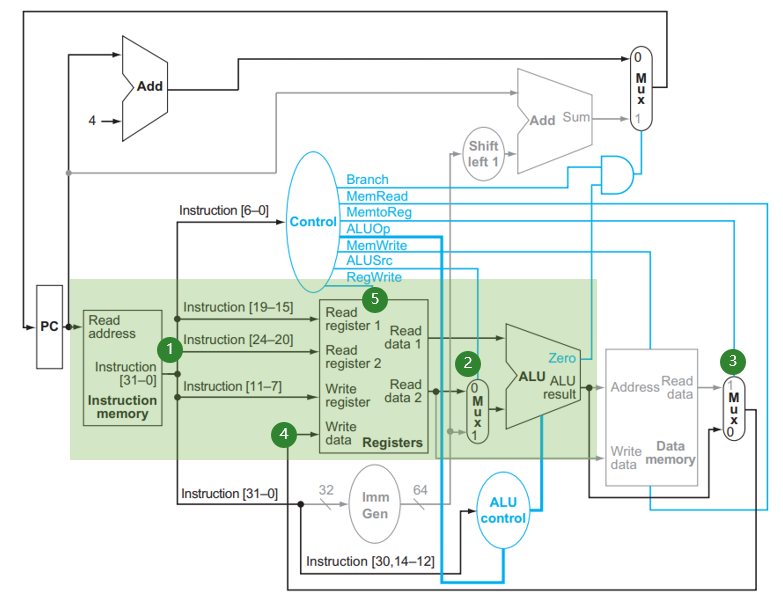
addi:
- (1) 处取出指令,
[6:0](opcode)被送到 Control 产生对应的控制信号,我们稍后可以看到;[19:15](rs1),[11:7](rd)分别对应rs1,rd,被连入 Registers 这个结构,对应地Read data 1的值即变为rs1的值;[31:20] (imm)对应立即数,传输到Imm_Gen - (2) 处 MUX 在
ALUSrc = 1的信号作用下选择Imm_out作为 ALU 的输入与Read data 1进行运算,具体的运算由ALU control提供的信号指明(我们在 4.1.3 小节 讨论这个话题)。运算结果在ALU result中。 - (3) 处 MUX 在
MemtoReg = 0的信号作用下选择ALU result作为写回 Register 的值,连到 (4) 处;在 (5) 处RegWrite = 1信号控制下,该值写入到rd寄存器中。
ld:
- (1) 处取出指令,
[6:0](opcode)被送到 Control 产生对应的控制信号,我们稍后可以看到;[19:15](rs1),[11:7](rd)分别对应rs1,rd,被连入 Registers 这个结构,对应地Read data 1的值即变为rs1的值;[31:20] (imm)对应立即数,传输到Imm_Gen - (2) 处 MUX 在
ALUSrc = 1的信号作用下选择Imm_out作为 ALU 的输入与Read data 1进行运算,具体的运算由ALU control提供的信号指明(我们在 4.1.3 小节 讨论这个话题)。运算结果在ALU result中。 - (3) ALU_result 计算的是 内存的地址,从 Data memory中取出data,经过(3)处MUX的选择,传输到Register File,在RegWrite = 1的控制,写入到目标寄存器
4.3.4 S型指令¶

注意store指令的格式,不再存在rd,func7,分别转化为imm[4:0], imm[11:5]
对于store指令,sd x8,200(x9), 将x8的数据存储到指定的地址
write_data, 和 write_addr,连接到data memory
4.3.5 SB型指令¶

需要两个ALU,一个ALU计算x1和x2的差值,得到的结果zero用于mux的选择信号,选择PC+4或者PC+200
另一个ALU,用于计算PC+imm
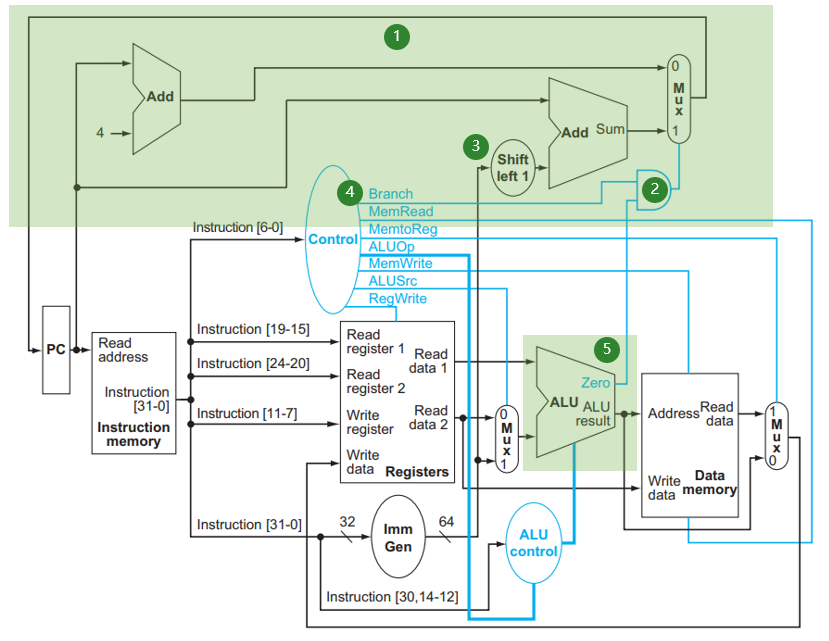
- (1) 中有两个加法器,一个的结果是 PC + 4,另一个是 PC + offset,其中 offset 是来自当前 instruction 的;这两个加法器通过 MUX 送给 PC
- MUX 的控制信号来自 (2), (2) 是一个与门,即当且仅当两个输入信号都为真时才会输出 1,从而在上述 MUX 中选择跳转。 (2) 的两个输入分别来自:
- (5) 这个 ALU 的 Zero 信号,这是第 3 章中我们设计的可以用来实现
beq的结构;我们讨论过实现beq其实就是计算rs1 - rs2判断其是否为 0,所以这里根据 Zero 是否为 0 就能判断两个寄存器是否相等 - (4) 处 Control 给出的
Branch信号,即如果这个语句是跳转语句,那么对应的信号会置为 1
- (5) 这个 ALU 的 Zero 信号,这是第 3 章中我们设计的可以用来实现
也就是说,当且仅当语句确实是 beq 而且 Zero 信号的值确实为 1 时才会进行跳转。
4.3.6 UJ型指令¶
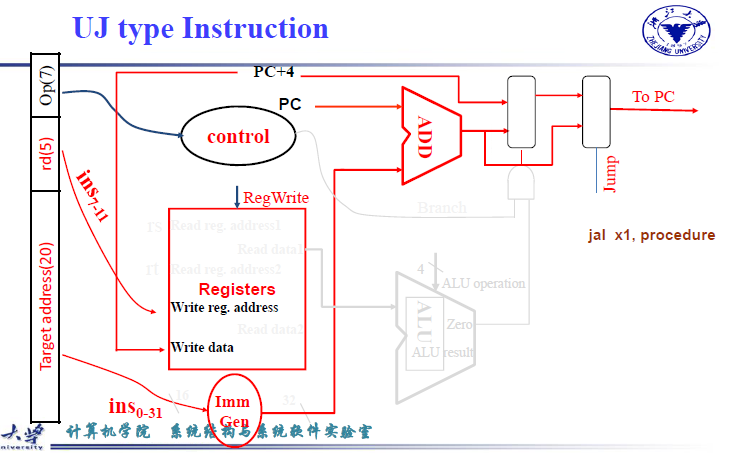
无条件跳转,采用PC相对寻址 PC+imm
额外部分在于将PC+4存储到x1寄存器
扩充:PC+4在ALU之后的输出结果分为两条路,一条指向寄存器堆(此处可以和data memory之前mux合并,一起选择),将PC+4保存在x1,另一条和PC+imm进行mux的选择
4.3.7 U型指令¶
lui x5, imm 读取立即数的值,将imm保存到目标寄存器的高20位
直接将imm连接到data memory前的mux合并(现在有4个选择),此处的mux输出结果连接到寄存器堆的write_data
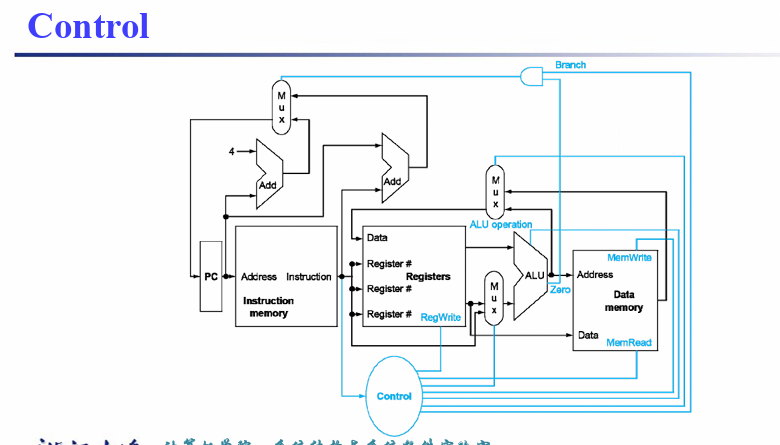
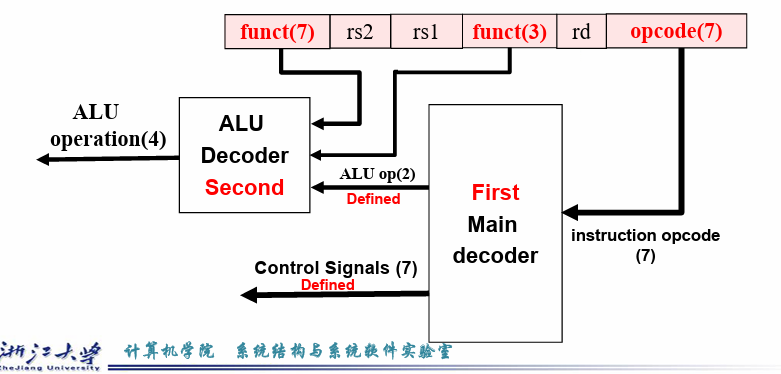
4.4 controller¶
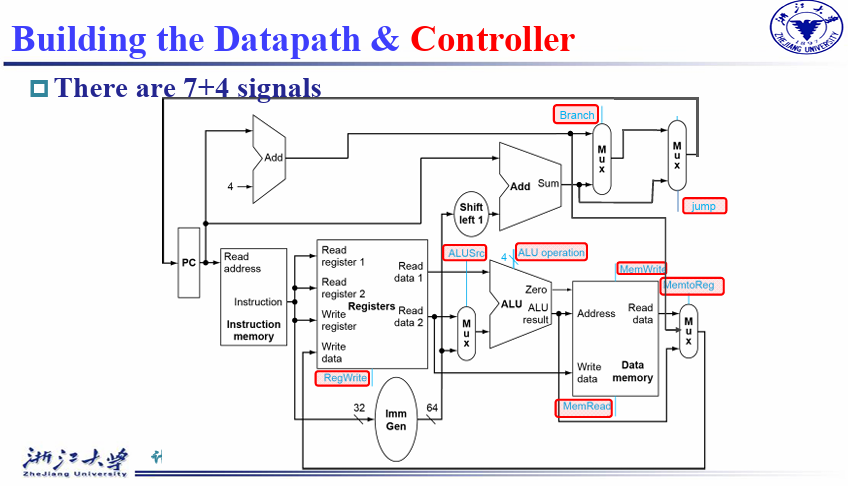
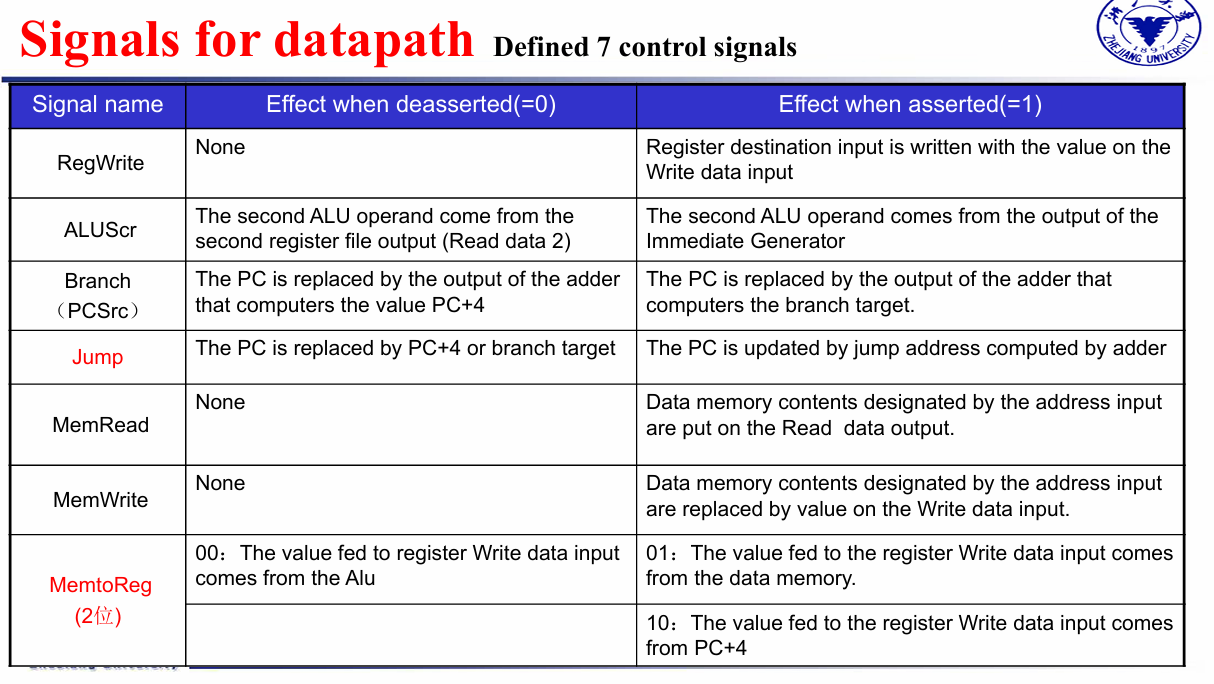
7 个控制信号和一个 4 位的 ALU_operation
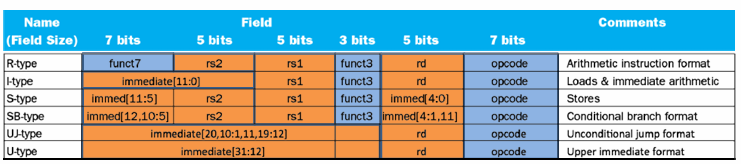
蓝色表示与controller有关
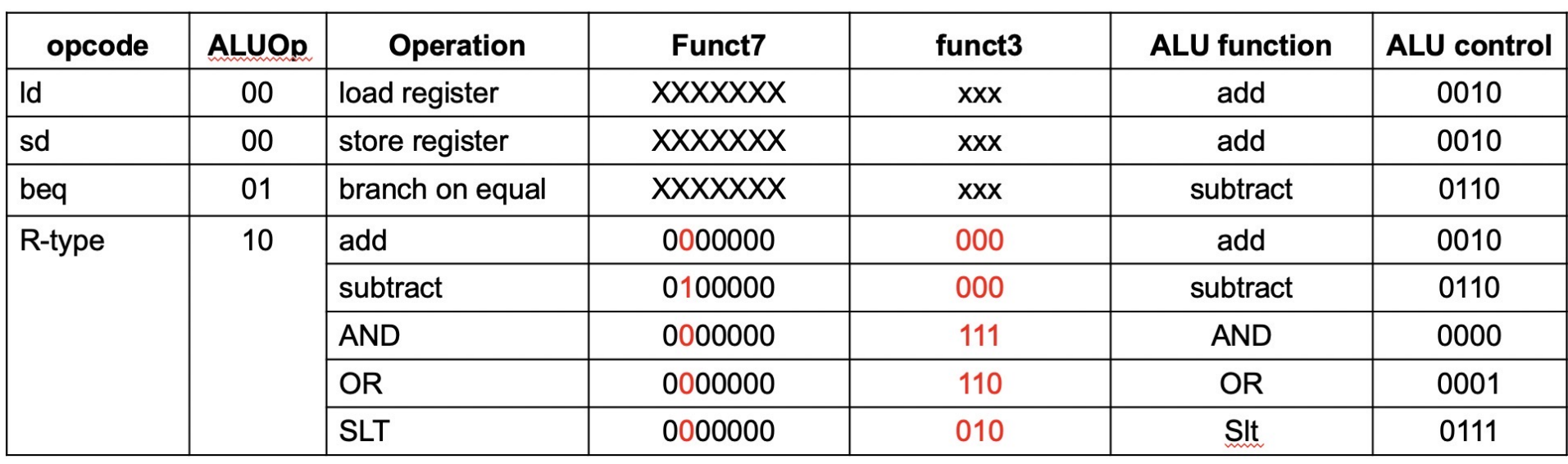
4.4.1 ALU control¶
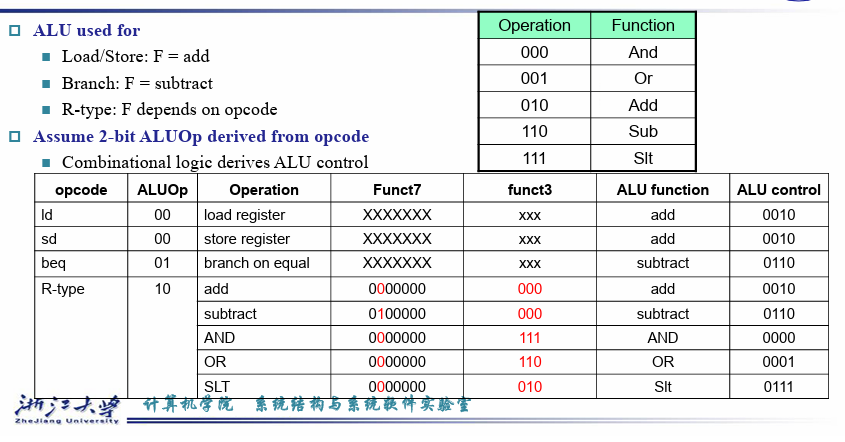
先根据opcode生成两位的ALUop
再根据func3和func7[5] 生成ALU control
-
First level
- 一级解码后,可以决定除了
ALU_opration以外的控制信号 - 同时我们会解码出 2 位的
ALU_op.
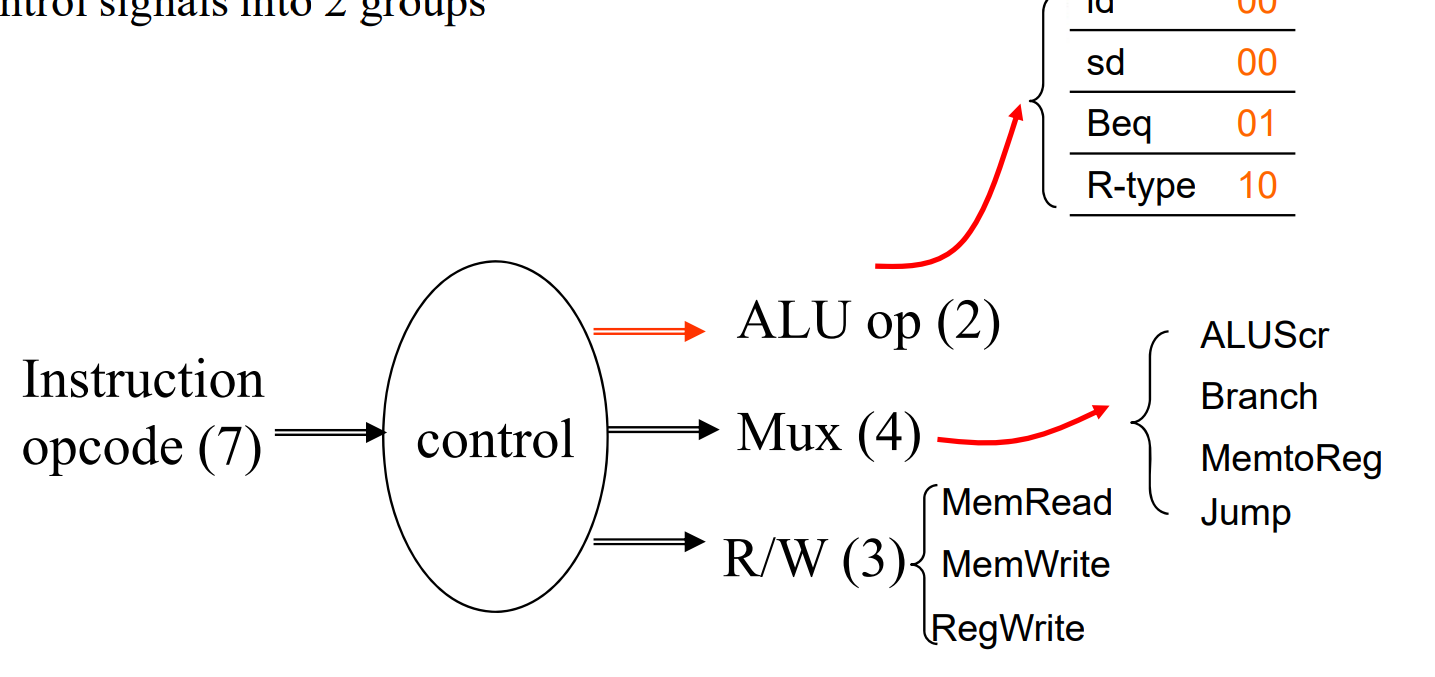

- 一级解码后,可以决定除了
-
Second level
ALU operation is decided by 2-bit ALUOp derived from opcode, and funct7 & funct3 fields of the instruction.
4.4.2 Datapath with Control¶
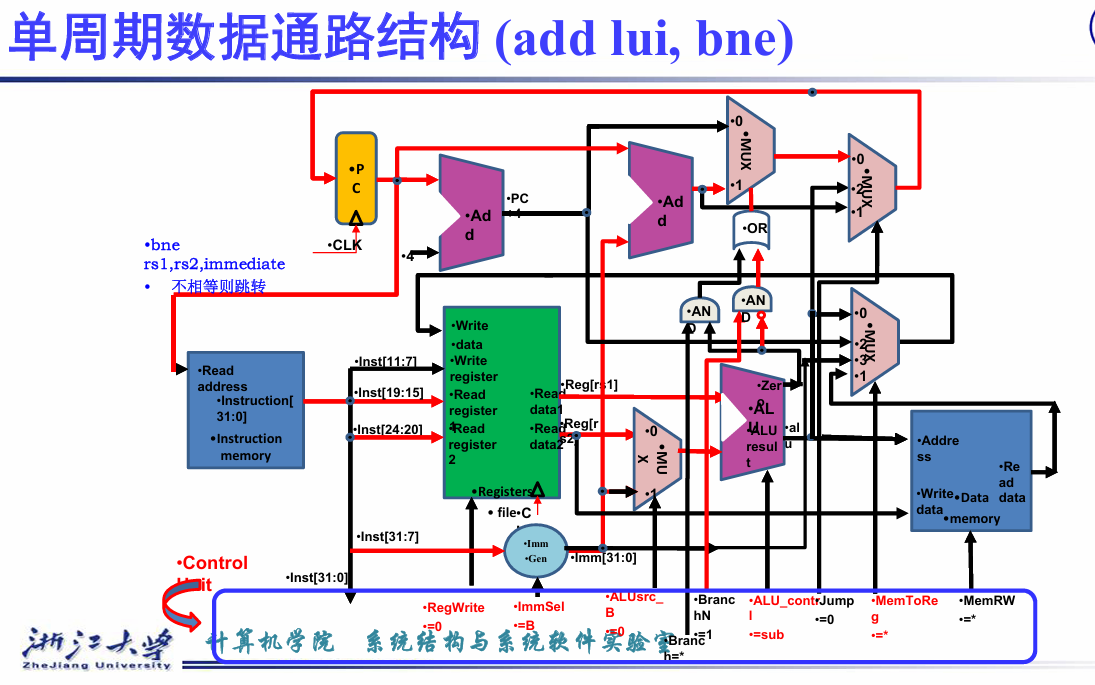
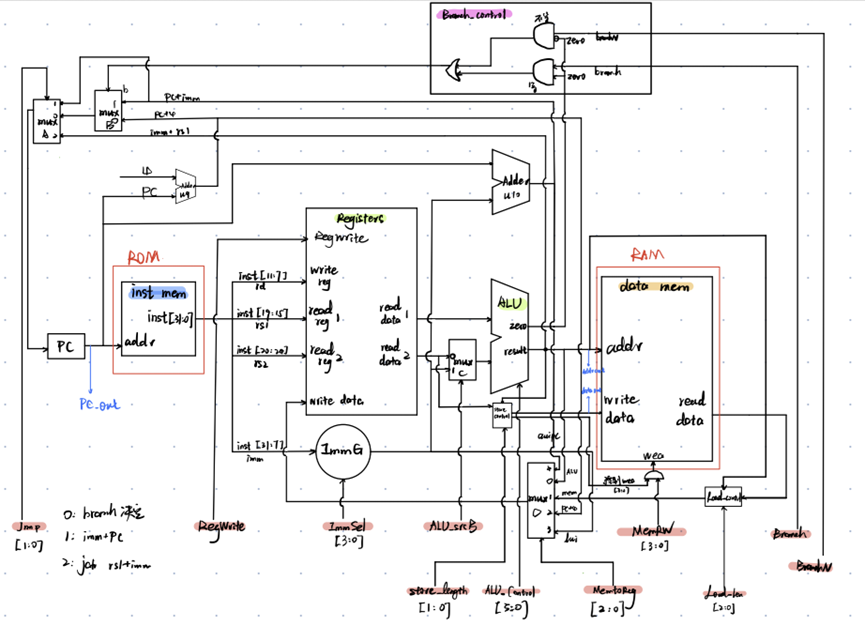
右上方的第一个MUX,选择PC+4和PC+imm,执行的是branch操作,选择信号是branch
第二个MUX,选择branch未执行的结果(PC+4),jalr(rd+imm),PC+imm,执行的是jump操作,选择信号是jump
当然也可以仅用一个mux实现,选择PC+4,PC+imm,rs+imm,只需要满足branch和jal的选择信号是00/01,jalr的选择信号是10,
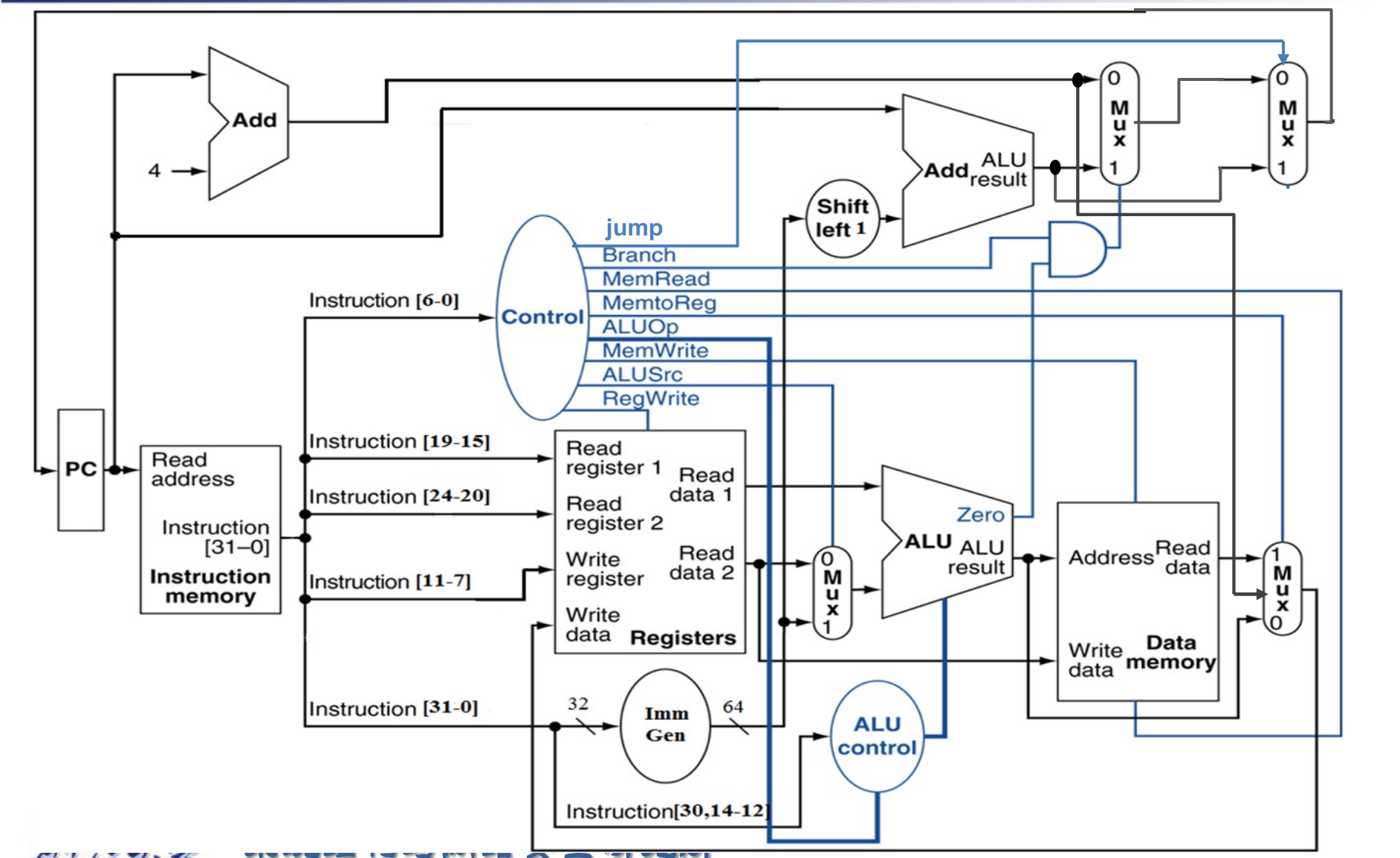

-
ld的 MemtoReg = 01,目的是将指定地址的数据写到目标寄存器
-
addi,addi x5,x6,200
200 x6 fun3 x5 addi
ALUSrcB = 1,选择imm。MemtoReg = 0.选择 x5 + imm。RegWrite = 1,将结果写到rd。MemRead = 0.MemWrite = 0.Branch = 0。Jump = 0.
-
jalr, jalr x1, 200(x7) I 型指令
1 10 1 0 0 0 1
-
lui,imm直接连接到MemtoReg,此时MemtoReg = 11.
X 11 1 0 0 0 ….
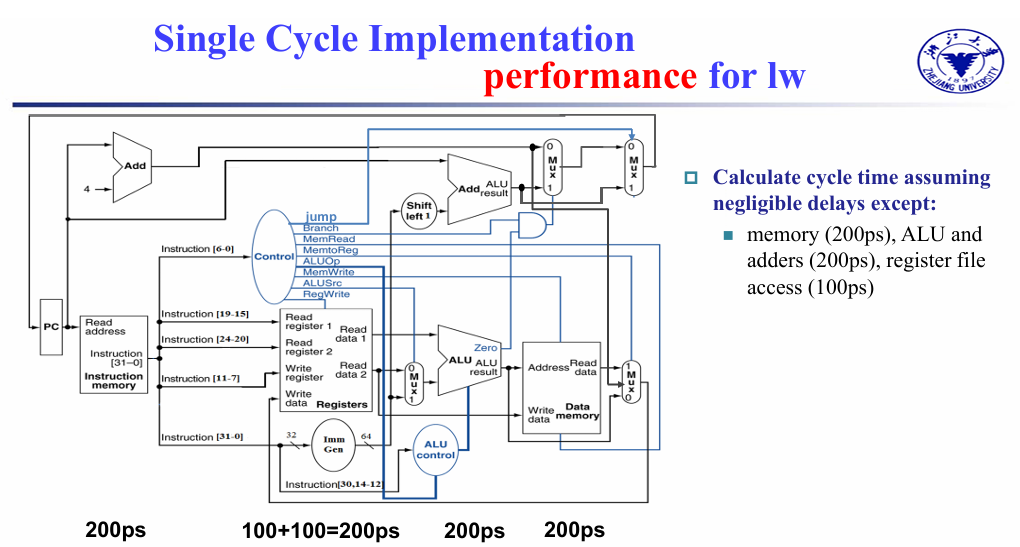
单周期的实现是指,一个指令的所有工作都在一个时钟周期内完成,也就是 CPI = 1。那么,一个时钟周期的长度就要足够最长的那个指令完成运行。
但是,例如 load 类的指令要经过 inst mem, reg file, ALU, data mem, reg file 这么多的步骤,这会使得时钟周期变得很长,导致整体性能变得很差。
单周期的实现违反了 common case fast 这一设计原则。
4.5 Exception¶
The cause of changing CPU’s work flow :
-
Control instructions in program (bne/beq, jal , etc)
It is foreseeable in programming flow
-
Something happen suddenly (
Exception and Interruption)It is unpredictable
Call Instructions triggered by hardware
Exception
- Arises within the CPU(e.g., overflow, undefined opcode, syscall, …)
Interrupt
- From an external I/O controller
Dealing with them without sacrificing performance is hard

4.5.1 Handling Exceptions¶

mtvec提供基地址,根据mCAUSE计算偏移量,跳转到相应的handle
4.5.2 RISC-V Privileged¶

-
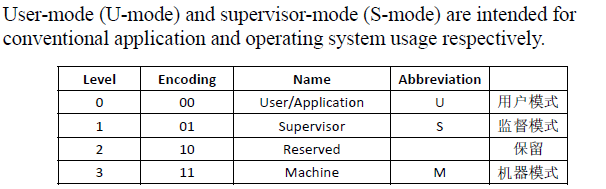
All hardware implementations must provide M-mode最简单的RISC-V实现,仅提供 M mode
-
Machine mode most important task:intercept and handle interrupts/exceptions(使用CSR寄存器)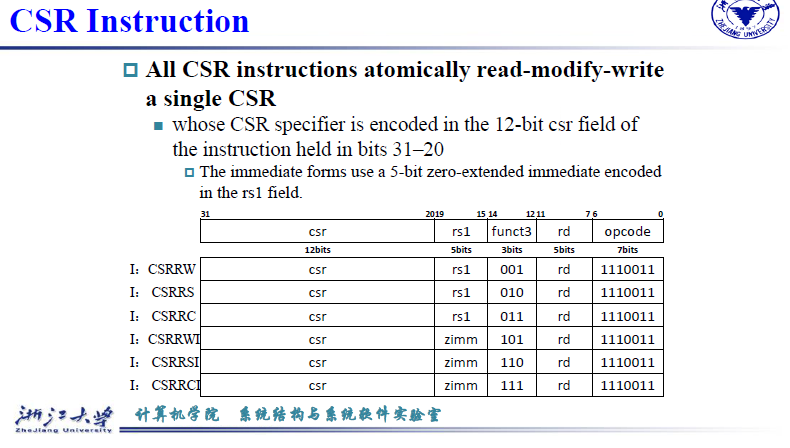
mechine level has the highest privileges
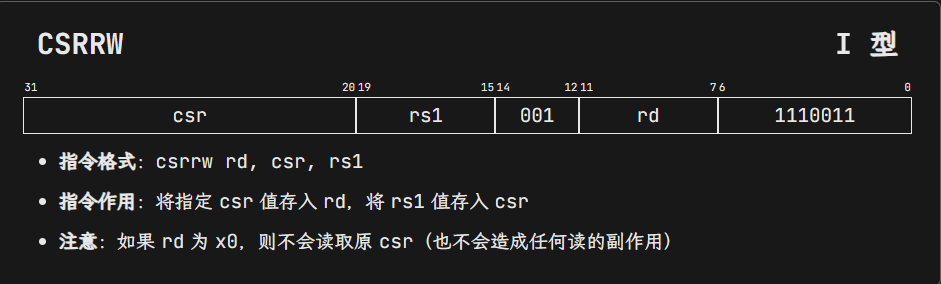
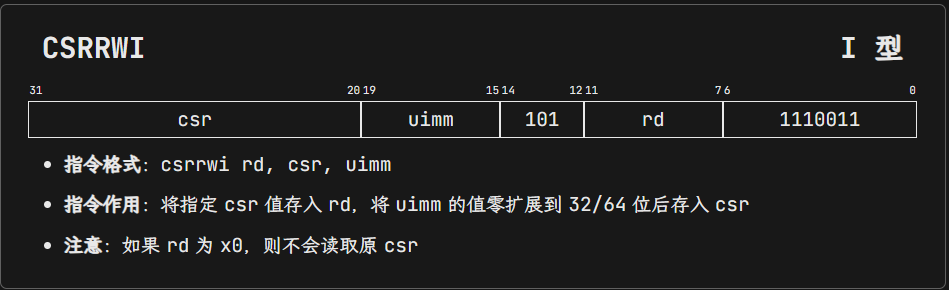
CSR 指令都使用 I 型指令,其中 12 位的立即数部分表示 CSR 的地址,funct3 低 2 位用来编码读 / 改 / 写(read-modify-write)操作、高 1 位表示是否来自立即数(如果来自立即数则 rs1 部分表示一个 5 位无符号立即数),opcode 都是 SYSTEM(1110011)。




// CSR 相关指令包括
// 1. csrrw 读取 CSR 寄存器的值到 rd,然后将 rs1 的值写入 CSR 寄存器
// 2. csrrs 读取 CSR 寄存器的值到 rd,然后将 rs1 的值与 CSR 寄存器的值进行或操作,然后写入 CSR 寄存器
// 3. csrrc 读取 CSR 寄存器的值到 rd,然后将 rs1 的值与 CSR 寄存器的值进行与操作,然后写入 CSR 寄存器
// 4. csrrwi 读取 CSR 寄存器的值到 rd,然后将 zimm 写入 CSR 寄存器
// 5. csrrsi 读取 CSR 寄存器的值到 rd,然后将 CSR 寄存器的值与 zimm 进行或操作,然后写入 CSR 寄存器

CSRRW:将csr的值赋值给rd,将rs1的值写入到csr(Read and Write)
CSRRS:需要改动的位Set,rs1特定位置为1,其他位为0,csr = csr | rs1(Read and Set)
CSRRC:将指定位清零,rs1特定位置为0,其他位为1,csr = csr & ~rs1(Read and Clear)

MRET,mstatus需要变化,eg: mp \(\leftarrow\) mpp, mie \(\leftarrow\) mpie
MRET:用于执行完异常处理之后返回wfi(wait for interrupt)

-
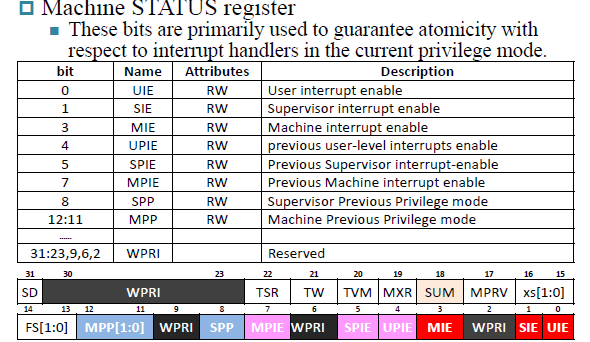
mstatus:
Machine Status register 机器模式状态寄存器标记中断全局使能,MIE(0011),SIE(0001),UIE(0000),高级别不理低级别,低级别响应高级别
如果MIE=0,机器模式下所有的中断都不发生,CPU干自己的事情不被打断。异常能够正常处理(因为是CPU内部问题)
xPIE holds the value of the interrupt enable bit active prior to the trapxPIE表示前一个中断的interrupt enable bit的值
xPP holds the privious privilege modexPP表示前一个privilege mode(从哪个模式跳到哪个模式,U->M)
-
mie / mip:中断的局部使能
- MEIE、SEIE and UEIE enable external interrupt
- MSIE、SSIE & USIE enable software interrupts
- MTIE、STIE and UTIE enable timer interrupts
-
mtvec : Machine Trap-Vector Base-Address Register由 vector base address 和 vector mode 组成 基地址+偏移量

两个模式,
- 查询模式(异常和中断,默认查询模式):一种直接跳转到base
- 向量模式(仅外部中断且Mode value = 1):另一种和case结合,基地址+偏移量
-
mepc:Machine Exception Program Counter异常断点PC地址
exception(内部): mepc $\leftarrow $ pc
interrupted(外部): mepc \(\leftarrow\) pc + 4
最后两位或者最后一位bit是0,保证能被4整除(PC占4字节)
-
mcause:异常原因
Exception Code与mtvec的向量模式相对应,在异步中断时,不同的模式会跳转到不同的入口。
如果是查询模式呢?都是跳转到Base地址,再根据mcause的值进行相应的处理即可The Exception Code is a WLRL,Write/Read Only Legal Values 如果写入值不合法会引发非法指令异常

interrupt = 1 表示中断, interrupt = 0, 表示异常
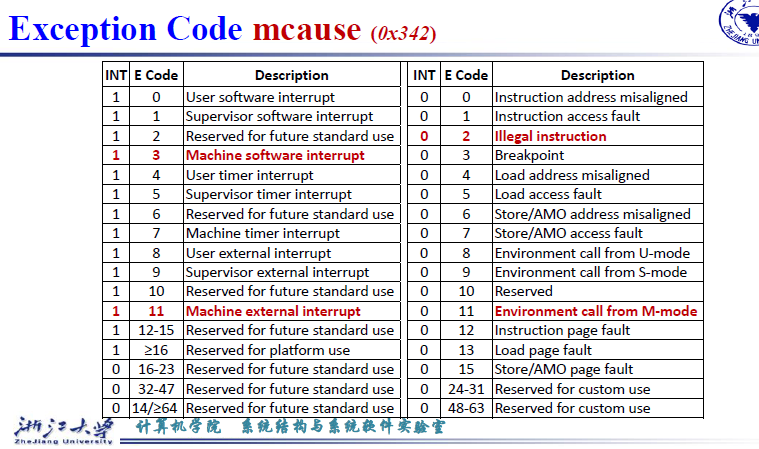
Instruction address misaligned PC地址没有对齐,最后一位是1
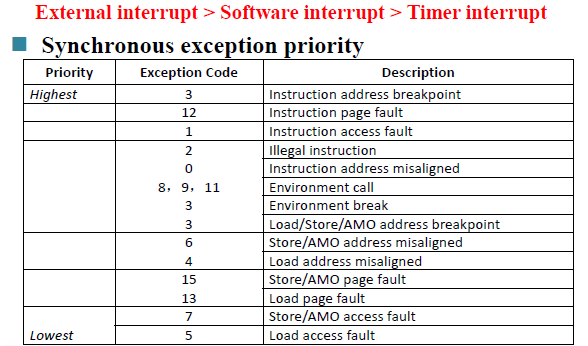
-
RISC-V 中断处理——进入异常
更新mcause,mepc,mtval,mstatus,停止执行当前的程序流,转而从CSR寄存器mtvec定义的PC的执行中断

-
RISC-V中断处理——异常服务程序
通过查询mcause中的异常编号跳转到相应的异常服务程序
-
RISC-V中断结构——退出异常

mpie保存的是进入到中断处理之前的模式,中断处理完后需要返回

- decoder controller 在译码的时候,检查是否为illegal instruction
-
ALU计算出内存地址后,需要送到test logic中检查是否为4的倍数(前提得是load/store指令),也就是是否对齐
-
根据mcause的INT决定 mepc = pc / pc + 4
mcause修改指定位(利用CSRRS)
4.6 Overview of Pipelining¶
流水线:指令的执行在时间是存在重叠,前一条指令还在执行,后一条就开始执行
Why pipelining
对于单个工作,流水线技术并没有缩短其运行时间;但是由于多个工作可以并行地执行,流水线技术可以更好地压榨资源,使得它们被同时而不是轮流使用,在工作比较多的时候可以增加整体的 吞吐率 throughput,从而减少了完成整个任务的时间。
4.6.1 Pipelining¶
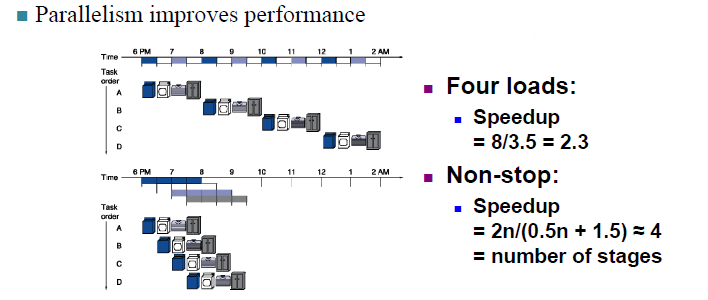
我们可以把每条指令都划分为这么几步:
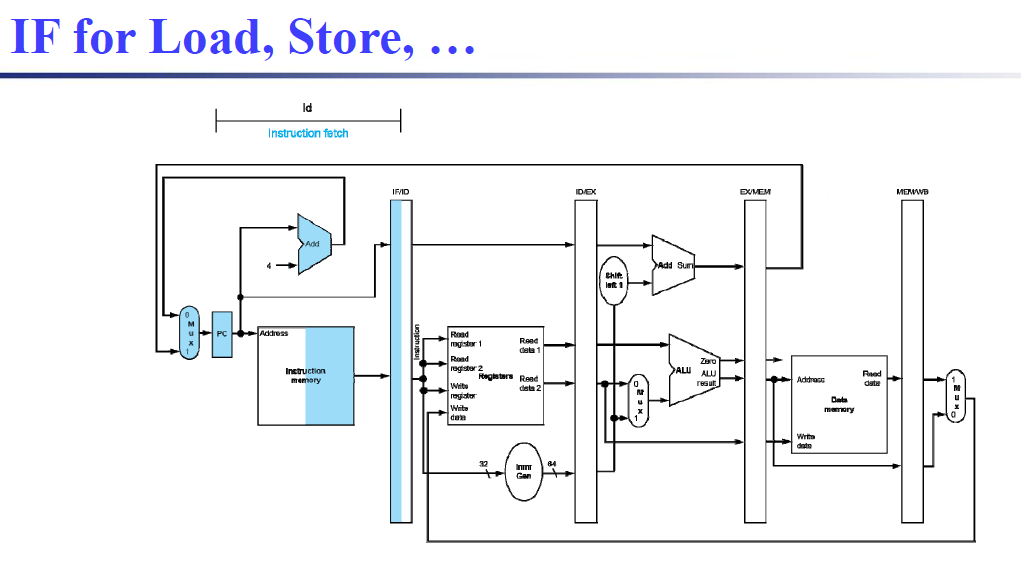
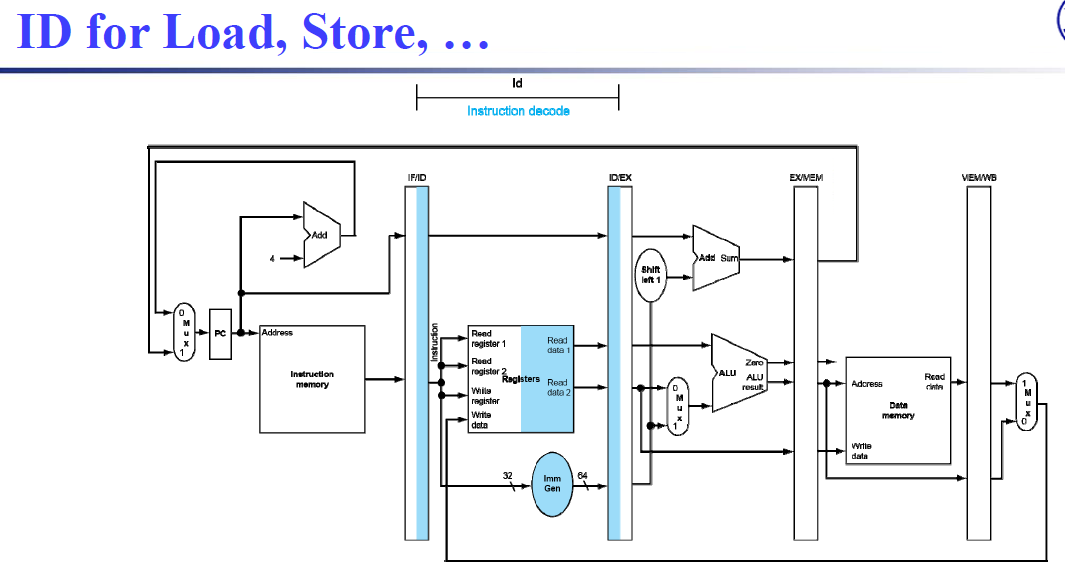
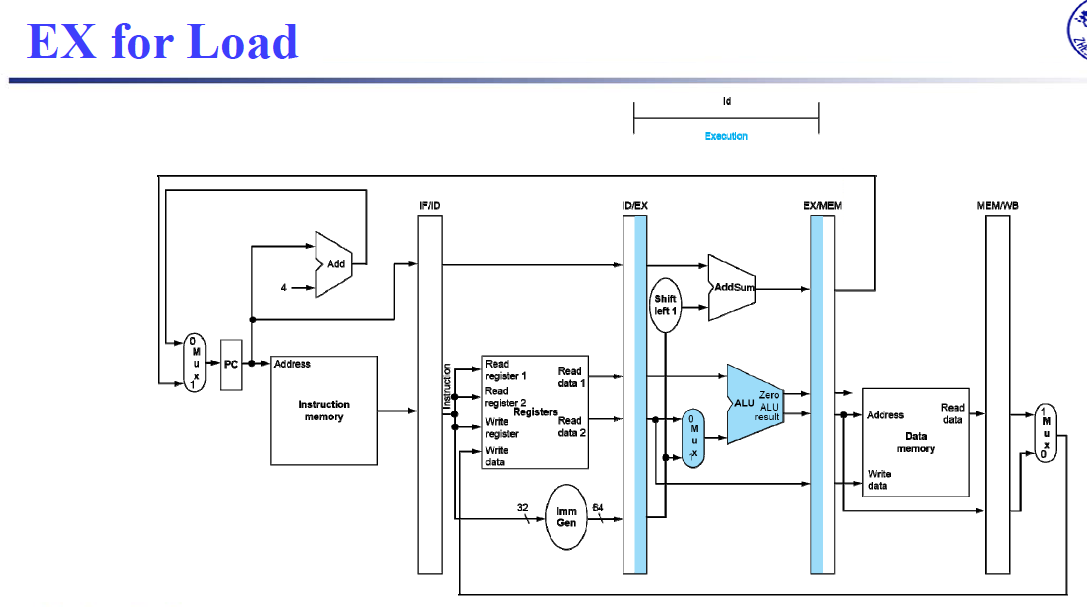
- IF: Instruction fetch from memory 从内存中获取指令
- ID: Instruction decode & register read 读取寄存器、指令译码
- EX: Execute operation or calculate address 计算操作结果和/或地址
- MEM: Access data memory operand 内存存取(如果需要的话)
- WB: Write result back to register 将结果写回寄存器(如果需要的话)
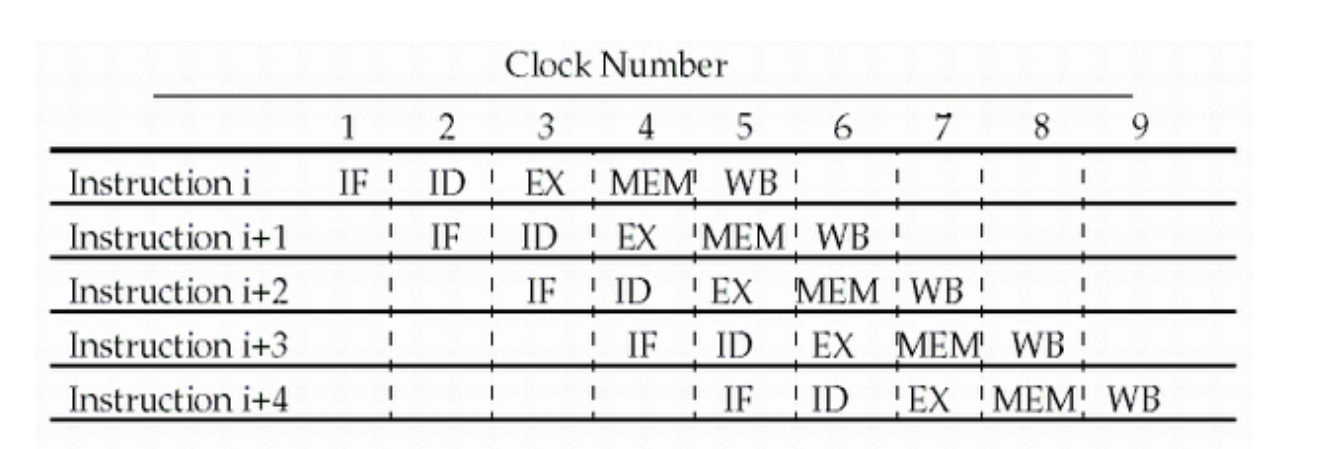
\(CPI \approx 1\)
- One instruction will be issued (or finished) each cycle.
每个周期将发出(或完成)一条指令。 - During any cycle, one instruction is present in each stage.
在任何周期中,每个阶段都存在一条指令。
4.6.1.1 Pipeline Performance¶
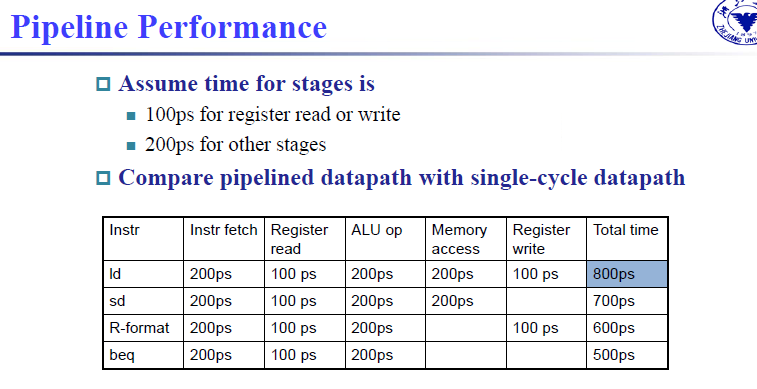
对于单周期 CPU, CPI 是 1, 但时钟周期会很长。
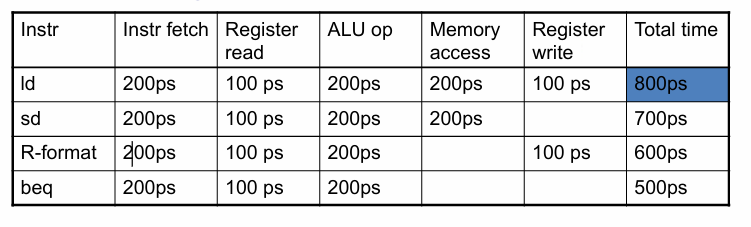
假设取指令 200ps, 寄存器读 100ps, ALU 计算 200ps, 内存访问 200ps, 寄存器写 100ps.
那么 add 需要 600ps, ld 需要 800ps, sd 需要 700ps, beq 需要 500ps.
Longest delay determines clock period. (ld)
最长延迟决定了时钟周期。( ld )
We will improve performance by pipelining.
我们将通过流水线来提高性能。
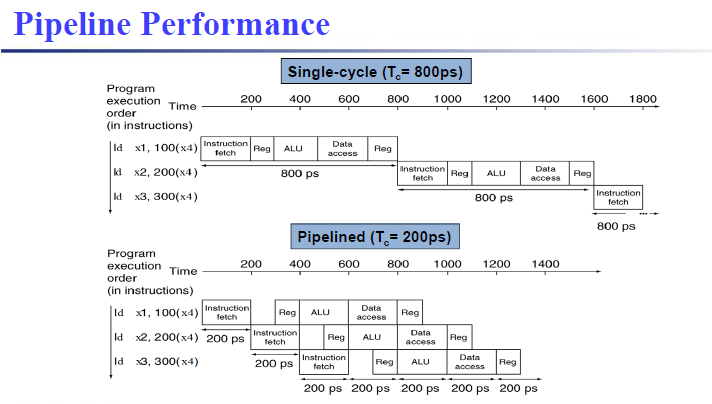
分阶段进行,每一个阶段200ps不同操作的时间也不同,流水线 CPU 的时钟周期为最长的操作时间。
注意一下此处的Reg,分别表示从寄存器堆中读取和写入,我们将读取放在单个时钟周期的后半部分,写入放在单个时钟周期的前半部分。(先读后写)

各阶段时间均匀,得到的加速效果最好
流水线可以提高吞吐量(throughput),但是latency不会减少 (
反而会增加)。但是单条指令在流水线的执行时间比在单周期CPU中的执行时间长,因为流水线每一阶段中间都需要流水线寄存器传输值,造成时间的浪费
4.6.1.2 RISC-V ISA designed for pipelining¶
RISC-V 适合流水线设计。
-
All instructions are 32-bits(指令定长,指令的fetch和decode时间相近)
Easier to fetch and decode in one cycle
-
Few and regular instruction formats (指令格式较少)
Can decode and read registers in one step
-
Load/store addressing
Can calculate address in 3rd stage, access memory in 4th stage
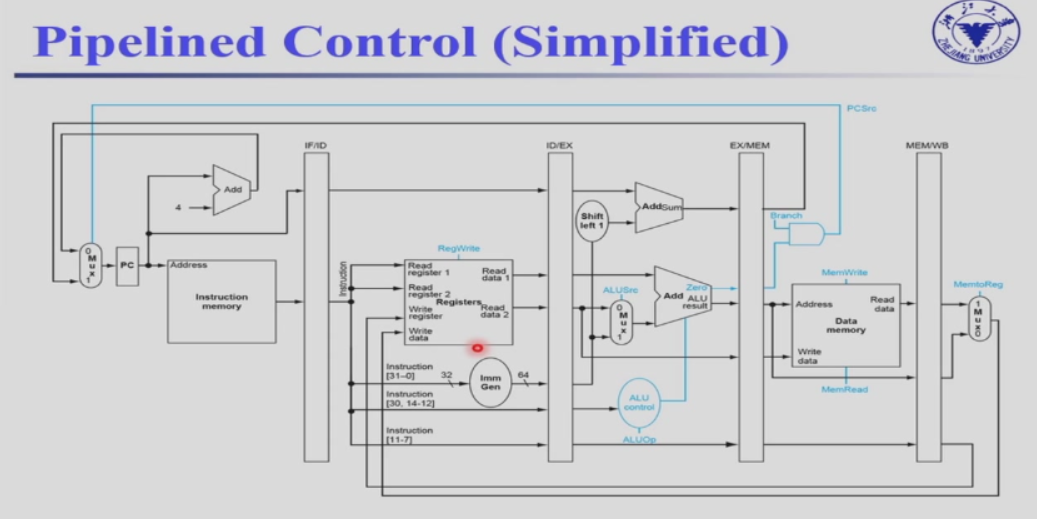
4.6.2 RISC-V Pipelined Datapath¶
不同阶段之间,我们需要寄存器来保存之前阶段得到的值。
竞争只会发生在从右往左的阶段(寄存器的写回,指令PC的跳转)。
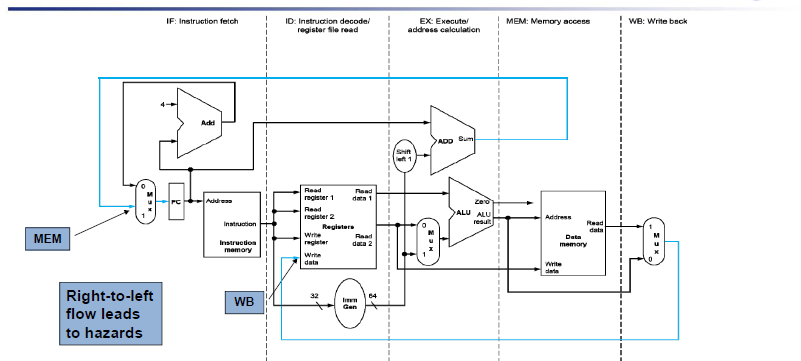
注意到,第五个阶段写回时,写寄存器号应该是从 MEM/WB 中的,而不是 IF 出的寄存器号。
-
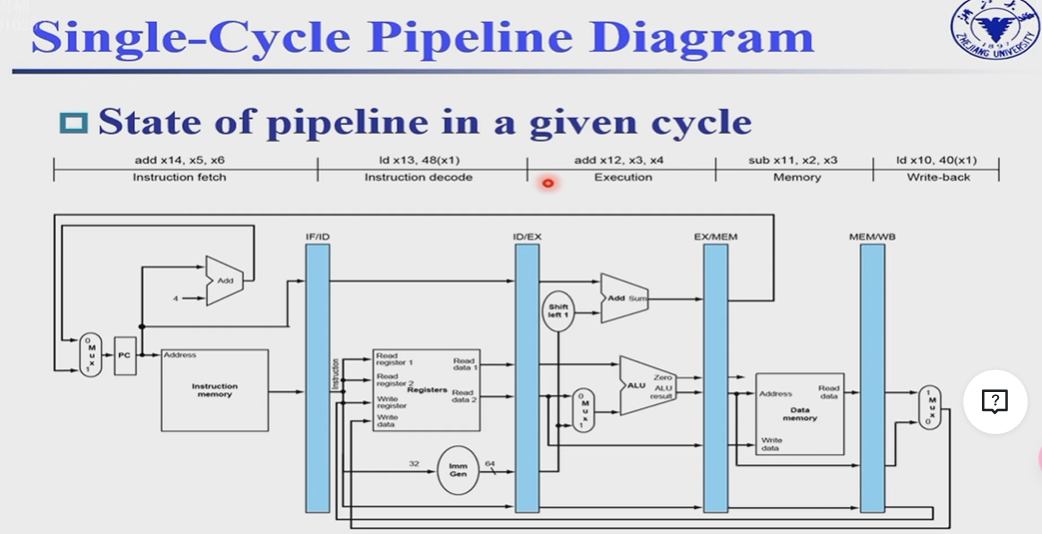
Single-clock-cycle pipeline diagram: Shows pipeline usage in a single cycle; Highlight resources used
一个周期一个周期地看
-
multi-clock-cycle diagram: Graph of operation over time
多个周期将多条指令从上到下放置比较
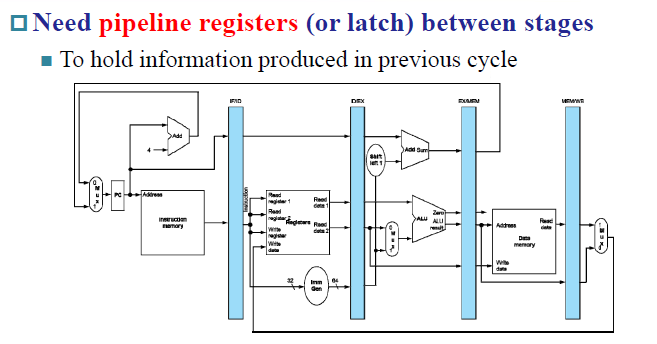
为流水线寄存器取名字,前后两个阶段的名字(IF/ID, ID/EX)
如IF/ID,需要保存PC(64位),instruction(32位)
ID/EX,需要保存PC(64),Rs1_data,Rs2_data(64),Imm(64)

阶段不是划分的越多越好,延迟会增加

Imbalance有一个阶段的时间特别长(浮点数计算的执行)
overhead流水线寄存器传输数据需要时间
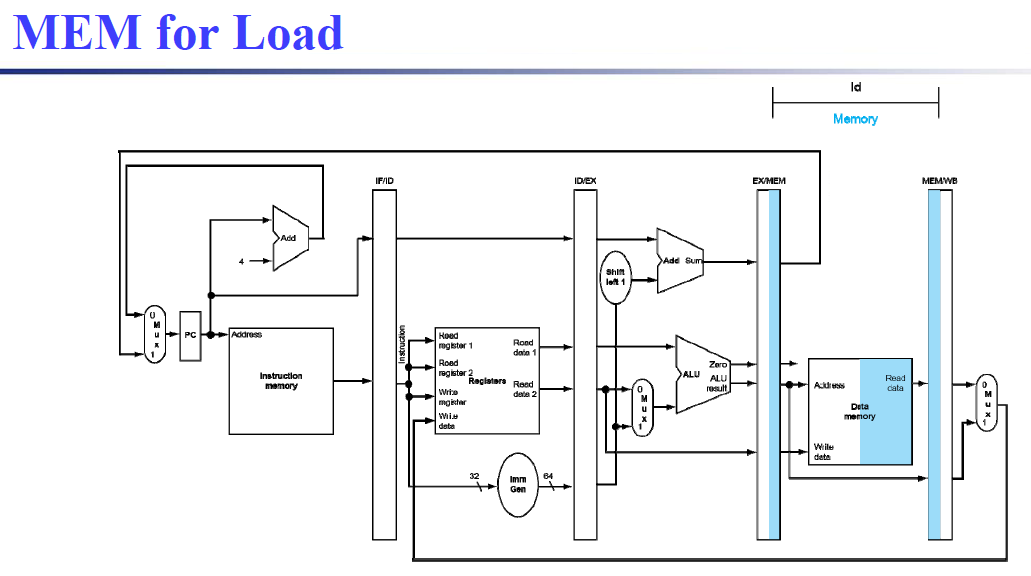
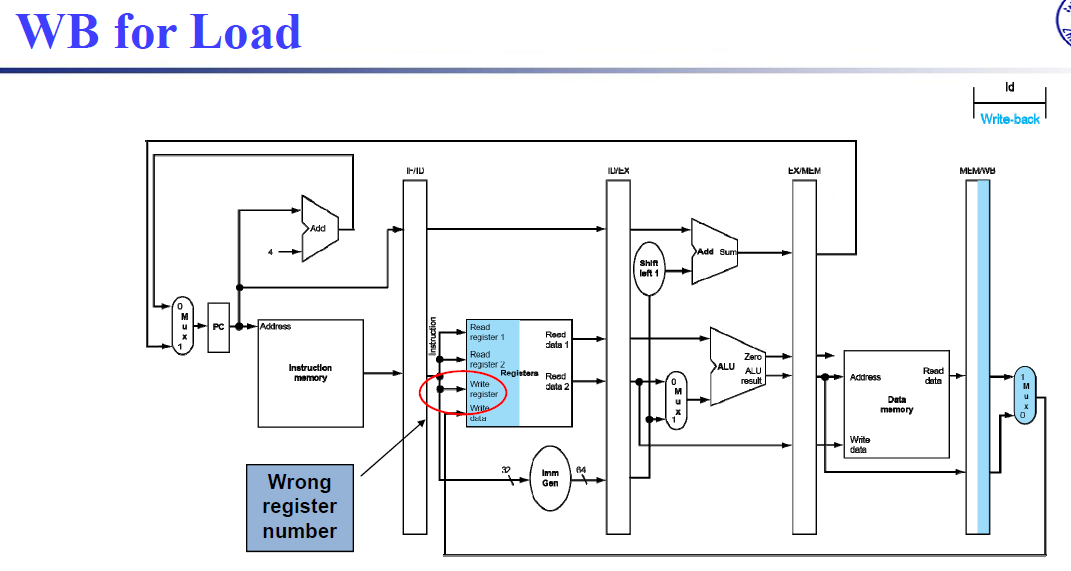
ID阶段的rd需要向后传递,一直到写回WB阶段,将rd传回到Register File,这样才能正确的写回寄存器
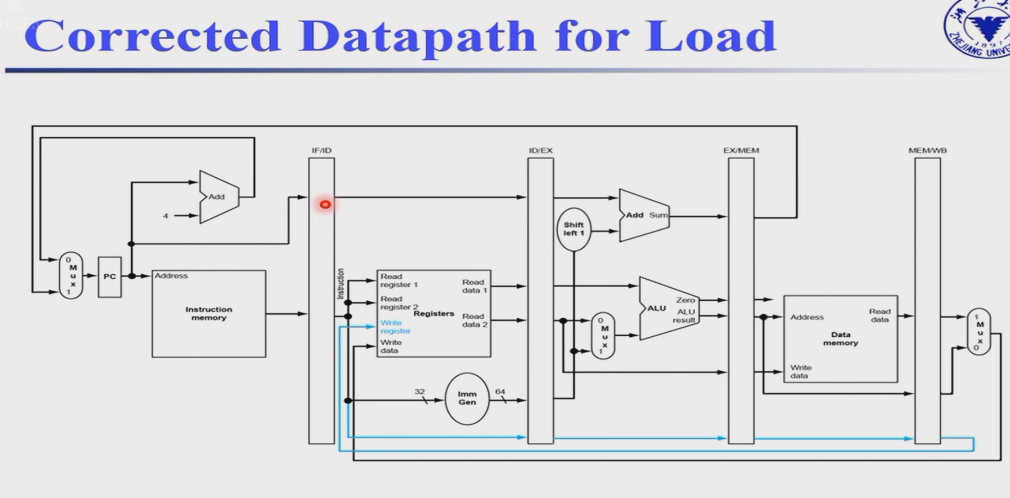

4.6.3 Pipeline Control¶

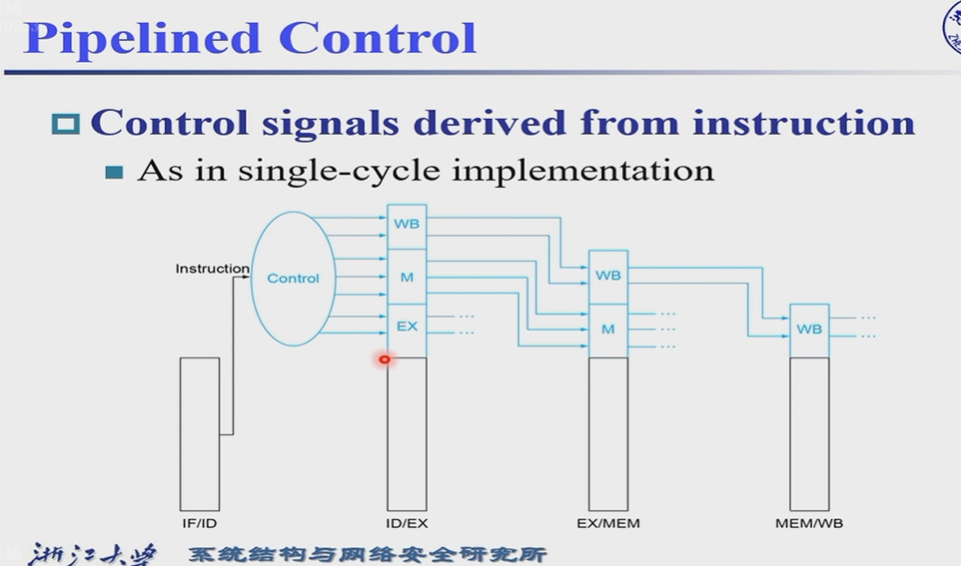
从Control中获得的control信号首先区分分别用于那个阶段,然后依次向后传导到指定阶段
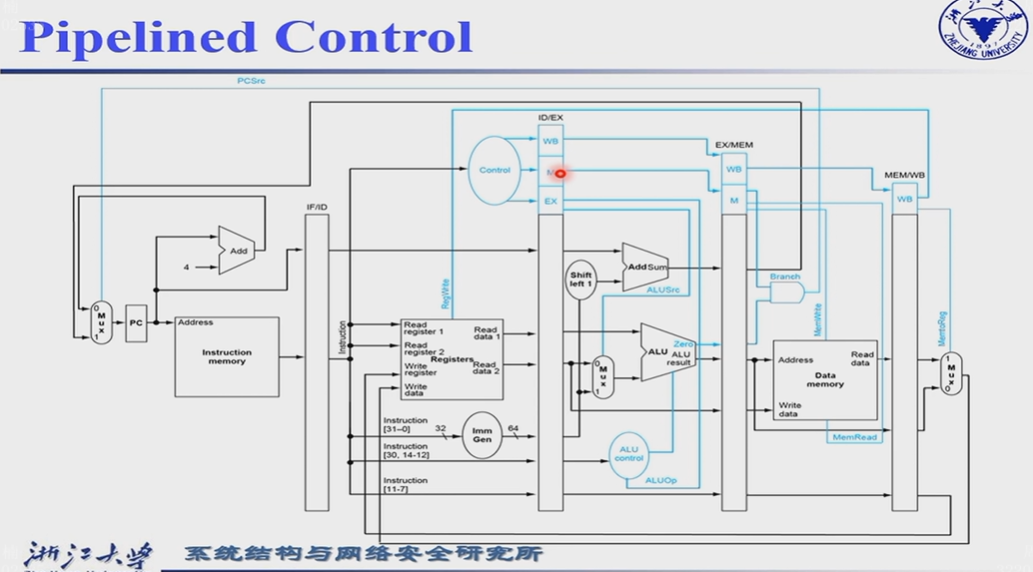
最终版本
4.7 Hazards¶
冒险/竞争 : Situations that prevent starting the next instruction in the next cycle
阻止在下一个周期中启动下一条指令的情况
当前这条指令不能进入下一个阶段,要等待。
-
Structure hazards
A required resource is busy.
-
Data hazard
Need to wait for previous instruction to complete its data read/write.
-
Control hazard
Deciding on control action depends on previous instruction.
4.7.1 Structure Hazards¶
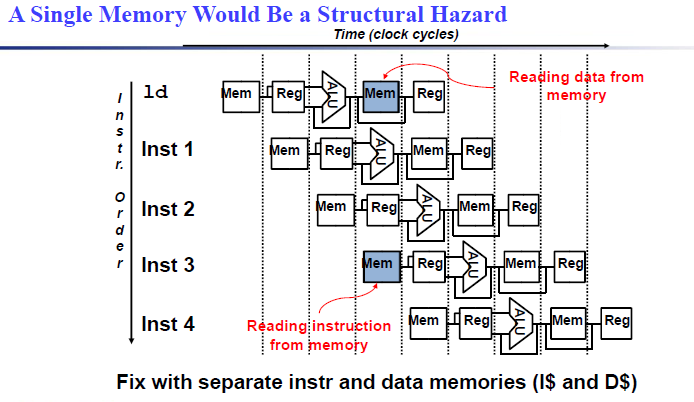
如果只有一块内存,但 IF 和 MEM 阶段都需要使用这块内存,那么 IF 就会被 stall 暂停,造成一个 bubble. (即流水线内有一个时刻是清空的,因为没有我们没有去取指令)
IF需要从内存中取出指令,load/store操作需要在MEM阶段将数据写入到内存或者从内存中读取数据
Pipelined datapaths require separate instruction/data memories. (Or separate instruction/data caches)
因此,你会发现instruction memory和data memory是分开的
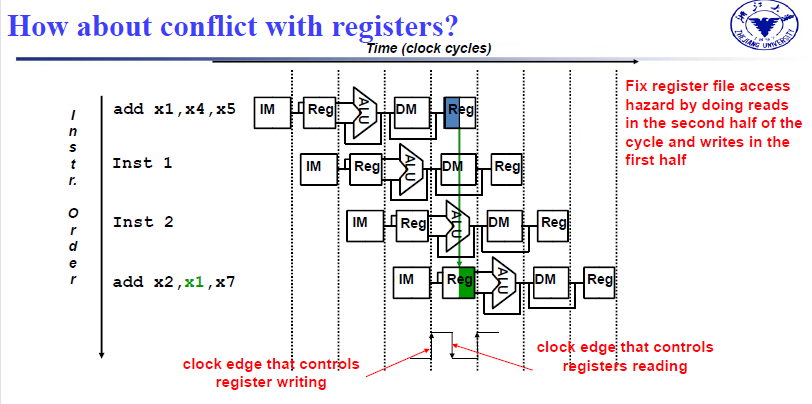
需要同时使用Reg,分别是将数据写入到目标寄存器和读取目标寄存器,先写后读,上升沿写,下降沿读(double bump)
需要相隔三条指令

停顿以解决hazard,可以插入空指令或者将后面的指令全部暂停

4.7.2 Data Hazards¶
An instruction depends on completion of data access by a previous instruction. 指令取决于先前指令完成数据访问
Example
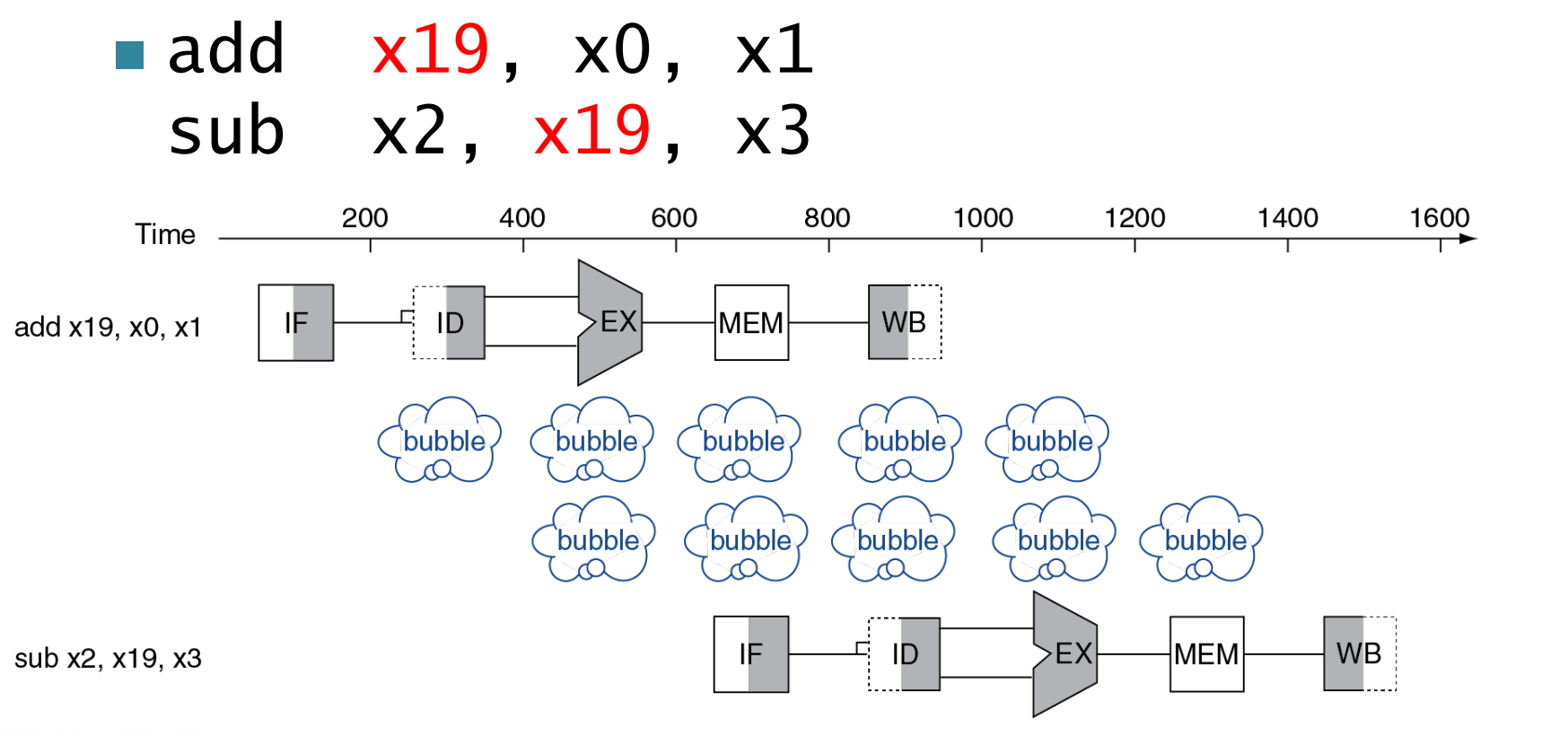
注意这里 WB 是在前半个周期将数据写入寄存器, ID 是在后半个周期将数据从寄存器中取出。时钟周期下降沿写入,上升沿读取
此处的bubble相当于NOP,什么都不执行,拖延两个时钟周期使得WB和ID在同一个时钟周期,但是写入在下降沿,读取在上升沿,读取建立在写入之后,从而解决data hazards
但实际上我们要用的结果在 EX 时已经产生了,且为了性能考虑,不允许使用两个bubble,于是使用一下的forward。
-
Forwarding(Bypassing)
Use result when it is computed
- Don’t wait for it to be stored in a register
- Requires extra connections in the datapath
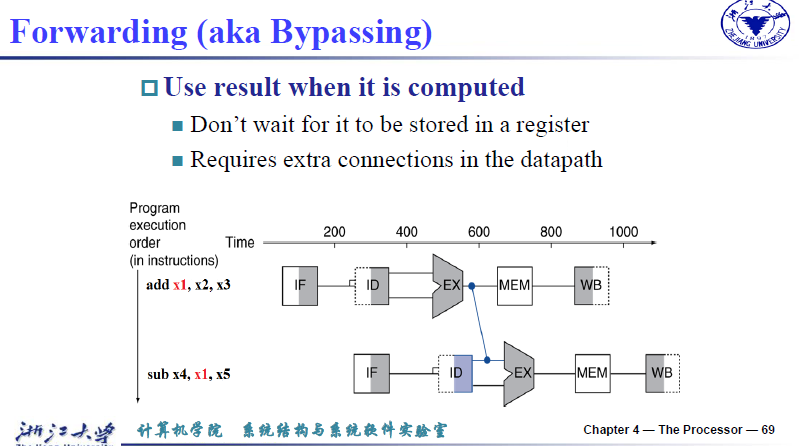
如上所示,add指令中x1的结果在EX阶段就产生,sub指令中x1在EX阶段被使用,我们只需要在数据通路中进行额外的连接,将add指令EX阶段产生的结果直接传输给sub指令EX阶段即可,这样一个bubble都不需要硬件上,ALU的数据来源需要增加,可能来源于前一条指令的ALU_result(对应EX/MEM寄存器),同时由于不加额外数据通路时,需要停两个bubble,所以还会受前一条指令的前一条指令的ALU_result影响(也就是MEM/WB寄存器)。所以ALU的数据来源一共包含:Register, Imm, EX/MEM, MEM/WB,相应的控制信号需要扩充,称之为Forward A/B

Load指令无法避免bubble,因为load指令只有将结果写入到目标寄存器后(或者说从内存中取出来)才能在下一条指令中得到使用,也就是说sub指令的x1需要在ld指令完成MEM阶段后才能使用。所以需要插入一个bubble,使得上一条的MEM和下一条的EX处于前后关系,再利用额外的数据通路进行传输
流水线的 CPI 不可能等于 1, 因为上图这种情况一定会发生(ld 无法避免)。
可以把后续与这些寄存器无关的指令先拿到这里执行。(乱序执行)

修改前,ld x2, 8(x31)需要一个bubble之后才能执行add x3, x1, x2
修改后, ld x2, 8(x0) 后续添加一条与当前发生指令无关的指令,代替原先的bubble,之后直接将x2传输给add指令的EX阶段 add x3, x1, x2 中去。
4.7.3 Control Hazards¶
Branch determines flow of control
-
Fetching next instruction depends on branch outcome
获取下一条指令取决于branch结果
-
Pipeline can’t always fetch correct instruction
流水线不能总是获取正确的指令
解决方法:1.将比较提前到ID阶段。2.预测是PC+4还是PC+imm
1.将比较提前到ID阶段,并且使用bubble
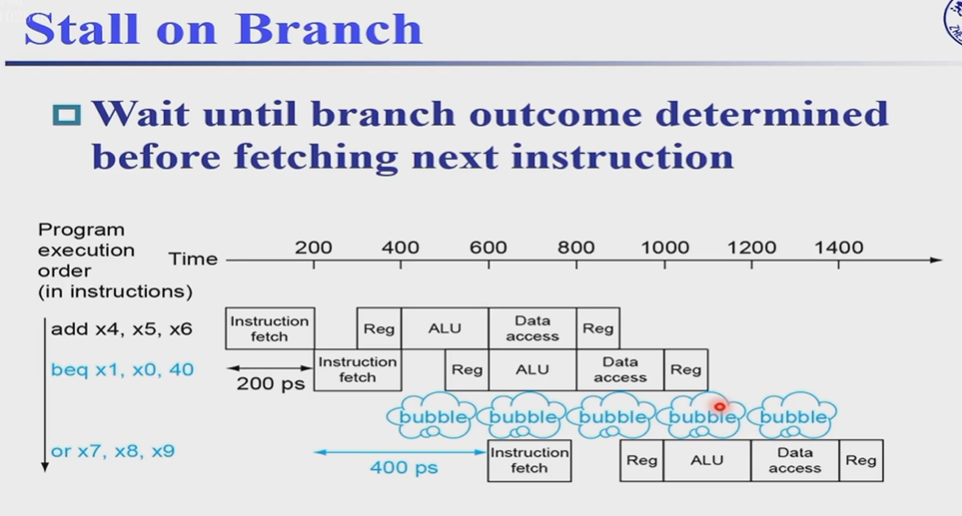
此处判断跳转与否(也就是下一条指令的PC),需要在branch指令完成比较判断之后,这一过程发生在ID阶段。所以下一台指令的instruction fetch需要发生在Reg之后,中间就需要使用一个bubble
2.Branch Prediction 预测是PC+4还是PC+imm
更长的流水线不能很早地决定分支结果。
可以预测 branch 命中或者不命中。
-
Static branch prediction
假设总是命中/不命中
-
Dynamic branch prediction
记录上次跑到这里是否命中,然后下次按照之前的结果预测。
Summary
Pipelining improves performance by increasing instruction throughput
流水线通过提高指令吞吐量来提高性能Executes multiple instructions in parallel
并行执行多条指令
Each instruction has the same latency
每条指令具有相同的延迟
Subject to hazards(Structure, data, control)
易受竞争harzardsInstruction set design affects complexity of pipeline implementation
指令集设计影响流水线实现的复杂性
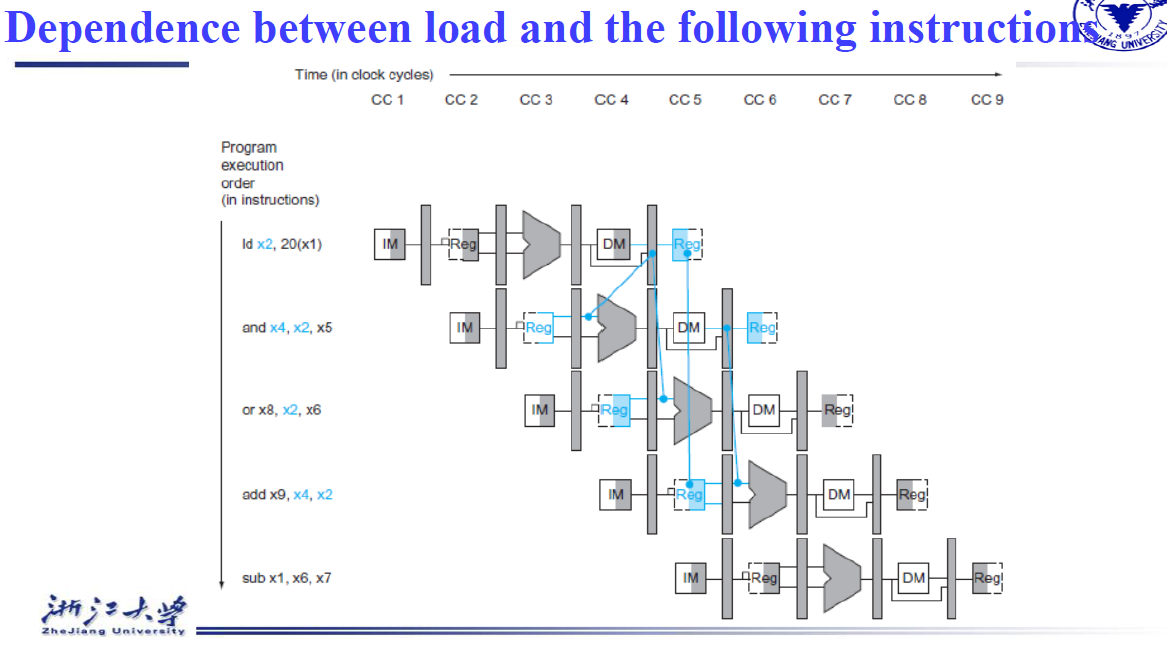
4.8 Data Hazards¶
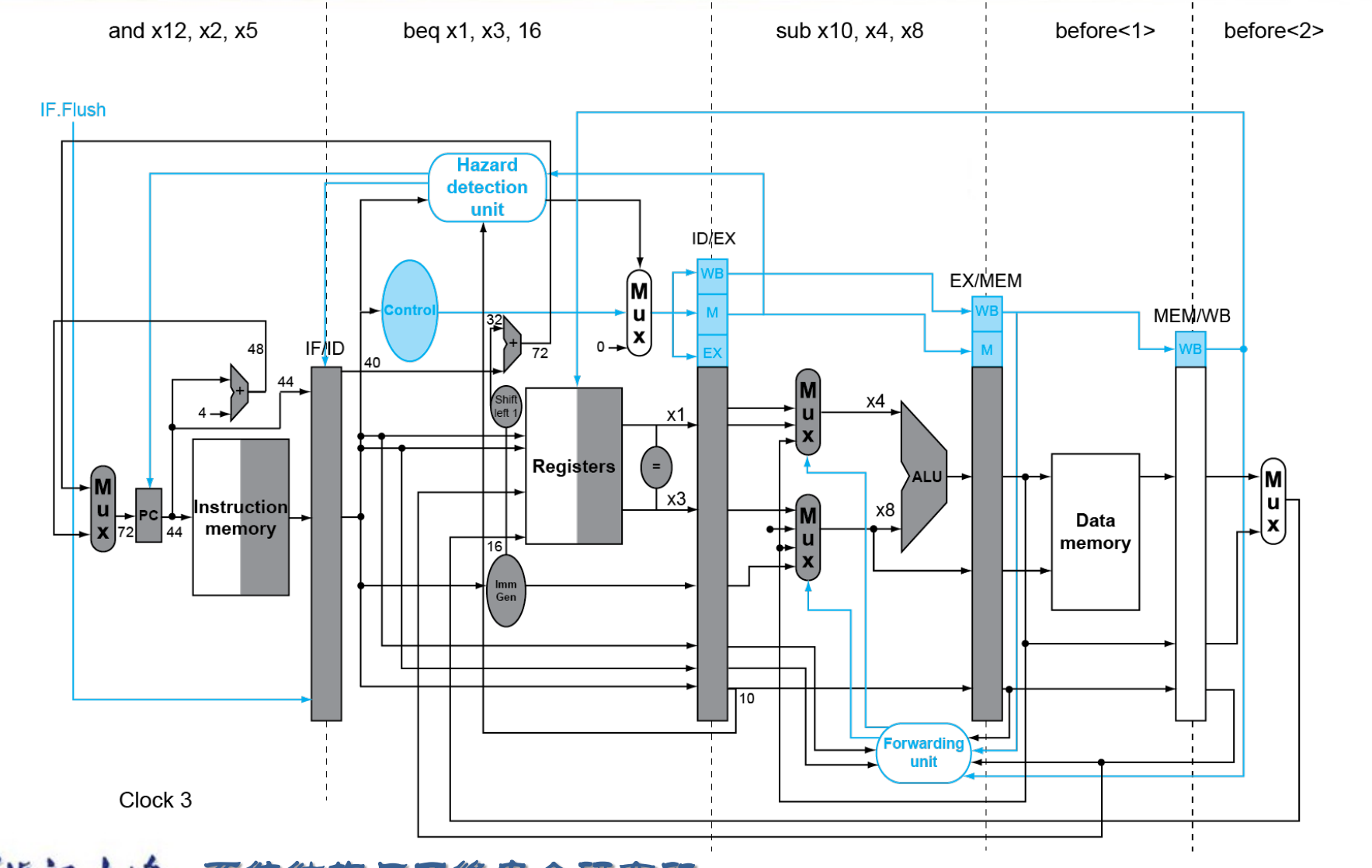
4.8.1 Forwarding¶
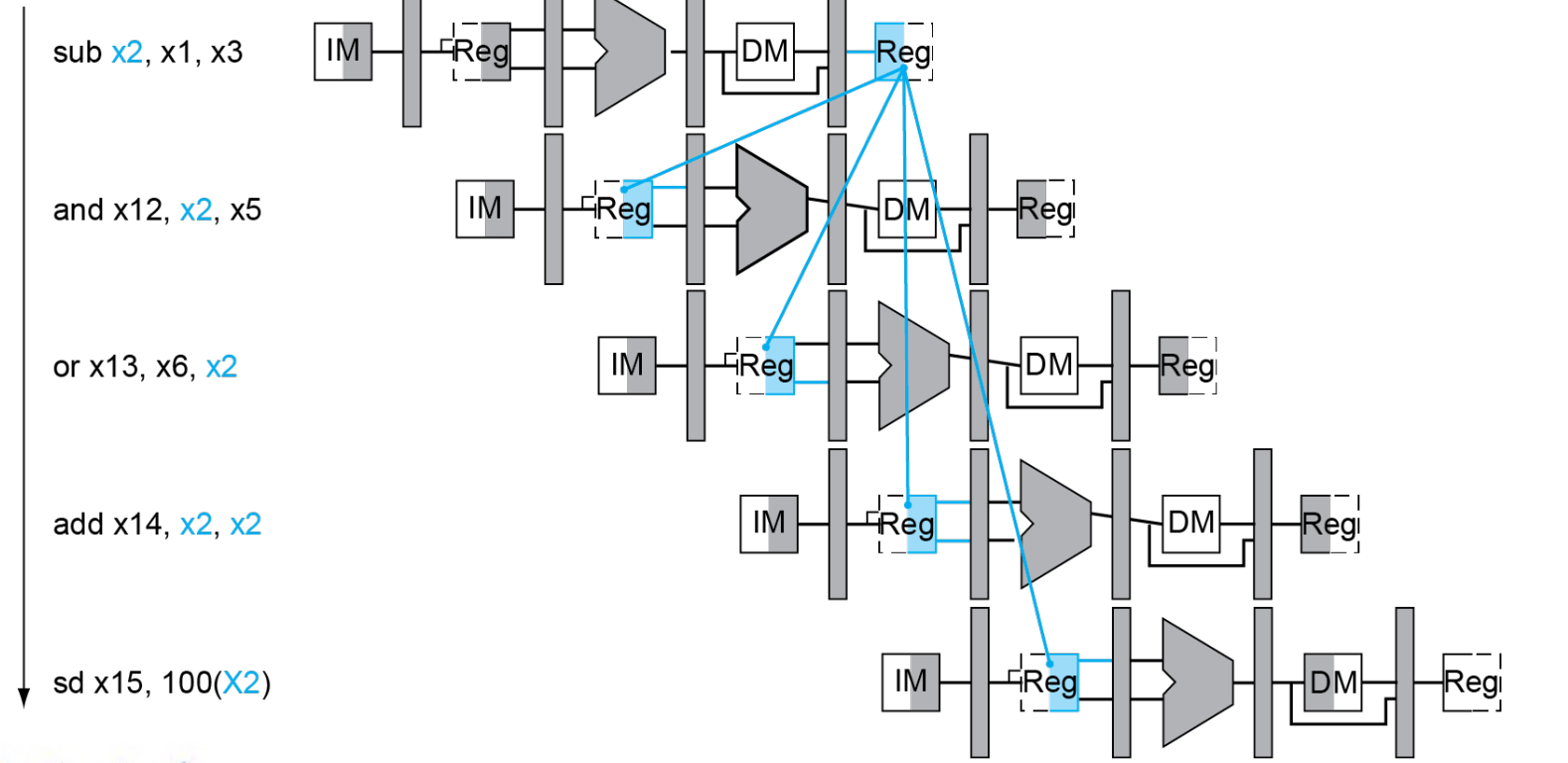
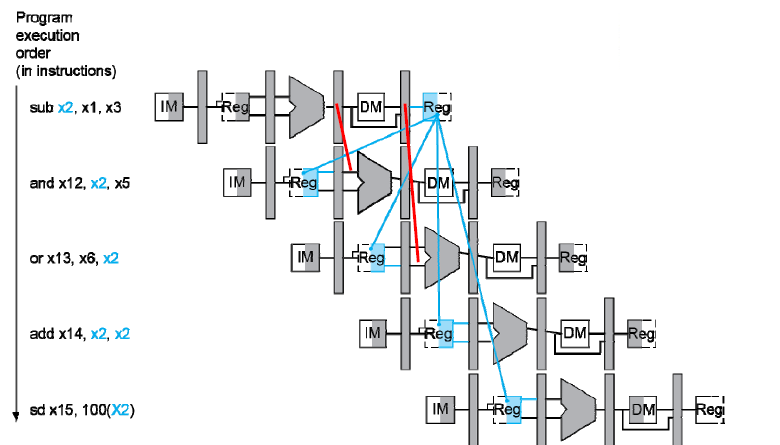
根据上面的多周期指令流程图,你会发现x2在重复使用,范式涉及到从右往左的都会发生data hazards。如果不添加额外的数据通路(上一条指令EX结束之后直接将结果传送到下一条指令EX开始之前,ld指令需要一个bubble,普通R型指令不需要bubble),需要使用两个bubble,恰好能够在下降沿写入数据,上升沿读取数据
如何判断是否需要前递?
判断当前指令所需读取的rs寄存器是不是上一条指令和上一条的上一条指令需要写入的rd寄存器

Data hazards when
-
-
EX/MEM.RegisterRd = ID/EX.RegisterRs1在第四个时钟周期时把 EX/MEM 的寄存器值送到 ALU.
-
EX/MEM.RegisterRd = ID/EX.RegisterRs2 -
MEM/WB.RegisterRd = ID/EX.RegisterRs1 -
MEM/WB.RegisterRd = ID/EX.RegisterRs2
-
-
只有在我们要使用在前面指令值发生改变的寄存器的值的时候,data hazard才会发生(有些指令可能根本就不会写回寄存器,没有有效的 Rd)
-
此外
EX/MEM.RegisterRd, MEM/WB.RegisterRd也不能为 0.
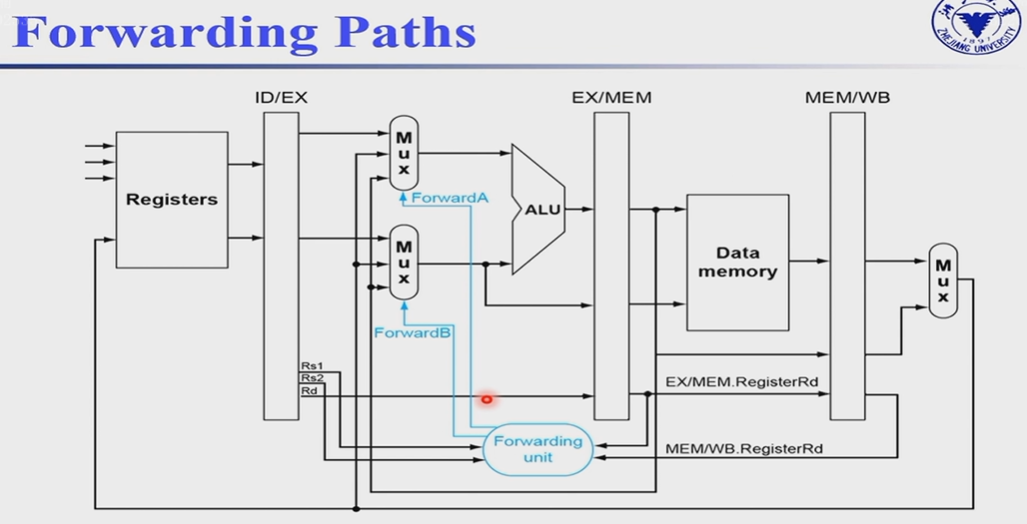
Forwarding unit用于detect data hazards,所以需要读入ID/EX的Rs1,Rs2,EX/MEM和MEM/WB的Rd,同时还需要EX/MEM的RegWrite,MEM/WB的RegWrite。
如果Rs1/Rs2都不等于上述两个Rd,意味着不发生data hazard,所以forwardA = 00,表示选取register file或者imm
| Mux control | Source | Explanation |
|---|---|---|
ForwardA = 00 |
ID/EX | The first ALU operand comes from the register file. |
ForwardA = 10 |
EX/MEM | The first ALU operand is forwarded from the prior ALU result. |
ForwardA = 01 |
MEM/WB | The first ALU operand is forwarded from data memory or an earlier ALU result. |
Example "Double Data Hazard"
既有可能EX/MEM.RegisterRd = ID/EX.RegisterRs1,又有可能MEM/WB.RegisterRd = ID/EX.RegisterRs1
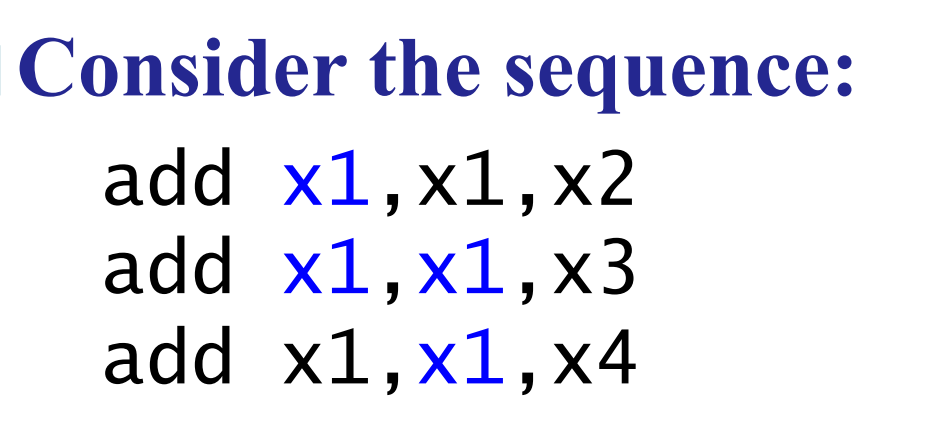
第三条指令的rs和前两条指令的rd都相等。那优先选择最新的结果,也就是上一条指令的ALU_result,所以需要优先判断EX/MEM RegisterRd是不是等于ID/EX RegisterRs
我们前递时要加一个条件,只有在 EX/MEM 的条件不成立时,才能查看 MEM/WB 的条件。

MEM hazard
if( MEM/WB.RegWrite == 1
and MEM/WB.RegisterRd != 0
and MEM/WB.RegisterRd == ID/EX.Register1/2
and (EX/MEM.RegWrite == 0 or EX/MEM.RegisterRd == 0 or EX/MEM.RegisterRd != ID/EX.RegisterRs1/2))
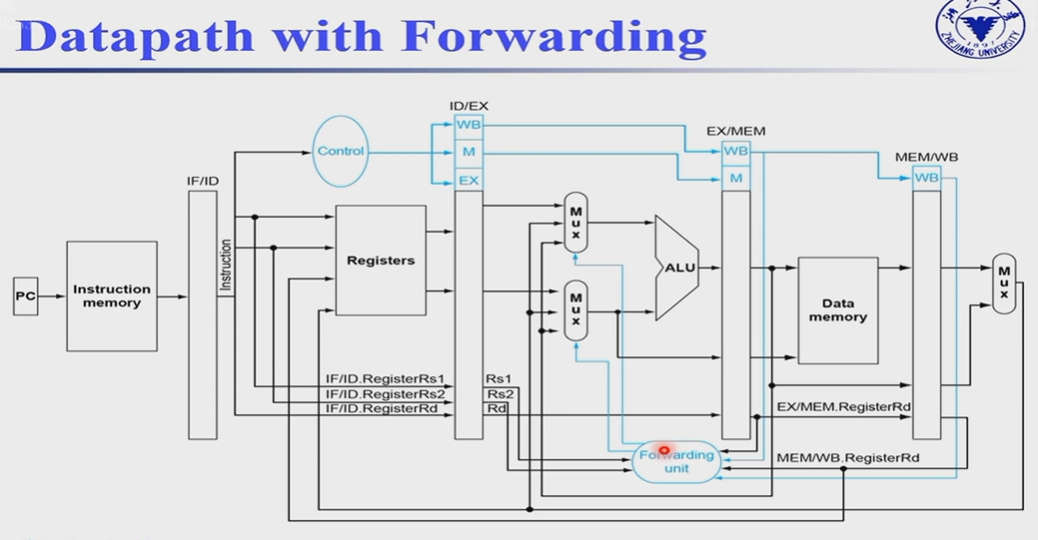
与ALU相关的data hazard,添加一个forwarding unit,更新ALU的mux
store相关的data harzard,add x5,x2,x3 store x5, 0(x6).store指令执行MEM阶段时,EX/MEM只能计算出store的地址,但是store的值x5还没有写入到x5,所以需要添加forward(额外数据通路),将MEM/WB的ALU_result传递给MEM的write_data.
相应的Store相关的data hazard,也需要一个forwarding unit,并且在data memory的write_data前面加上mux。data hazard的条件是 memWrite = 1, 且EX/MEM的Register Rs2与上一条指令MEM/WB的rd相等
4.8.2 Load-Use Hazard Detection¶
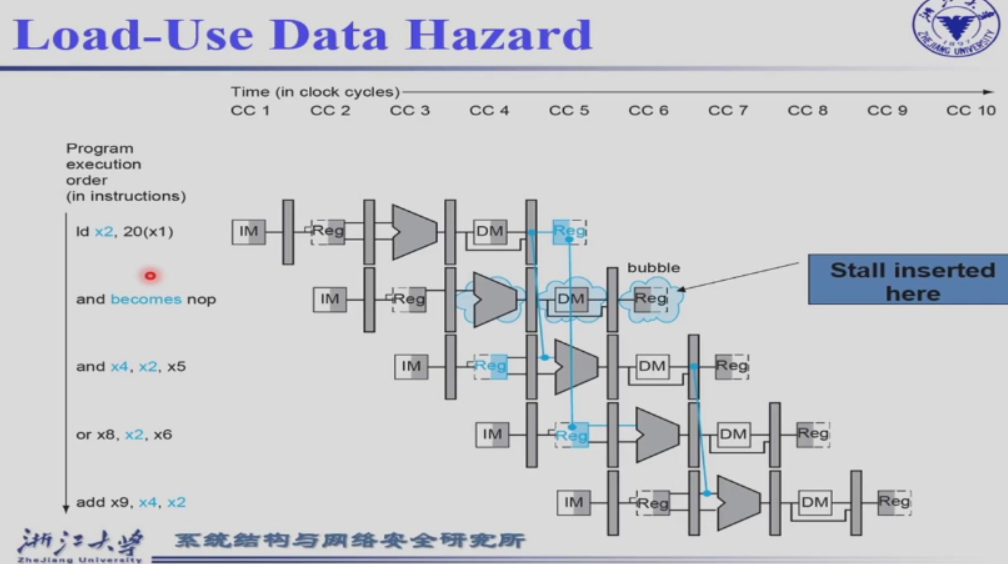

为什么是ID/EX.RegisterRd = IF/ID.RegisterRs1呢?因为load指令存在WB环节,RegisterRd需要在load指令中层层传递一直到WB环节将RegisterRd传回到后面指令的IF/ID阶段(在该阶段完成目标寄存器的写入)。一旦发生ID/EX.RegisterRd = IF/ID.RegisterRs,说明当前指令的源寄存器与上一条指令的目标寄存器存在数据冲突
如果我们在 ld 指令 EX/MEM 时暂停,此时 ld 后面有两条指令需要暂停,其实我们可以更早的发现这个问题(也就是ID/EX阶段)。
Load-use hazard when
(ID/EX.MemRead == 1)
and ((ID/EX.RegisterRd = IF/ID.RegisterRs1)
or (ID/EX.RegisterRd = IF/ID.RegisterRs2))`
If detected, stall and insert bubble
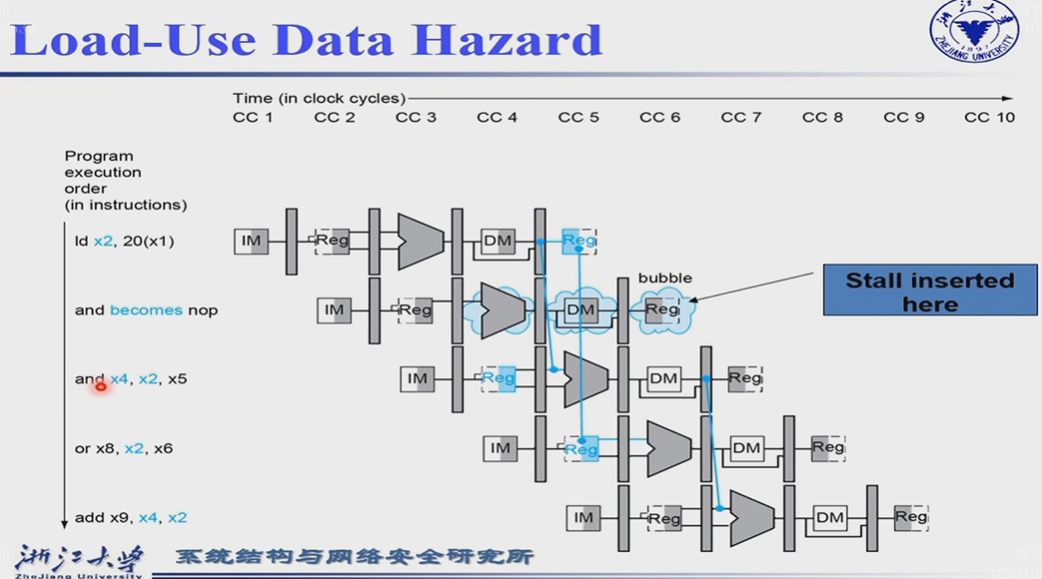
第一条指令和第二条指令之间必须添加一个Bubble
第一条指令和第三条指令之间通过forward实现(流水线,前提是没有bubble)
第一条指令和第四条指令之间刚好(隔两条指令),Reg先写后读

加加条件检查load的hazard
插入bubble意味着bubble指令不执行任何操作,于是让所有在ID/EX Register中的控制信号为0,IF/ID 寄存器不变,这样后续EX,MEM,WB阶段都不执行任何操作
同时还需要防止更新PC和IF/ID寄存器,重新获取load指令后面的那一条指令,重新decode
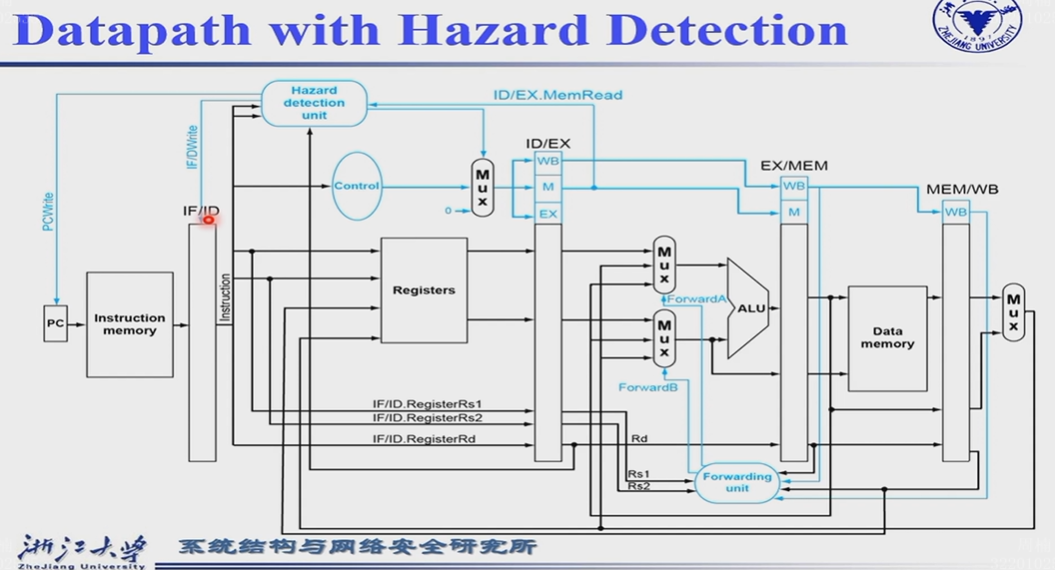
添加一个Hazard detection unit,输入ID/EX.MemRead(区分R型指令,增加了从内存中读取数据的MEM阶段), ID/EX.RegisterRd, IF/ID.RegisterRs1/2
输出结果包括PCWrite控制PC是否改变,IF/ID Write控制下一条指令是否decode,另外一个控制信号输送到ID/EX寄存器前的Mux,一旦发生data hazard,就把ID/EX寄存器中的控制信号全部置为0

4.8.3 Stalls and Performance¶
- Stalls reduce performance
- But are required to get correct results
- Compiler can arrange code to avoid hazards and stalls


- double bump 寄存器先写后读
- forward 前递
- compiler scheduling 编译器调度,调整指令的顺序,减少出现stall
- Stall
4.9 Branch Hazards¶
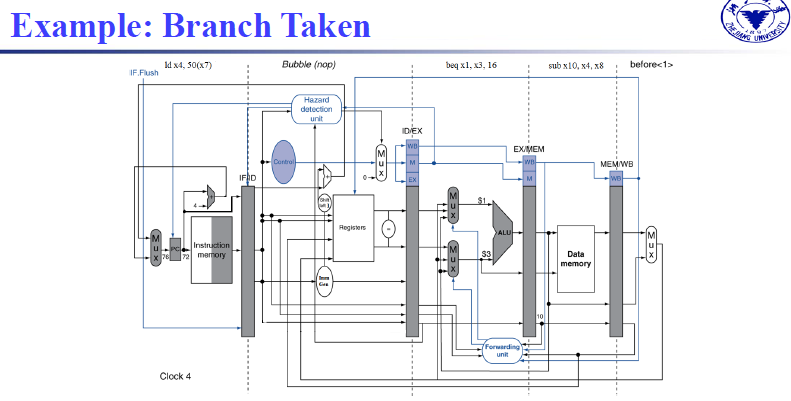
决定是否跳转发生在MEM环节,此环节Branch控制信号和ALU_zero信号共同决定PC是否等于PC+imm。
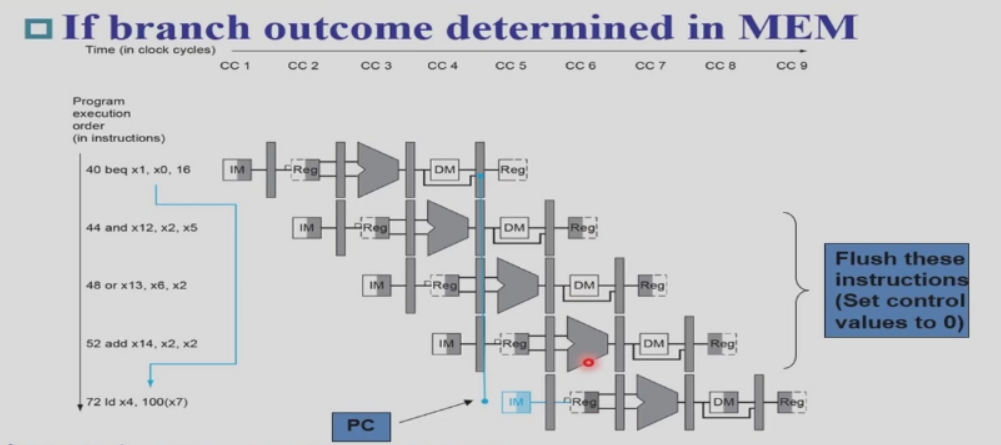
观察上图发现,branch指令在MEM阶段决定是否跳转,决定PC是否等于PC+imm。真正发生跳转已经达到WB阶段(执行最新的PC指令),那么对应的中间就相隔三条指令,意味着这三条指令应当不能执行,需要将它flush掉,
设置所有的控制信号为0.中间的三条指令是否产生影响,关键在于是否改变了寄存器,是否在内存中发生了写入
-
最朴素的方法是无视这种情况,因为前三个阶段并不涉及对寄存器和内存修改,即使我们预测后续不执行这些指令也不会带来影响。但这样可能带来 CPI 的显著增加。
此处是想说明:当Branch执行到MEM阶段时,后面三条指令执行到的阶段分别为EX,ID,IF,并不会发生修改内存中的数据(MEM)和修改寄存器的值(WB)的操作,所以并不会带来什么负面影响, -
一种方法是在 ID 级决定是否跳转(此时已经有了两个源操作数和立即数)

4.9.1 stall¶
-
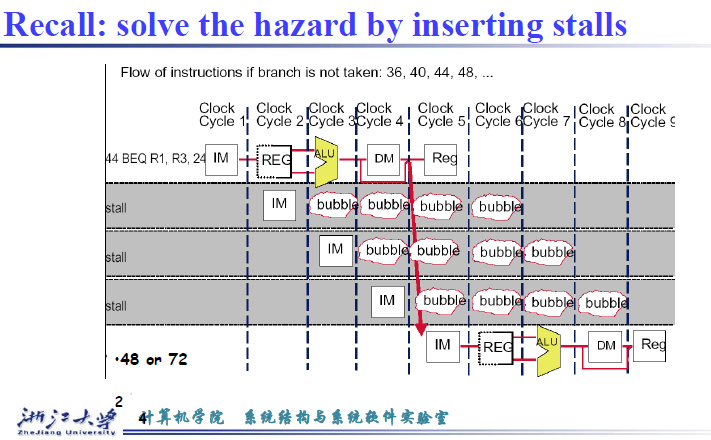
Flushing the pipeline
让后面三条指令的控制信号为0即可,stall -
problem:With a 30% branch frequency and an ideal CPI of 1, how much the performance is by inserting stalls ?
Answer: \(CPI = 1+ 0.3 \times 3=1.9\)
 、
、
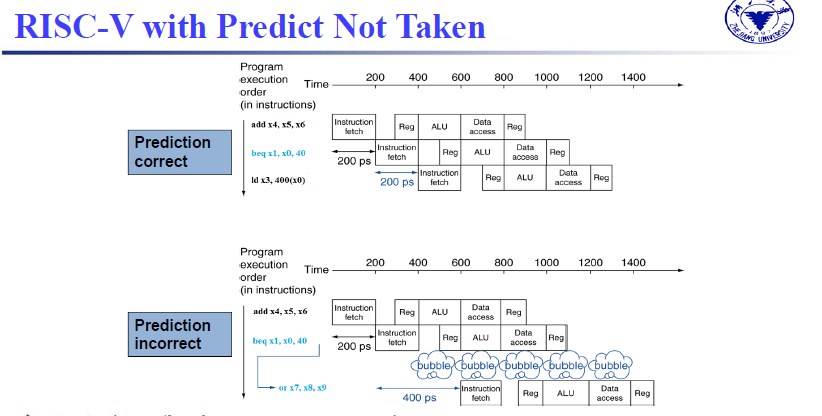
4.9.2 Predict-untaken/taken¶
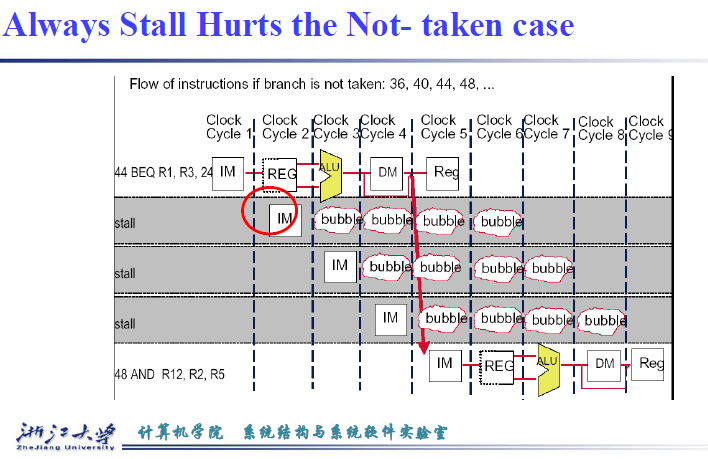
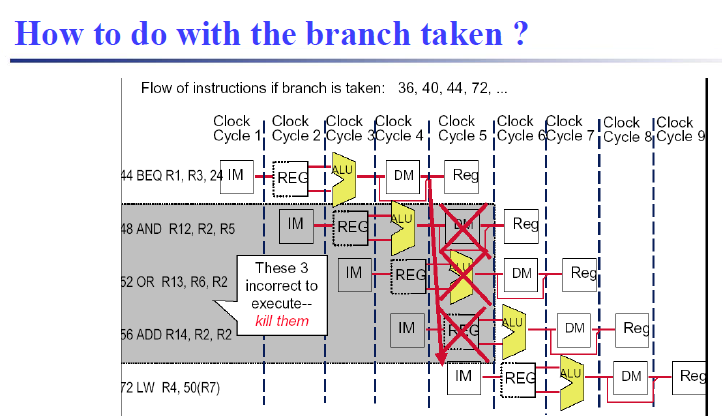
假定始终不跳转,发现错误后,将额外执行的三条指令冲掉

最新的CPI就是,只需要计算跳转的branch指令带来的额外CPI $$ CPI = 1 + br\% \times take \% \times 3 $$
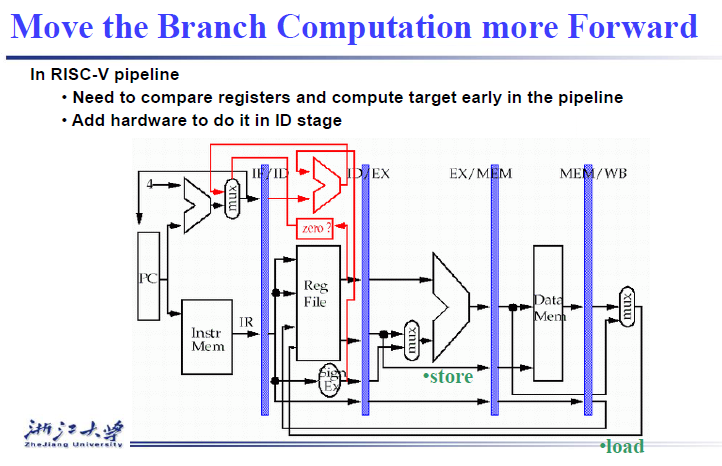
branch_signal计算提前到ID阶段,添加ALU计算出跳转地址,比较Rs1和Rs2的值

提前计算branch_signal,原先决定是否跳转发生在MEM阶段,现在决定是否跳转发生在ID阶段,减少了中间的EX和MEM阶段,这意味着两个指令能够得到释放,只需要添加一个bubble,减少branch的delay
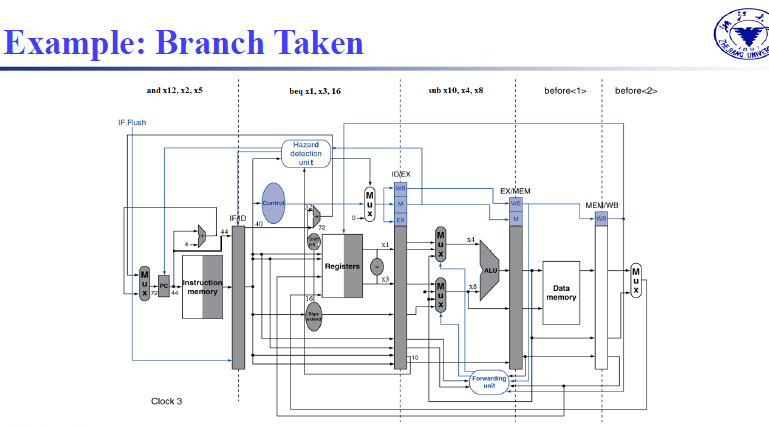

ld x1, addr
add x4, x5, x6
beq stalled
beq x1, x4, target
需要在beq指令之前添加一个stall。因为beq指令需要的源寄存器是ld指令的目标寄存器。所以需要等到ld完成WB之后才能进行beq的instruction decoder。
因此ld指令的WB阶段和beq指令的ID阶段对应,执行先写后读的操作。两者需要相差MEM,EX阶段,对应的就需要两条指令作为间隔,除去add指令外,还需要一个bubble
ld x1, addr
beq stalled
beq stalled
beq x1, x4, target
load和branch挨着,需要停两个bubble
4.9.3 Static branch prediction¶
一般用于for循环,直接假设所有的branch指令都不跳转或者都跳转。
4.9.4 Dynamic Branch Prediction¶
In deeper and superscalar(多发射) pipelines, branch penalty is more significant.
Use dynamic prediction.
- Branch prediction buffer (aka branch history table)
记录前几次是否命中
-
Indexed by recent branch instruction addresses
-
Stores outcome (taken/not taken)
-
To execute a branch
- Check table, expect the same outcome
- Start fetching from fall-through or target
- If wrong, flush pipeline and flip prediction
动态预测,看前一次branch是否taken,如果发生就预测本次也发生,不发生就预测本次也不发生。可以处理 for 循环的预测。
建立一个branchprediction buffer,跳转预测缓冲区,用最近的branch指令地址为索引,存储taken或者not taken。当执行branch指令时,检查table,取最近的branch结果作为预测。
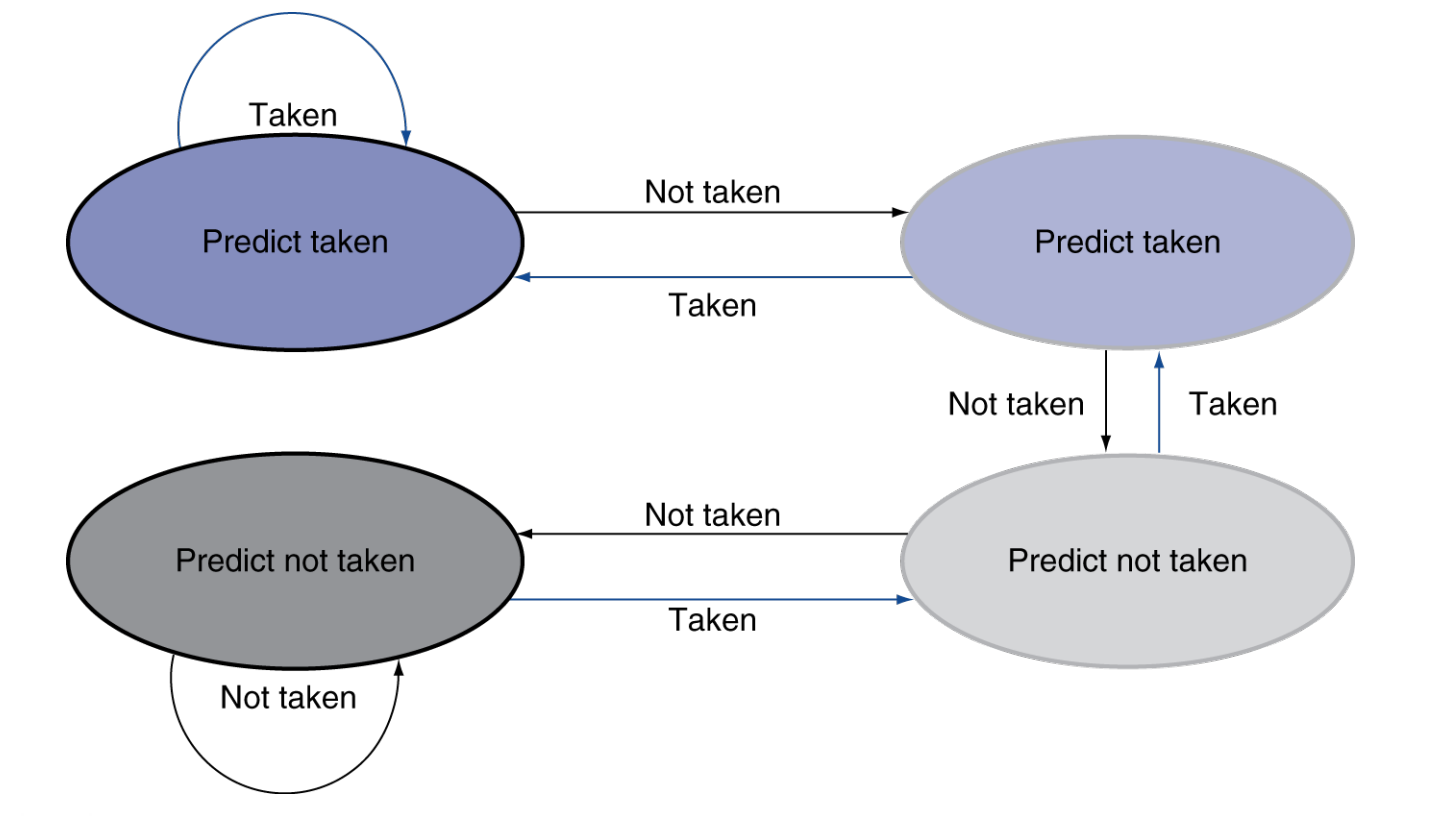
Note "1-Bit Predictor"
但也存在问题,对于双层循环,当内层循环要结束时会错两次。
对应情形为:在内循环的最后一次操作,按照前一次的预测,需要继续跳转,但是实际上应当返回到外循环(也就是顺序执行i=i+1),预测错误。之后需要从外循环跳转到内循环,按照前一次的预测,不执行跳转,但是实际上应该跳转,所以预测错误。发生两次预测错误
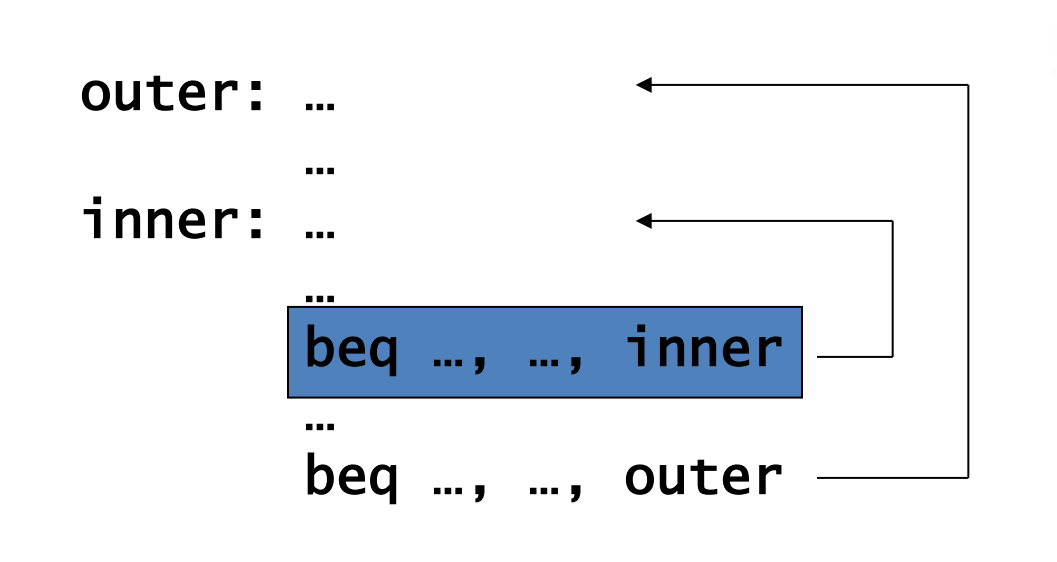
-
Mispredict as taken on last iteration of inner loop
错误预测,如内循环的最后一次迭代
-
Then mispredict as not taken on first iteration of inner loop next time around
可以修改预测方式:只有连续错误两次才会修改我们的预测。即 2-Bit Predictor.
Calculating the Branch Target
即使 branch 命中了,我们也有一个时钟的 bubble 来计算地址。
但 branch 要跳转的地址其实是可以存下来的。
Branch target buffer
-
Cache of target addresses
存储最近最新用到的,老的会被删除 -
Indexed by PC when instruction fetched 获取指令时由 PC 索引
If hit and instruction is branch predicted taken, can fetch target immediately
如果命中并预测分支采取指令,则可以立即获取目标
4.10 Exception in pipeline¶
4.10.1 Single Exception¶
流水线的异常类似于Control Hazards,流水线的异常需要flush掉异常发生时所有会改变内存或者寄存器的指令。
如果overflow发生在add指令的EX阶段(add x1,x2,x1),该怎么办?
- Prevent x1 from being clobbered 防止 x1 value发生改变
- Complete previous instructions 完成add指令之前的指令
- Flush add and subsequent instructions 将add指令和add指令之后的指令全部flush掉
- Set Cause and SEPC register values 设置Scause和SCEP,进入异常解决
- Transfer control to handler 将控制权交给处理程序
Pipeline can flush the instruction
Handler executes, then returns to the instruction
- Refetched and executed from scratch 从头开始重新获取和执行
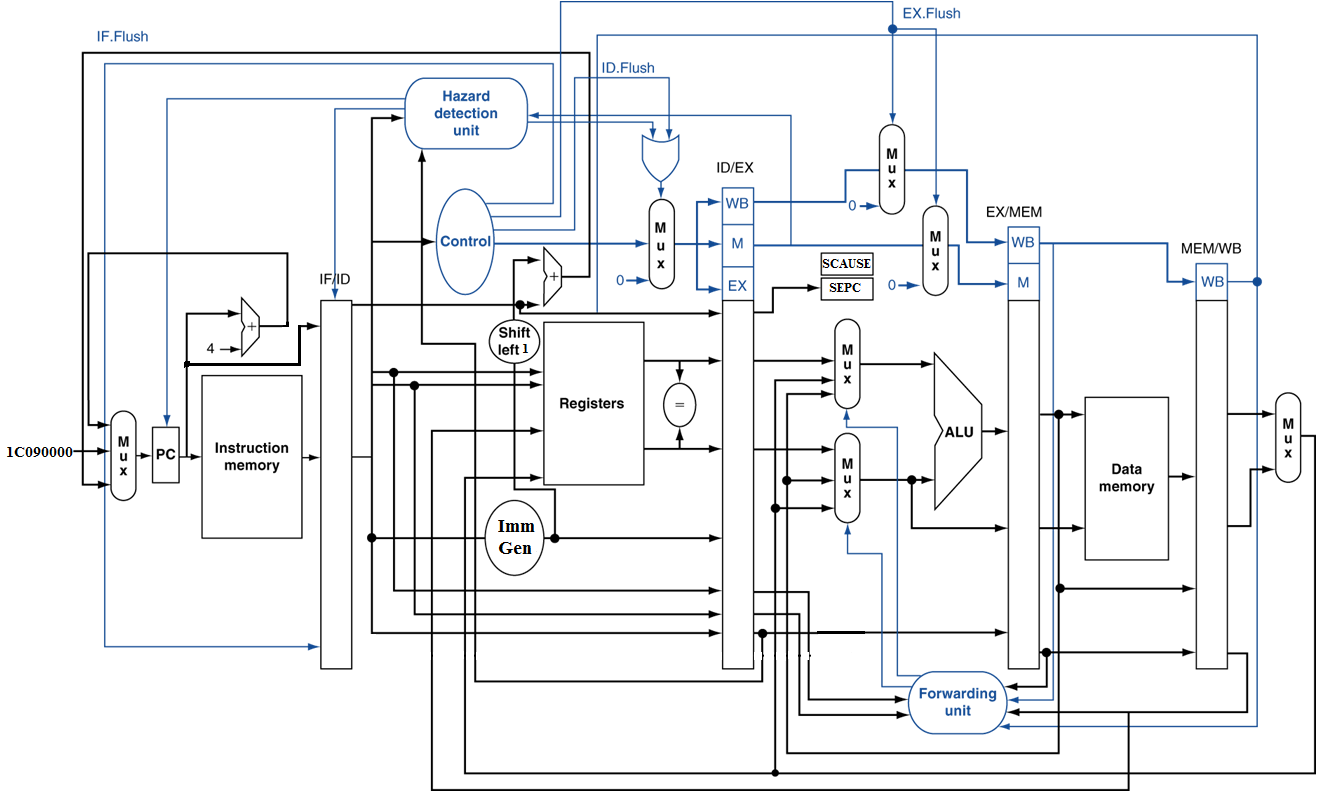
发现PC是从ID/EX寄存器传输给SEPC的,说明PC随着流水线依次传递。因为此时add处于EX阶段,说明add的下一条指令位于ID阶段,再下一条指令位于IF阶段,存在Branch指令的可能,PC的值变为PC+imm,此时如果PC不依次传递,无法通过当前PC的值计算出add对应的PC值
example

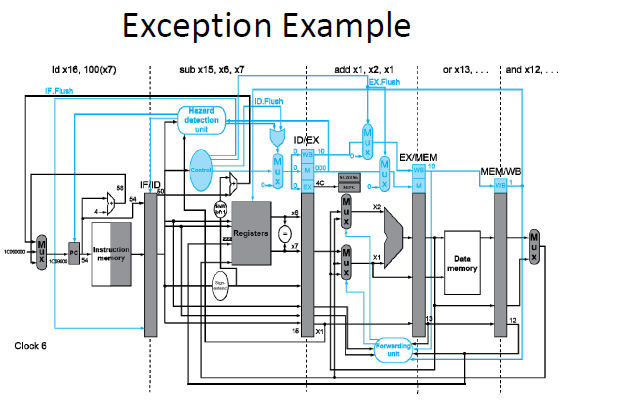
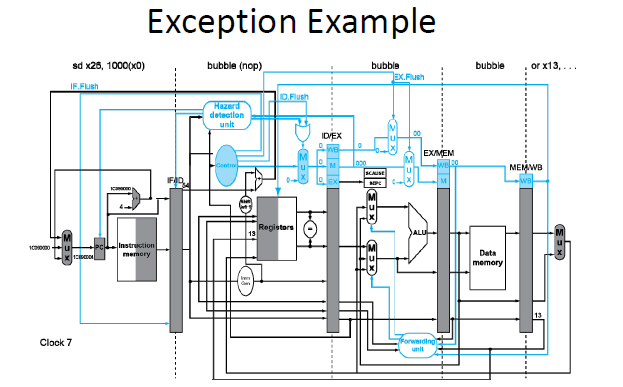
一旦异常发生,首先你会看到PC的mux增加了一个输入,1C090000,也就是解决程序的初始地址,需要跳转到该地址。
执行flush操作,将add指令和后面的sub,ld指令全部变为bubble。or指令在add指令之前所以依然执行。将add指令的地址4C存到SEPC中。
指令非法在IF阶段就可以判别进行处理,外部中断的话,将流水线的所有指令处理完毕之后再处理中断
4.10.2 Multiple Exxceptions¶
Pipelining overlaps multiple instructions
-
Could have multiple exceptions at once
五级流水线,包含多条指令,存在多条指令同时发生异常的情况Simple approach: deal with exception from earliest instruction
-
Flush subsequent instructions
-
“Precise” exceptions
解决方法:精确处理。优先解决最早发生的指令的异常(指令的完成顺序和发生顺序相同),flush掉异常指令后续的指令(异常也随之解决)。
In complex pipelines
-
Multiple instructions issued per cycle
-
Out-of-order completion
-
Maintaining precise exceptions is difficult!
但是复杂流水线中,存在着一个时间周期存在多条指令,以及指令的乱序完成(完成顺序不依照开始执行顺序),导致prrcise exception的解决方法很难执行
此时只能执行 imprecise Exception

发生中断时,怎么处理由中断处理程序决定,这就导致硬件部分得到简化,但是软件部分复杂化