5. Large and Fast: Exploiting Memory Hierarchy¶
约 7666 个字 预计阅读时间 38 分钟
Abstract
- Memory Technologies
- Memory Hierarchy Introduction
- The basics of Cache
- Measuring and improving cache performance
- Dependable Memory Hierarchy
- Virtual Machines
- Virtual Memory
- A common Framework for Memory Hierarchy
- Using FSM to Control a simple Cache
5.1 Memory Technologies¶
-
SRAM
-
value is stored on a pair of inverting gates
-
very fast but takes up more space than DRAM
值存储在一对反相门上,速度非常快,但占用的空间比DRAM多

-
-
DRAM
-
value is stored as a charge on capacitor (must be refreshed)
-
very small but slower than SRAM (factor of 5 to 10
值存储为电容器上的电荷(必须刷新),非常小,但比 SRAM 慢(系数为 5 到 10)需要周期性的刷新
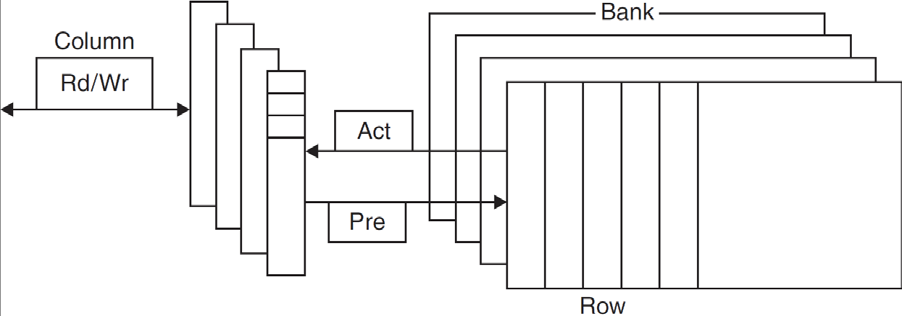
bank用于加快数据读取的速度,类似胡并行读取。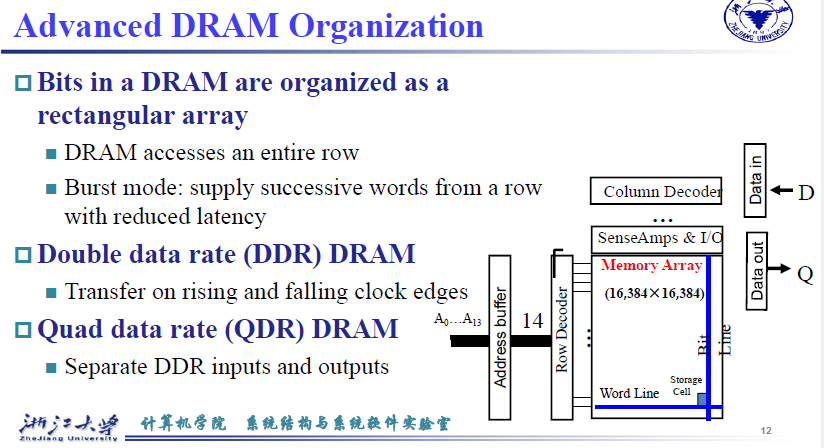
Burst mode:supply successive words from a row with reduced latency
在读取连续的数据时能够减少延迟,seek的次数和时间减少DDR:上升沿和下降沿都取数据 \(\Rightarrow\) 速度翻倍

Row buffer:每一行都放到buffer中
Synchronous DRAM:时钟同步
DRAM banking:分成多段,每一个bank都读取
-
见计逻部分

5.2 Memory Hierarchy Introduction¶

Programs access a small proportion of their address space at any time
-
Temporal locality 时间局部性
Items accessed recently are likely to be accessed again soon
最近访问的项目可能很快就会再次访问
如 for 循环,跑过一次后我们大概率还要执行循环体里的代码
-
Spatial locality 空间局部性
Items near those accessed recently are likely to be accessed soon
最近访问的项目附近的项目可能很快就会被访问
如数组,我们访问了这个元素后大概率还要访问后面的元素
利用局部性:
-
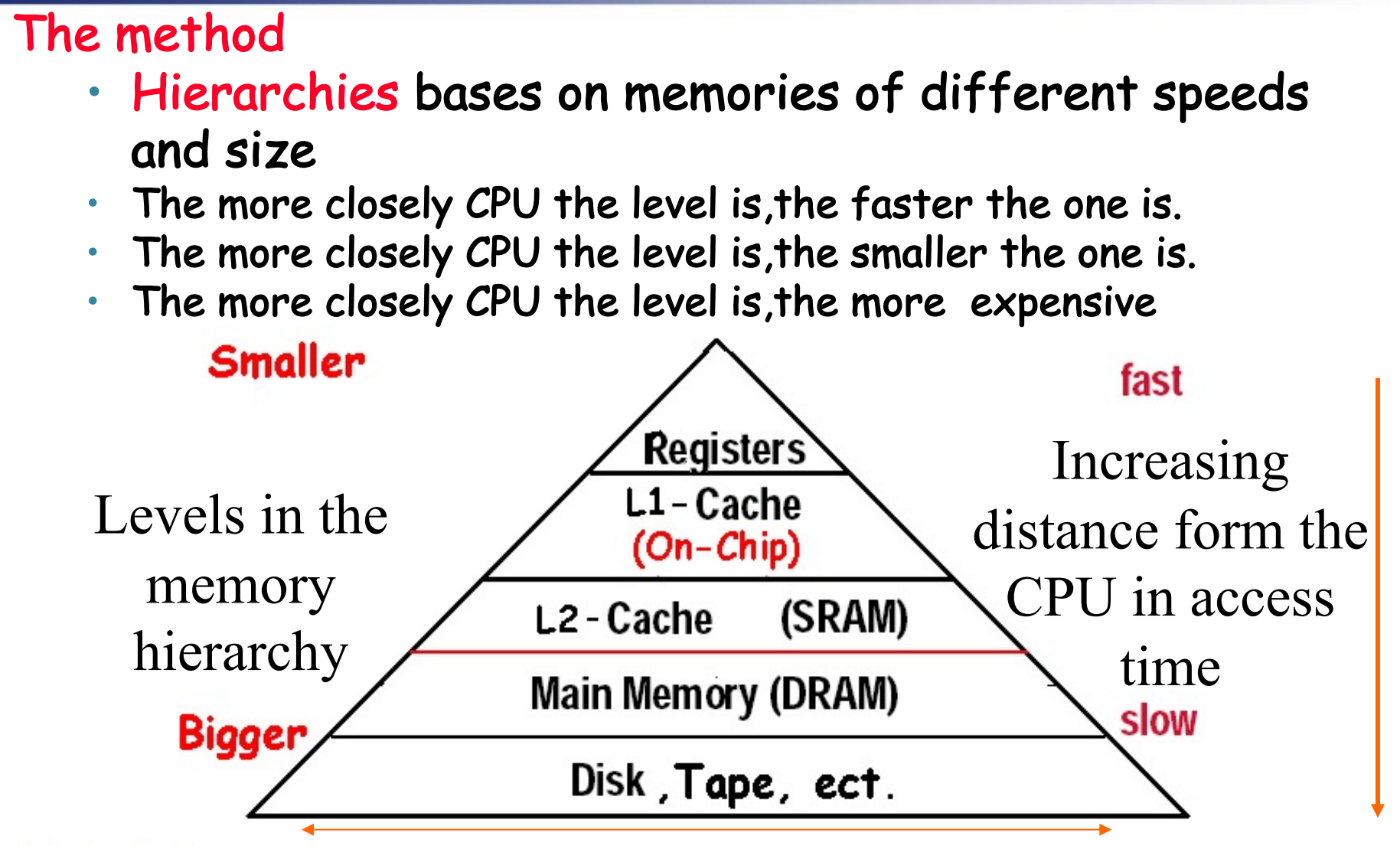
Memory hierarchy
-
Store everything on disk
-
Copy recently accessed (and nearby) items from disk to smaller DRAM memory
将最近访问的(和附近的)项目从磁盘复制到较小的 DRAM 内存
- Main memory
-
Copy more recently accessed (and nearby) items from DRAM to smaller SRAM memory
将最近访问(和附近)的项目从DRAM复制到较小的SRAM存储器
- Cache memory attached to CPU
近期访问到的内存单元和它附近的内容会被复制一份放到DRAM(main memory),或者从DRAM复制一份放到离CPU更近,访问速度更快的SRAM(cache)中
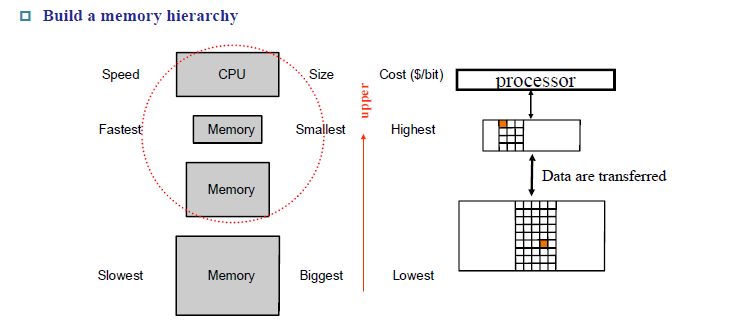
上图中中间的价格最高,为cache(SRAM),底部的价格最低,为memory(DRAM)
第i层的数据来源于第i+1层,所以第i+1层一定存在前面i层的所有数据
-
Block (aka line): unit of copying
向上级存储器传输数据的最小单位(可能有很多个字)。如果需要从memory向cache传输数据,最小传输单位就是一个block
-
Hit: If accessed data is present in upper level
The CPU accesses the upper level and succeeds.
命中 - 上层的存储器(cache)有我们要的数据,不需要去下层存储器(memory)寻找
- hit ratio: hits/accesses
- hit time:
访问上层存储的时间以及决定是否命中的时间
-
Miss: If accessed data is absent
The CPU accesses the upper level and fails
block copied from lower level
需要从下层存储器中把对应数据的块传输到上层,接着从上层把数据读走
-
miss penalty:用下层的相应块替换上层块的时间,加上将此块传送到处理器的时间。(注意此处是replace,不是覆盖。存在上层存储器已经满的情况,替换的过程中需要将原先的上层块重新写回到下层存储器) -
miss ratio: 1 - hit ratio
-
miss time: 替代上层存储器的块的时间和把这个块给处理器的时间
-
hit此处存在两种情况,分别是
- 访问磁盘,发现内存中存在数据
- 访问内存,发现cache中存在数据
所以使用的是upper level
Exploiting Memory Hierarchy
接下来我们关注两部分:
- The basics of Cache: SRAM and DRAM(main memory)
解决速度问题
- Virtual Memory: DRAM and DISK
解决容量问题
5.3 The basics of Cache¶
For each item of data at the lower level, there is exactly one location in the cache where it might be.
So, lots of items at the lower level share locations in the upper level.
多个块会映射到cache的同一个位置。
-
How do we know if a data item is in the cache?
如何知道数据是否在 cache 中?
-
If it is, how do we find it?
如果有,如何找到数据?
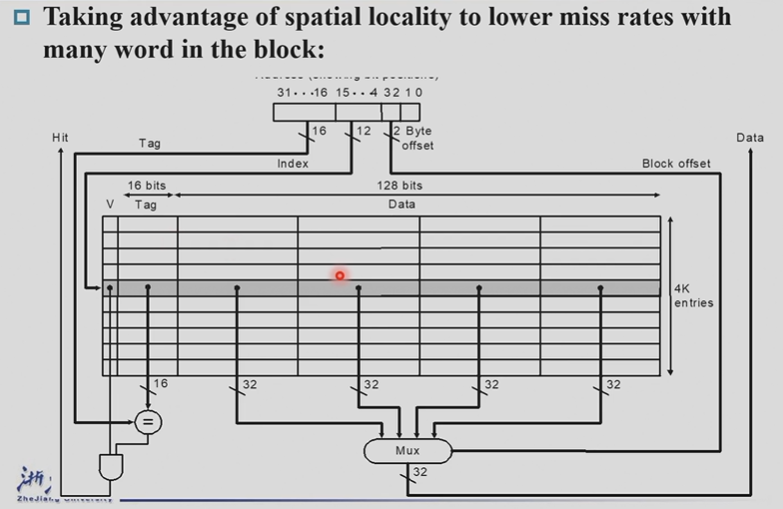
5.3.1 Direct Mapped Cache¶

memory address is modulo the number of blocks in the cache 取模。
如上图所示,内存有 32 个 block,其编号 (block address) 分别为 00000 到 11111;cache 有 8 个 block。Direct mapped cache 这种方式直接按 block address 的后 3 位确定它应该放在 cache 的哪个 block 里。
先确定需要寻找的数据在memory的哪个block,根据取模找到对应的cache中的block,判断是否有数据。怎么确定cache block中的数据就是我们需要的那个block的数据呢?利用memory block index的高若干位,作为高位标记,一并存储到cache中。例如图上的例子中,10001 存在 index 为 001 的 cache block 中,只需要额外存开头的 10 即可。
-
Store block address as well as the data 我们需要知道 cache 放的是哪个块。
- Actually, only need the high-order bits 高位比特
- Called the tag 称之为标记
-
Valid bit: 1 = present, 0 = not present
我们需要知道 cache 里是否有放有效的块。
如何确定cache中存放的block是否有效?任何时候该block都有一个值,如果这个值是启动时自带的,那么就会发生错误(因为它不是对应的memory block的值)。因此我们引入
valid bit来表示这个block是否有效。1 表示 有效,0 表示无效cache hit 当且仅当 valid bit 是 1 而且 tag 是一致的。
我们在内存中的地址都是以字节为单位的,但是我们讨论的block address是以block为单位的。
我们需要将byte address 转化为 block address,操作也就是:
-
计算每一个block所占的字节数。block往往是2的若干个次方个word,对应的,每一个block的byte数也是2的若干次方
-
用byte address / \(2^n\)得到前若干位,也就是对应的block address,相当于将相邻的\(2^n\)个byte聚合成一个block
此时我们的byte address分为两个部分:block address 和 byte offset,即所在block的编号和在该block中的偏移量。
block address又分为两个部分,tag 和 index
gua
同时也会发现 memory block address 长度大于 cache block address,因为多了tag,多对一
关于cache block的结构(地址index确定):包含valid bit, tag, data
-
byte offset 位宽由 block的大小(size)决定
-
index位宽由cache 中block的数量决定
-
tag 位宽由总的地址位宽减掉其他位决定
如果一个 block 是一个字(4个byte),那么 byte offset 应该有 2 位。
注意 CPU 给出的地址都是以 byte 为最小寻址单元的。
example
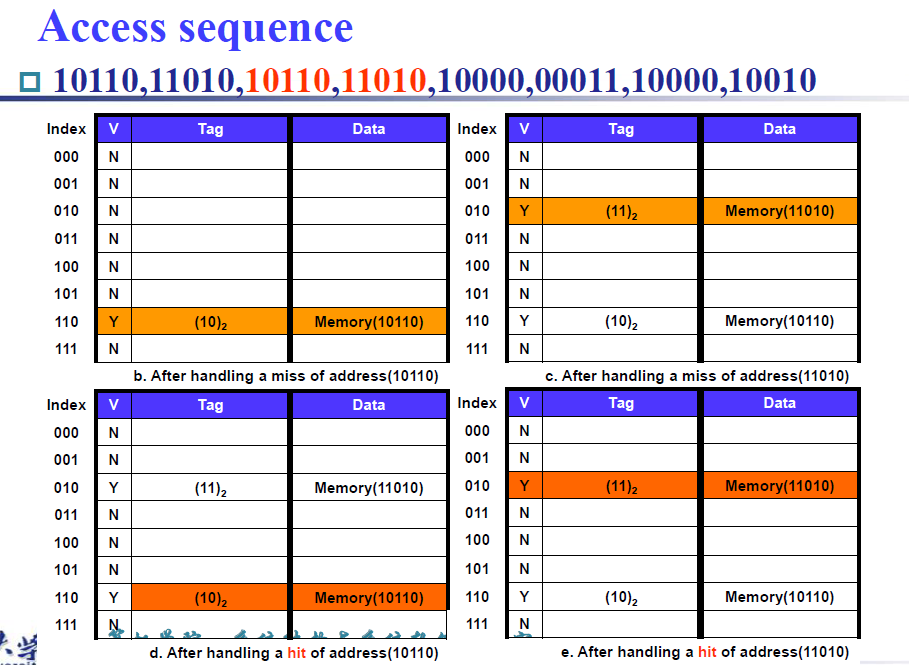
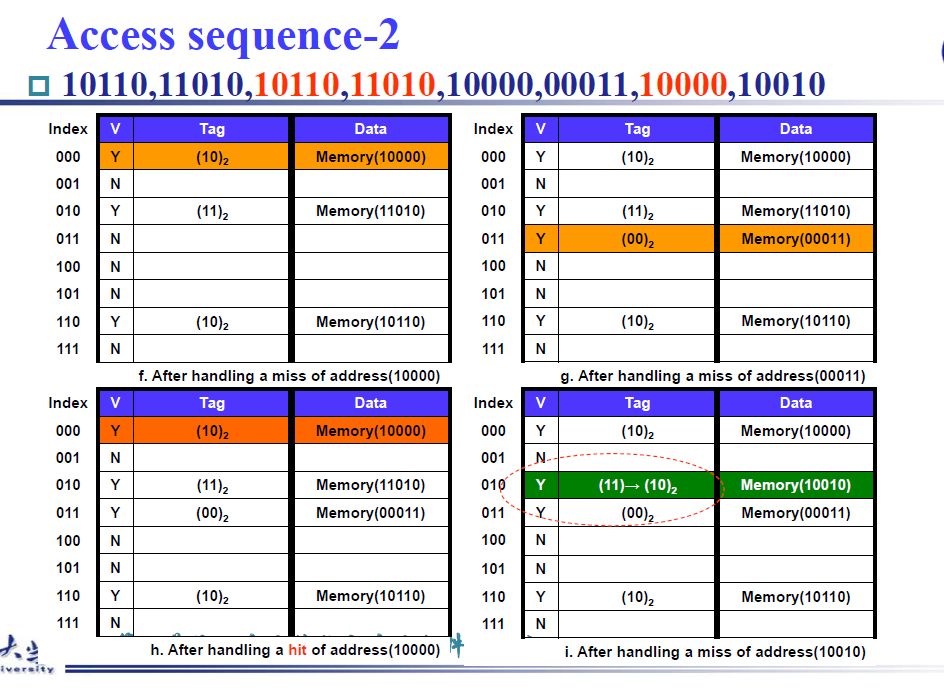
注意看操作i,虽然index对上了,但是tag不一样,同样是miss,此时需要进行replace操作,将memory(11010)替换为memory(10010)
对于一个64位地址的机器,cache的大小为1024个block,一个block有一个word,也就是4个byte。
- index的位数为\(log_2 1024 = 10\)
- byte offset的位数为\(log_2 4 = 2\)
- tag的位数为\(64-2-10=52\).
- cache每一条目的位数就是valid bit(1位) + tag(52位) + data(1个word32位) = 85
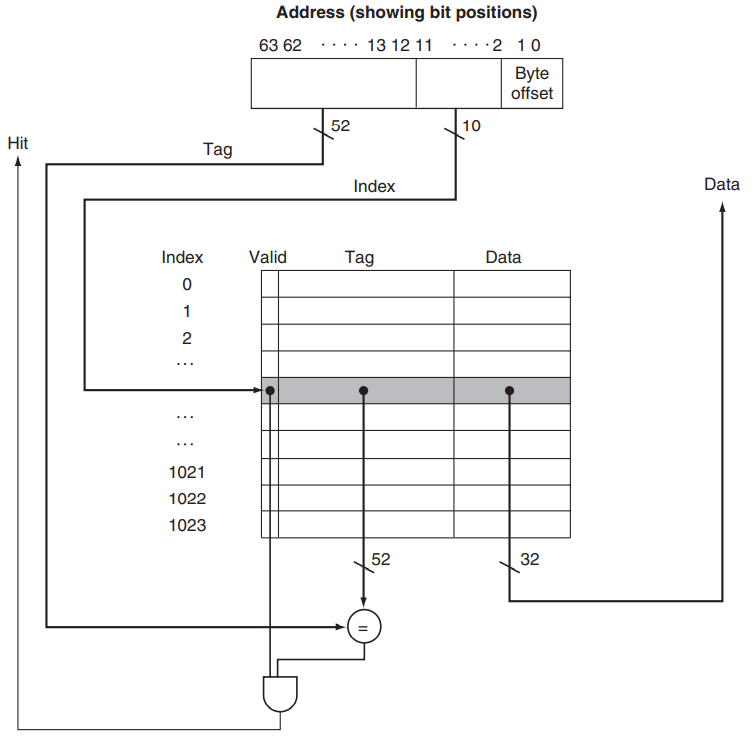
hit要求 valid bit = 1, index 对应, tag 对应。最终结果根据offset从Data中进行选取
一个block中可能存在多个word,但是每一次实际上只会访问出一个word,因此我们需要在block中选择出对应的word,这时候需要block offset
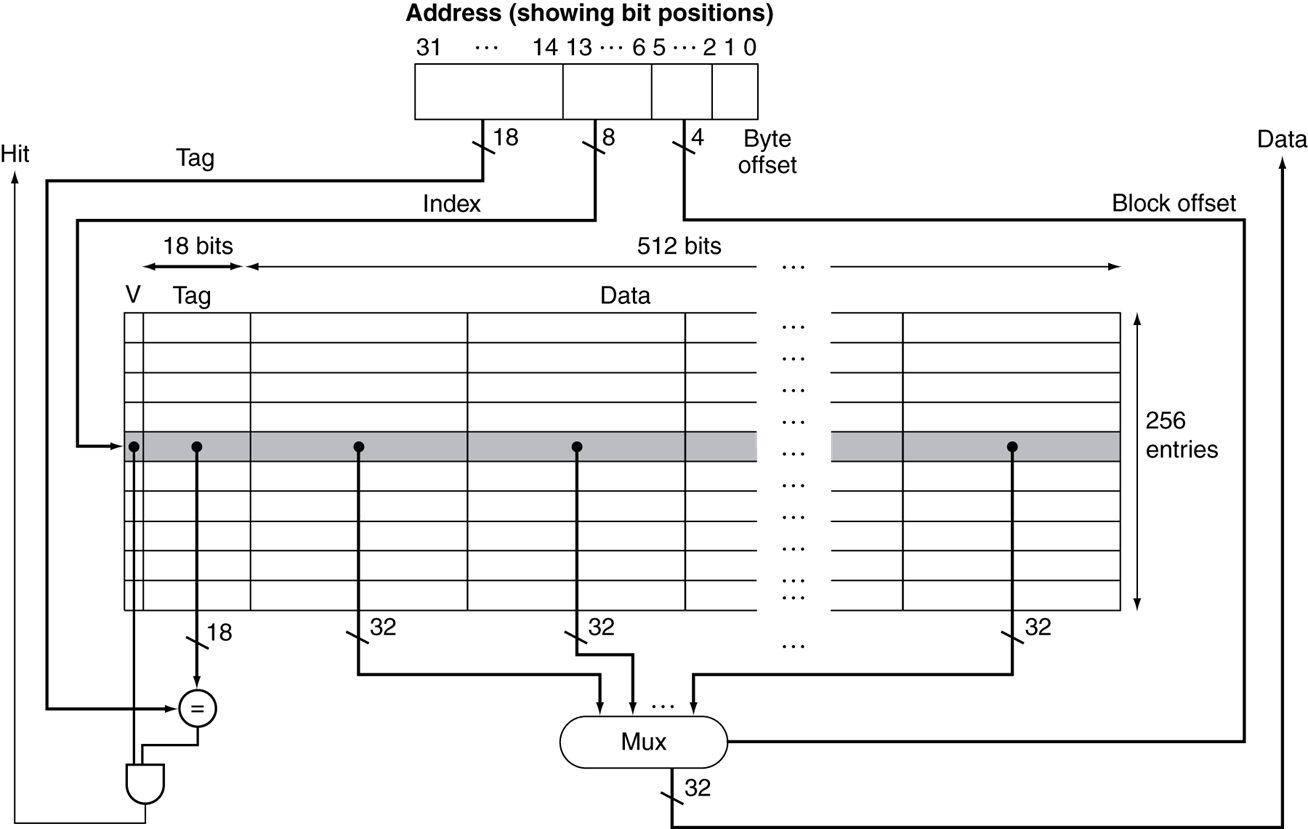
上方的情形使用的是32位的机器,一个block有16个word,一共有256个cache entry。yi
- byte offset的位数为\(log_2 4 = 2\)
- block offset的位数为\(log_2 16 = 4\)
- index offset的位数为\(log_2 256 = 8\)
- tag的位数为\(32 - 2 - 4- 8 = 18\)
- 一个cache entry的长度为valid bit + tag + data = 1 + 18 + 16 *32 = 531
Example "Bits in Cache"
important
- 一共有16KB的数据,也就是16KB/4B= 4K word
- 一个block有4个word,总数据为1K block
- 1K 个 block 对应的index位数为10
- byte offset位数为2,block offset位数为2
- 那么tag位数为32-10-2-2=18
- 一个cache entry的位数为1+18+4*32 = 147
- total bits = \(2^{10}\times 147\) = 147Kbit

- 下方同理,只是tag的位数发生改变,此时tag的位数为64-10-2-2=50
Example "Mapping an Address to Multiword Cache Block"

已知byte address,我们需要先知道block address,也就是1200/16 = 75.然后我们知道cache中一共有64个block,那么通过取模,我就知道对应的block number 为75%64=11
现在我们希望知道第11个cache block中存放的byte address的范围
- 正向思考,每一个block存放16bytes,又由于刚刚的计算发现1200byte address 恰好是第一个,所以范围是1200-1215
- **逆向思考,第12个block存放的初始byte的地址是:12 + 64 = 76,76 * 16 = 1216,夹逼一下得到范围是1200-1215 **
5.3.2 Handling Cache hit and Misses¶
-
Read hits
直接从 cache 里读就好了
-
Read misses—two kinds of misses

-
data cache miss- 从 memory 里把对应的 block 拿到 cache,然后读取对应的内容。
- 写入cache,将内存中的数据data放在条目的数据部分,将地址的上位(来自 ALU)写入标签字段,然后打开有效位。
-
instruction cache missStall the CPU, fetch block from memory, deliver to cache, restart CPU read
暂停 CPU 运行,从 memory 里把对应的 block 拿到 cache,从第一个 step 开始重新运行当前这条指令。
- Send the original PC value (current PC-4) to the memory.
因为 PC 取值完就变成 +4 了,所以当前执行的其实是 PC-4
-
Instruct main memory to perform a read and wait for the memory to complete its access.
根据PC-4,从内存中获取指令内容
-
Write the cache entry, putting the data from memory in the data portion of the entry, writing the upper bits of the address (from the ALU) into the tag field, and turning the valid bit on.
将指令内容写入对应的cache entry,将高位bit写入到tag,将valid bit写为1
-
Restart the instruction execution at the first step, which will refetch the instruction again, this time finding it in the cache.
在第一步重新启动指令执行,这将再次重新获取指令,这次是在缓存中找到它
-
-
Write hits
-
write-back: Cause Inconsistent
cache和memory都有相同的数据。仅仅将数据写入到cache。如果需要replace cache中的数据,此时需要将cache中对应的数据写入到memory。引入一个dirty bit来记录这个cache block是否被更改过,从而判断是否需要写入到内存 -
write-through: Ensuring Consistent
既把数据写到 cache 中又写到内存中,速度慢。改进措施:将数据写入到内存操作,先将数据写入到write buffer,就可以执行下一条指令,buffer内的数据等到有机会慢慢写入内存即可。如果write buffer慢了,需要暂停处理器执行写入main memory的工作,知道buffer中有空闲的entry
-
-
Write misses
-
read the entire block into the cache, then write the word —— wirte allocate
像 read miss 一样先把 block 拿到 cache 里再写入。
-
Write around the data into the memory ( the lower level memory) ----no write allocate ( also called write around ).
不拿到cache中,直接写入到内存中即可
-
区分write Through, write back, write allocation操作
如果执行的是no-write allocate
- ·
由于初始状态cache是空的,所以Write miss,此时执行的是no-write allocate(也就是write around),直接将Mem[100]写入到内存中,cache上不保存Mem[100]再次执行write Mem[100], write miss, 依然直接写入到内存,不保存在cache中Read Mem[200], Read miss,此时需要从内存中取出Mem[200],并将Mem[200]保存到cache中,然后读取Mem[200]write Mem[200], write hitwrite Mem[100], write miss如果执行的是write allocate
由于初始状态cache是空的,所以Write miss,此时执行的是write allocate,需要先把对应的block拿到cache,然后再写入数据再次执行write Mem[100], write hit, 因为cache中已经存在Mem[100]Read Mem[200], Read miss,此时需要从内存中取出Mem[200],并将Mem[200]保存到cache中,然后读取Mem[200]write Mem[200], write hit再次执行write Mem[100], write hit, 因为cache中已经存在Mem[100]

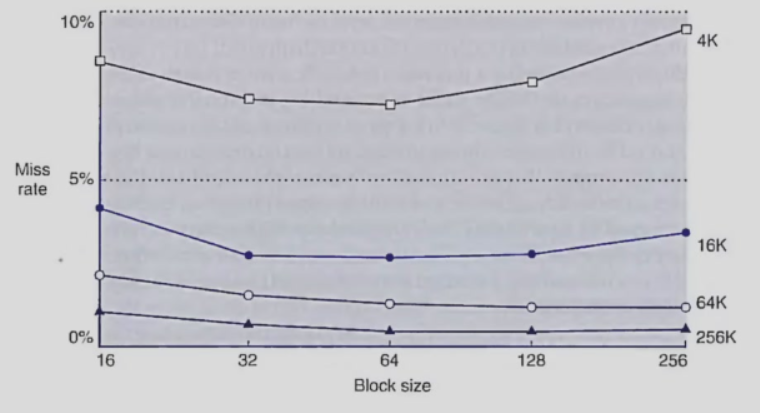
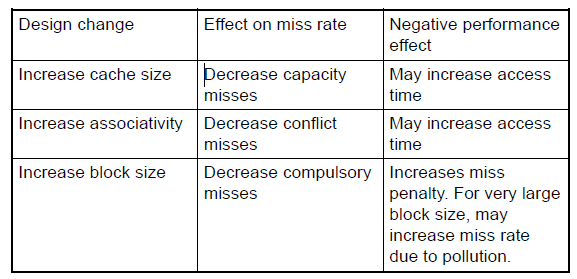
block size增大, miss rate 先减少后增大
- 利用局部性,把相邻的都读取进来
- block size太大,竞争激烈,还没利用完就被替换,同时miss penalty增大(size太大,传输时间增加)

5.3.3 Deep concept in Cache¶
-
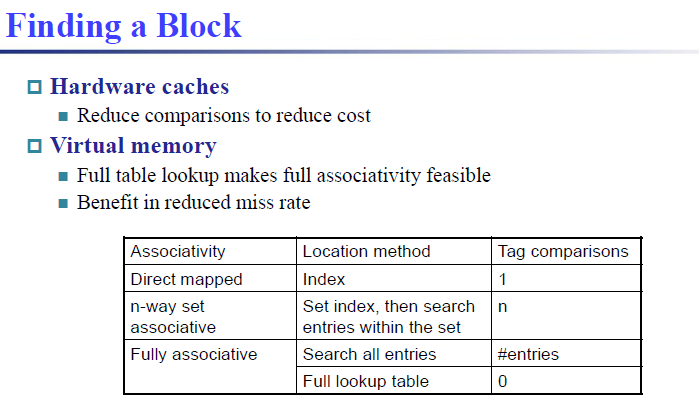
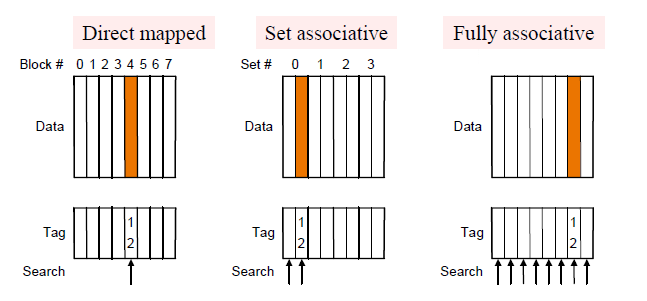
Q1: Where can a block be placed in the upper level? (Block placement)
存在三种方式:fully associative,set associative, direct mapped -
Q2: How is a block found if it is in the upper level? (Block identification)
Tag/Block
-
Q3: Which block should be replaced on a miss? (Block replacement)
Random, LRU, FIFO -
Q4: What happens on a write? (Write strategy)
Write Back or Write Through
5.3.3.1 Block Placement¶
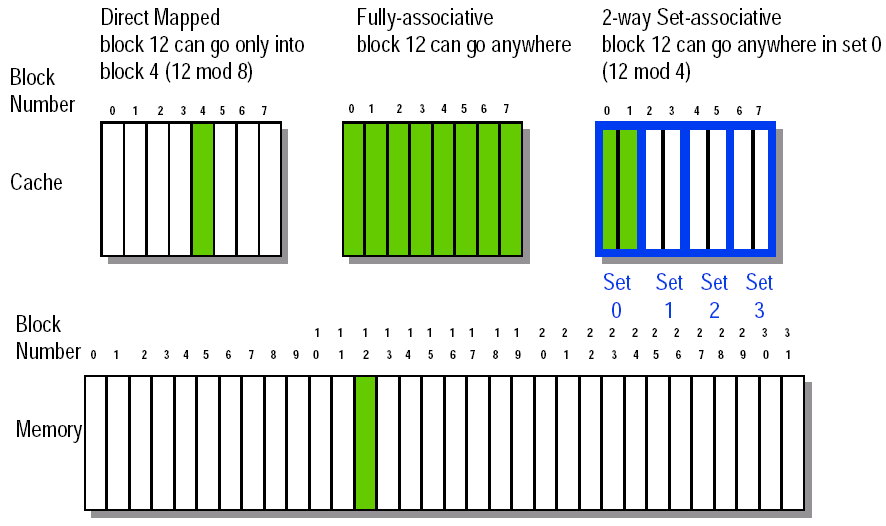
-
Direct mapped
Block can only go in one place in the cache块只能去一个地方,通常取模
-
Fully associative 全相联
Block can go anywhere in cache.哪里空了去哪里
-
Set associative 组关联
Block can go in one of a set of places in the cache.A set is a group of blocks in the cache.
set associative 是上面两种方法的集合。先用block address mod number of sets in the cache 计算出当前block应当位于哪个set,然后在对应的set空闲的任意block进入插入
如果一个set有n个block,那么就将该cache称之为n-way set associative
Direct mapped 相当于 1-way set associative, Fully associative 相当于 m-way set-associative(for a cache with m blocks)
5.3.3.2 Block Identification¶
-
Tag
-
Every block has an address tag that stores the main memory address of the data stored in the block.
每个块都有一个地址标签,用于存储块中存储的数据的主内存地址。
-
When checking the cache, the processor will compare the requested memory address to the cache tag -- if the two are equal, then there is a cache hit and the data is present in the cache
在检查缓存时,处理器会将请求的内存地址与缓存标签进行比较——如果两者相等,则存在缓存命中,并且数据存在于缓存中
直接映射只需要比较一个块的 tag, 级相联需要比较 set 里所有块的 tag.
-
-
Valid bit
The Format of the Physical Address
-
The Index field selects
-
全相联没有 index.
- The set, in case of a set-associative cache 组关联 \(\log_2(sets)\)
- The block, in case of a direct-mapped cache 直接映射 \(\log_2(blocks)\)
-
-
The Byte Offset field selects
由一个块内 byte 的数目决定. \(\log_2(size \ of \ block)\)
-
The Tag is used to find the matching block within a set or in the cache

Example "Direct-mapped Cache Example (1-word Blocks)"
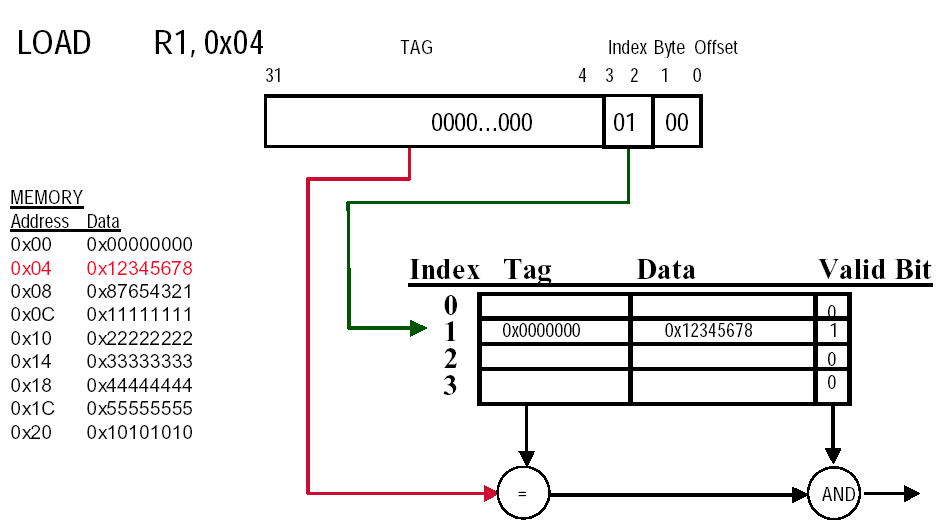
cache一共有4个cache entry,对应的index的位数为2
从cache中取0x04的内容时,比较对应index的entry的tag是否相等,比较valid bt是否为1
Example "Fully-Associative Cache example (1-word Blocks)"
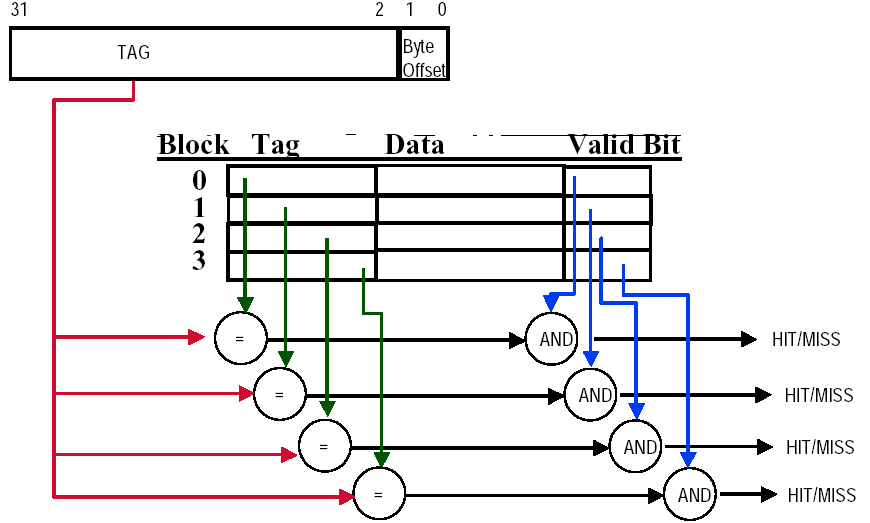
这种方式的好处是可以降低 miss rate,坏处是每次需要跟所有 block 比较是否 hit:
由于没有index,内存地址的tag需要与cache block address中所有的tag进行,如果相等再去检查valid bit是否为1.对于较大的cache,耗时太长
Example "2-Way Set-Associative Cache"
前提:cache一共4个block,一个block1个word
分成两组的话,一个set有两个block

注意这里应该是对 Set0 里面的 tag 比较。
先根据index找到对应的set,然后tag跟set里面的每一个entry的tag进行比较
5.3.3.3 Block Replacement¶
In a direct-mapped cache, there is only one block that can be replaced.
In set-associative and fully-associative caches, there are N blocks (where N is the degree of associativity).
-
Random replacement - randomly pick any block
-
Easy to implement in hardware, just requires a
random number generator -
Spreads allocation uniformly across cache
-
May evict a block that is about to be accessed
可能逐出即将被访问的块
-
-
Least-recently used (LRU) - pick the block in the set which was
least recently accessed-
Assumed more recently accessed blocks more likely to be referenced again
-
This requires extra bits in the cache to keep track of accesses.
需要额外的位数!
-
-
First in,first out(FIFO) - Choose a block from the set which was first came into the cache
5.3.3.4 Write Strategy¶
write hit:
- write back
- write through
-
If the data is written to memory, the cache is called a write through cache
- Can always discard cached data - most up-to-date data is in memory
- Cache control bit: only a valid bit
- memory (or other processors) always have latest data
好处是:cache和memory具有一致性,cache内的block需要被替换时,直接丢掉即可。同时只需要一个valid bit,不需要dirty bit检查是否修改过 -
If the data is NOT written to memory, the cache is called a write-back cache
- Can’t just discard cached data - may have to write it back to memory
- Cache control bits: both valid and dirty bits
- much lower bandwidth, since data often overwritten multiple times
坏处是:需要一个dirty bit,需要检查是否被修改过。cache和memory不一致。好处是:对某一个数据执行多次的写入修改操作时,只需在最后写入到内存中,速度快
写回需要时间,我们需要 write stall.
Write stall -- When the CPU must wait for writes to complete during write through.
我们往往使用 write buffer.
-
A small cache that can hold a few values waiting to go to main memory.
-
It does not entirely eliminate stalls since it is possible for the buffer to fill if the burst is larger than the buffer.
buffer 可能被填满,不能完全避免 write stall.
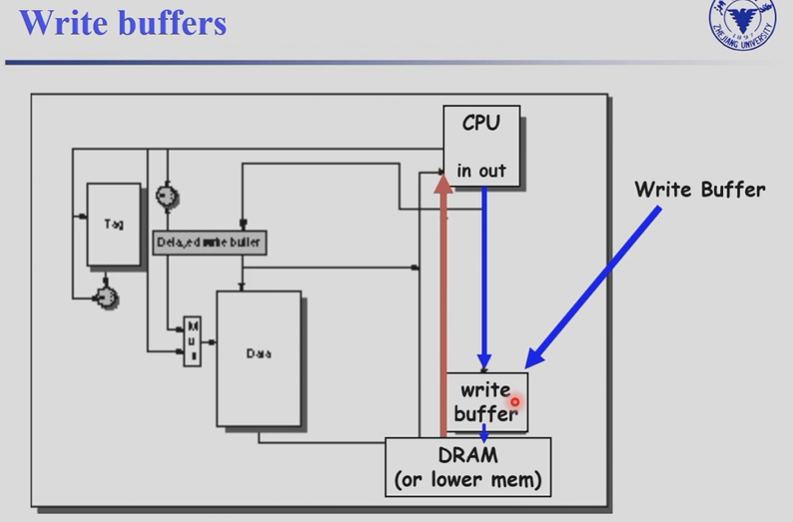
存在问题:当我如果要读的时候,数据还在 buffer 里没有被写入内存。因此我们需要先在 buffer 里面比较,如果没有再在内存里找。
Write miss
- write allocate
- write around(no write allocate)
-
Write allocate
The block is loaded into the cache on a miss before anything else occurs.
读取到cache的时候,如果发生替换,还需要检查被替换的数据dirty bit是否为1,是否需要写回内存常与 write back 搭配
-
Write around (no write allocate)
常与 write through 搭配
- The block is only written to main memory
- It is not stored in the cache.

-
Compulsory miss强制失效,第一次访问时,block一定不存在
-
capacity miss容量失效:cache的容量不够,被替换出去的block后续仍需要访问
-
conflict miss冲突失效:例如direct mapped中,多个memory block对应一个cache block,即使cache没有满,也会发生替换
提高关联度,set中block的数量。虽然miss的概率减小,但是访问时间增加
空间局部性原理的使用:
Spatial locality 空间局部性
Items near those accessed recently are likely to be accessed soon
最近访问的项目附近的项目可能很快就会被访问
如数组,我们访问了这个元素后大概率还要访问后面的元素
Larger blocks exploit spatial locality
利用在一个block中装尽更多的word,这样就把相邻的数据都存放在了一起。
5.3.4 Designing the Memory system to Support Cache¶
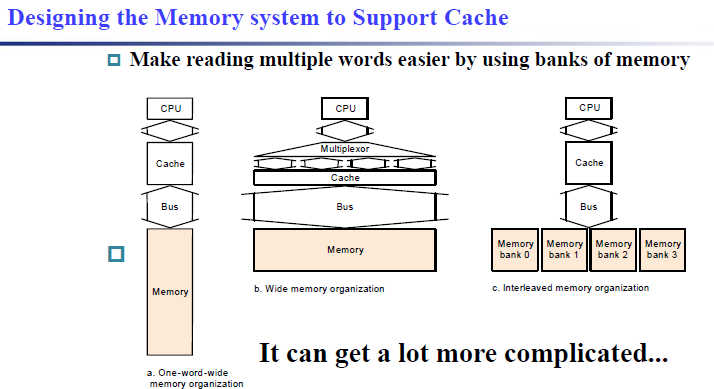
为了提高 cache 的性能,我们有不同的 memory 组织架构
-
Performance basic memory organization

传输一个word所需的时间为:1个时钟周期发送指定的地址,15个时钟周期从DRAM中取出数据,1个时钟周期返回结果 \(1 + 15 + 1 = 17 cycles\)如果是传输一个block/miss penalty,所花的时间为:地址只需要传输一次(连续存储),4次取数据传数据,所以时间为\(1 + 4\times (15 + 1) = 65cycles\)从而计算出带宽bandwidth(传输一个block,每一个byte所花费的时间):\(\dfrac{4 \times 4}{65} \approx \dfrac{1}{4}\) -
Performance in Wider Main Memory
一次可以读出两个 word.

但是这时内存太大,代价太大
-
Performance in Four-way interleaved memory
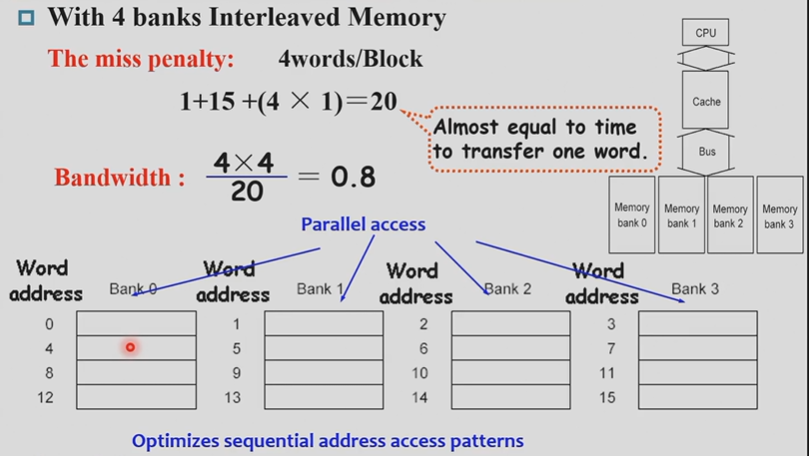
执行方法为:第1个时钟周期将地址传给bank0,第2个时钟周期将地址传给bank1,以此类推。直到第16个时钟周期,bank0内完成数据的读取,第17个时钟周期,bank0的数据传输回去,bank1内完成数据的读取。最后在第20个时钟周期,bank3完成数据的传输所以花费的总时间是:\(1 + 15 + 1 + 3(延迟) = 20\)
5.4 Measuring and improving cache performance¶
- How to measure cache performance?
- How to improve performance?
Reducing cache missesby more flexible placement of blocksReducing the miss penalty using multilevel caches
Average Memory Assess time = hit time + miss time = hit rate \(\times\) Cache time + miss rate \(\times\) memory time
5.4.1 Measuring cache performance¶
We use CPU time to measure cache performance.
这里 CPU 的执行时间在设计流水线的时候已经确定了,我们无需考虑。
-
For Read-stall
\[ Read \ stall\ cycles = \dfrac{Read}{Program}\times Read\ miss\ rate \times Read\ miss\ penalty \]包括取指和数据加载。
-
For a write-through plus write buffer scheme
$$ Write stall cycles = \left(\dfrac{Write}{Program} \times Write miss rate \times Write miss penalty\right) \ +Write buffer stalls $$- If the write buffer stalls are small, we can safely ignore them.
一般来说 buffer 不会溢出。
- If the cache block size is one word, the write miss penalty is 0.
大小是一个 word, 替换出去就直接写了。
In most write-back cache organizations, the read and write miss penalties are the same.
Read miss penalty:read miss 是将block传输到cache,再进行读取。write miss 是write allocate(常与write back搭配),在cache和memory都执行写入
If we neglect the write buffer stalls, we get the following equation:
Read stall 和 Write stall合并,Read和write合并为memory access

注意此处计算hit time的时候,应当直接使用cache time,不用hit rate * cache time。因为不管有无hit,都需要进行tag的比较。如果hit,直接从cache中读取即可。如果没有hit,应当先将数据从内存中读取到cache,再从cache中读取,所以两者的cache time相同
example:Calculating cache performance


内存占了性能瓶颈。
假设我们把时钟频率提高两倍,相同的内存访问时间,导致内存的miss penalty会提高两倍,所需的cycle数是原来的两倍由于时钟频率提高了一倍,相应的cycle time会变为原来的二分之一,所以最后计算时间的时候需要×二分之一
此时 CPU 性能实际只提升 1.23 倍。

5.4.2 Improving¶
5.4.2.1 solution1¶
提高 cache 命中率;减小 penalty.
Reducing cache misses by more flexible placement of blocks

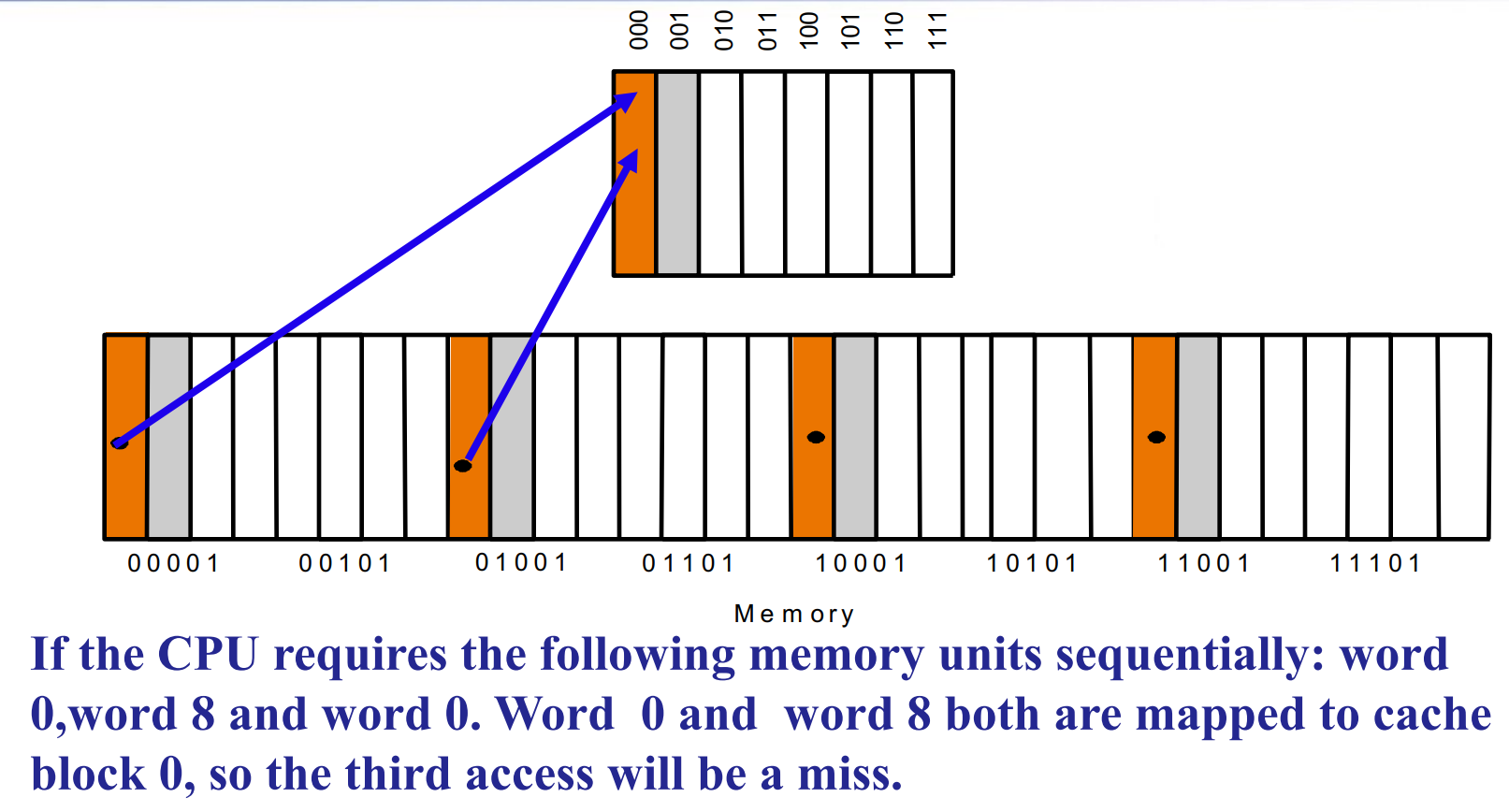
如果我们正好以模长为步距访问,就会一直 miss. 但其实此时 cache 中还有很多空位。
-
The disadvantage of a direct-mapped cache
多个memory block 对应单个cache block,miss的概率太大
-
The basics of a set-associative cache

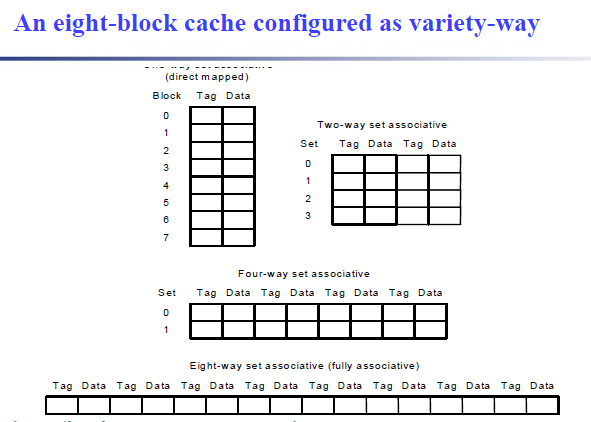
two way set associative 一个set两个等价的block,此处直接连接在一起
-
Miss rate versus set-associative
注意 block addr 是忽略了地位的 byte offset 的。

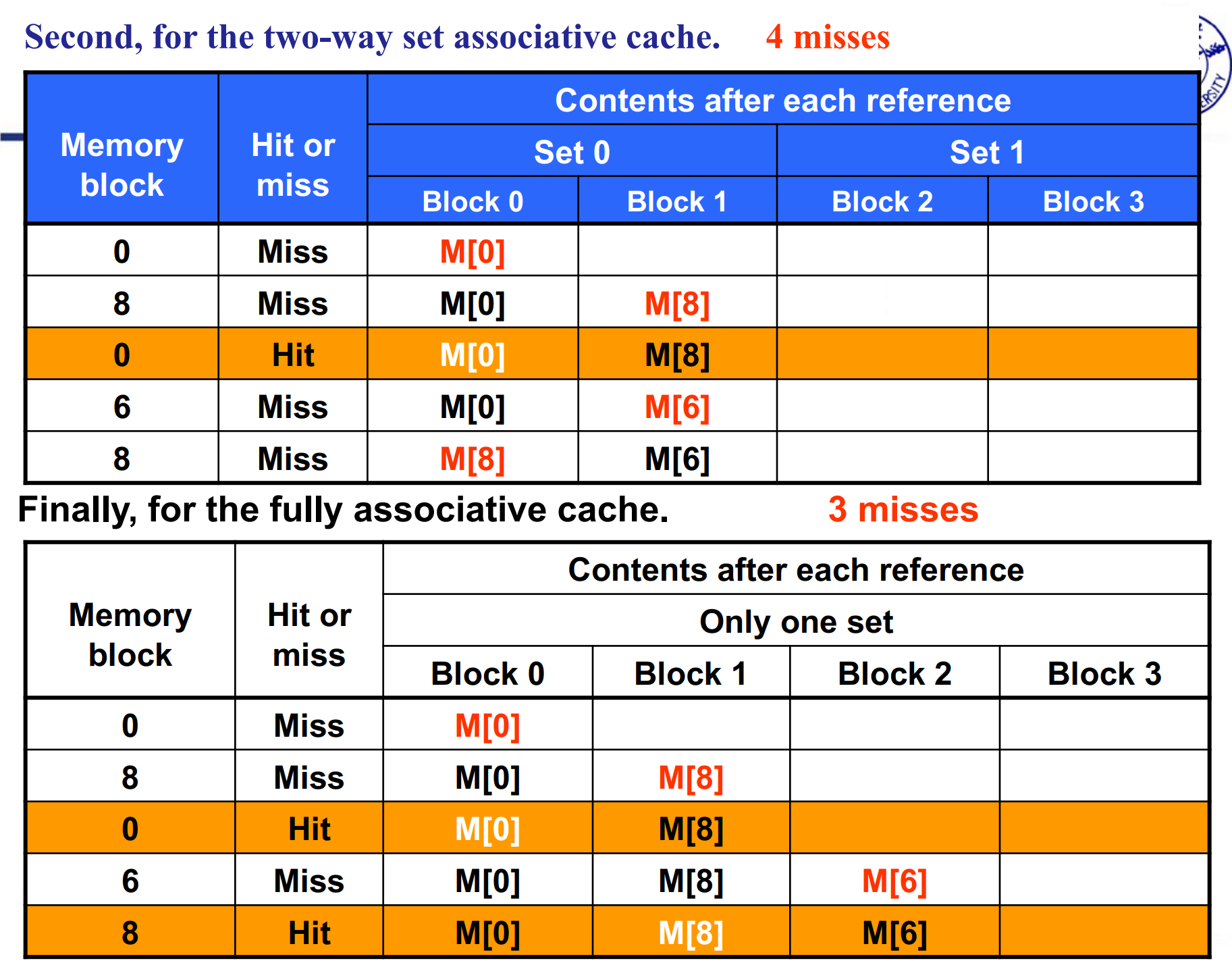
此处的替换策略是LRU,最近最少策略
全关联的miss次数最少,但是每一次的开销是最大的
-
locating a block in the set-associative cache

先找到对应的set,再遍历set中的block,根据valid bit和tag,找到对应的block
首先set index的位数为8,有256个set,一个set有4个block,一个block有1个word,则上述cache能够存储\(256 \times 4 \times 4bytes = 4KB\)的数据 -
Size of tags versus set associativity

对于direct mapped,cache一共有4K个block,对应的index的位数是12
Block size是4words,那么byte offset的位数就是4
tag的位数就是32-12-4 = 16

对于Two-way association,cache set的数量为4K/2 = 2K,所需的index的位数是11位
对应的tag的位数是32-11-4 = 17
-
Choose which block to replace
Random,LRU,FIFO
5.4.2.2 solution2¶
Decreasing miss penalty with multilevel caches
通过多级缓存减少未命中代价
Add a second level cache:
- often primary cache is on the same chip as the processor
- use SRAMs to add another cache above primary memory (DRAM)
- miss penalty goes down if data is in 2nd level cache
primary cache(一级缓存)与处理器位于同一芯片上,使用 SRAM 在main memory (DRAM) 上方添加另一个缓存cache(二级缓存)
Example

-
假设没有二级cache,miss penalty to the main memory is \(100ns/0.2ns = 500cycles\)
The CPI with one level of cache $$ \begin{aligned} Total CPI &= 1.0 + Memory stall cycles per instruction\ &=1.0 + miss rate \times miss penalty \ & = 1.0 + 0.02 \times 500 = 11 \end{aligned} $$
-
添加二级缓存之后,一级缓存访问二级缓存的时间为5ns,对应的penalty为\(5ns/0.2ns = 25cycles\)
The CPI with Two level of cache with 0.5% miss rate for main memory\[ \begin{aligned} &Total \ CPI \\ &= 1.0 + Primary \ stall \ per \ instruction + Secondary \ stalls \ per \ instruction \\ &=1.0 + 0.02 \times 25 + 0.005 \times 500\\ &=1.0+0.5+2.5\\ &=4 \end{aligned} \]可以发现,性能提高了\(11/4 = 2.8\)倍
Using multilevel caches:
- try and optimize the hit time on the 1st level cache
- try and optimize the miss rate on the 2nd level cache
5.5 Virtual Memory¶
Main Memory act as a “Cache” for the secondary storage.
把主存当作磁盘的缓存。
-
Efficient and safe sharing of memory among multiple programs.
在多个程序之间高效安全地共享内存。
不同程序有自己的内存空间,我们希望只考虑自己的空间,不在乎其他程序放在哪里。让进程认为是自己独有这块地址空间。
-
Remove the programming burdens of a small, limited amount of main memory.
消除少量、有限的主存储器的编程负担。
Translation of a program’s address space to physical address.
虚拟内存的作用就是翻译。(内存是碎片化的,我们需要让程序认为地址是连续的)
Advantages:
-
illusion of having more physical memory
拥有更多物理内存的错觉
-
program relocation
-
protection

虚拟存储实际上就是地址的转化,执行的程序的地址(PC+4,连续)转化到内存中、磁盘中(离散的)。由于内存的空间是有限的,有一部分的指令直接映射到磁盘中,仿佛自己的内存能够做到无限大
为什么我们需要virtual memory?
- 程序保存在内存中,可能是分散的不连续的。但是程序执行的时候,要求能够PC+4.需要连续的执行,所以需要进行translation
- 存在程序很大,无法在内存中完整放下的困难。所以一部分的程序需要放到硬盘中,需要使用virtual memory 完成映射
5.5.1 Pages: virtual memory blocks¶
page 是映射的最小单位。
Page faults: the data is not in memory, retrieve it from disk
页缺失(相当于miss),也就是说数据不在内存中,需要从磁盘中检索获取
-
huge miss penalty, thus pages should be fairly large e.g. 4KB
将数据从硬盘中读取到内存,速度缓慢,代价太大 -
reducing page faults is important
(
LRU is worth the price,使用LRU替换策略替换内存中数据) -
can handle the faults in software instead of hardware
缺页是由操作系统处理的,而不是硬件(cache 是硬件做的) -
using write-through is too expensive so we use write back
使用write back而不是write through,此处的write through的意思是既写到内存中,又写到磁盘。但是写到磁盘的操作太慢,所以我们采用write back,也就是仅仅写到内存中。硬盘操作太慢了,我们只在被踢出的时候写回。因此突然断电的时候数据会丢失。
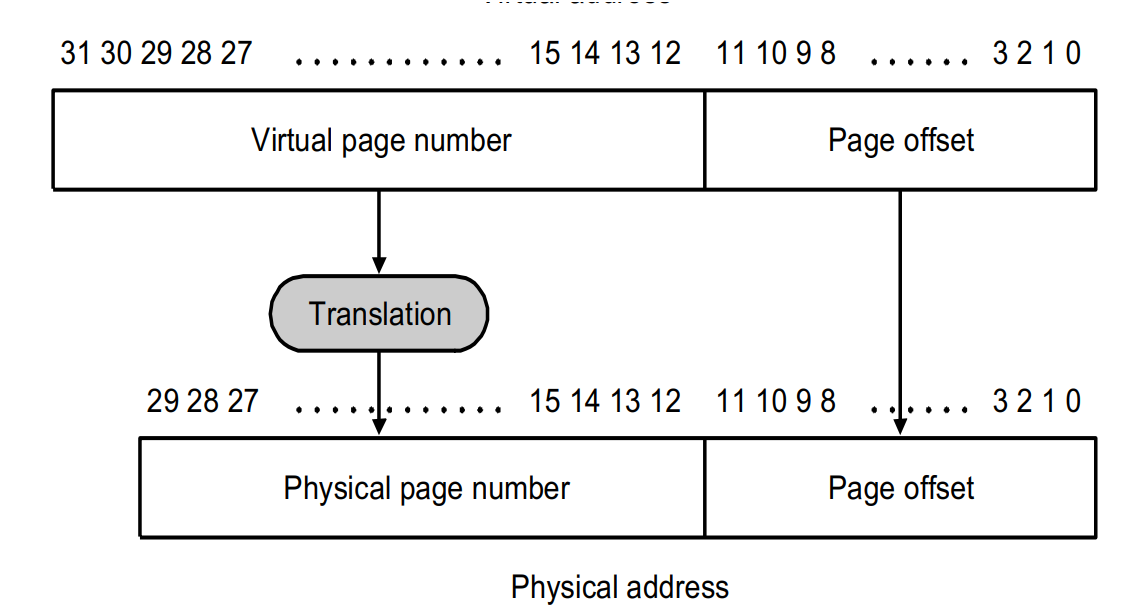
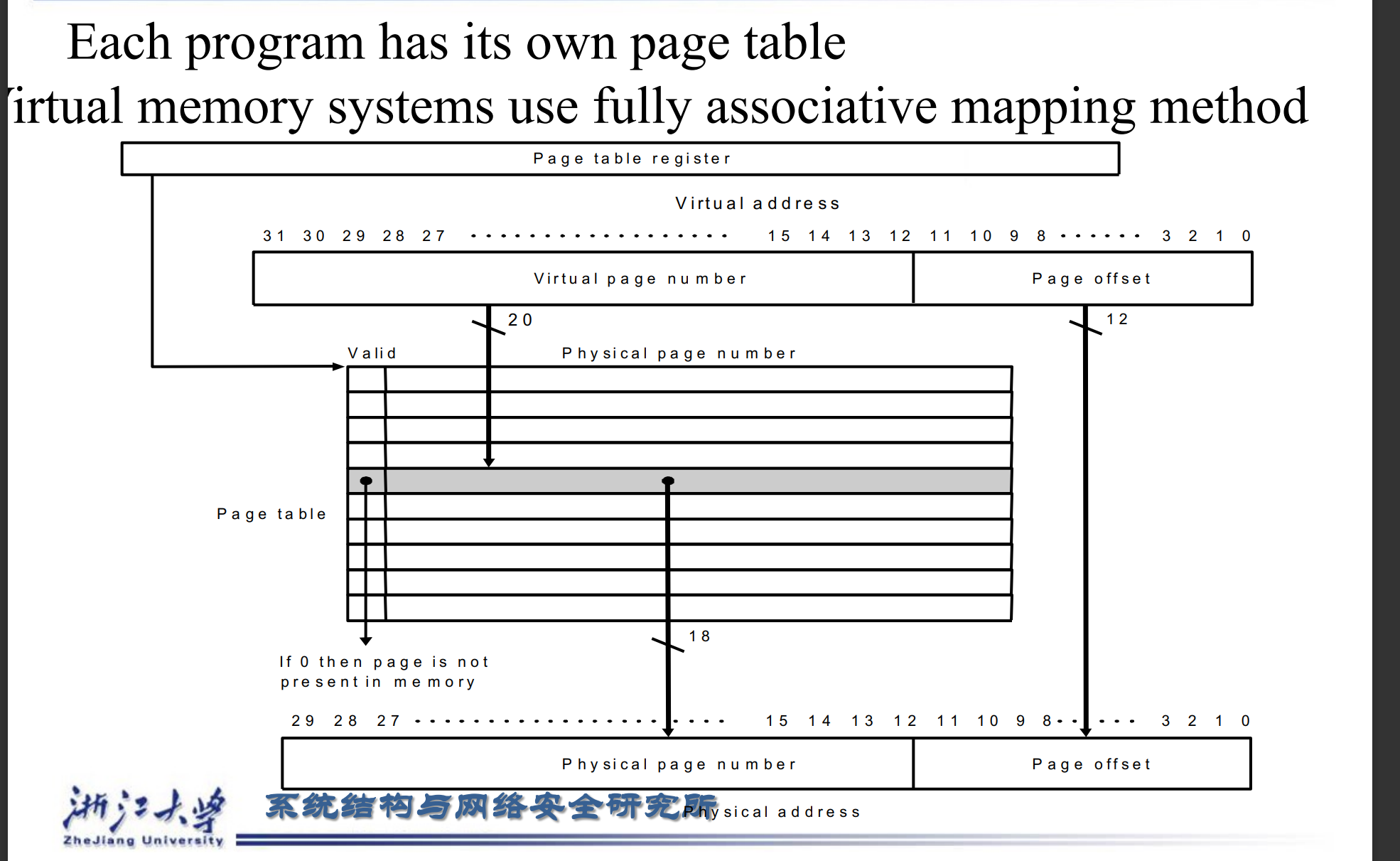
假设现在内存有\(2^{30}\)byte,也就是1G的空间。由于page的大小为4KB,在page内寻址所需的page offset所需的位数为12位。
CPU给出的地址32位叫做虚拟地址(大小固定,一般为32位或者64位)
translation的作用就是将Virtual page number转化为physical page number,对应的page offset不发生改变,直接迁移
Larger number of virtual pages than physical pages?
虚拟页的数量比物理页多(现在不一定)。
只要物理内存够大,能够容纳的page数量就多,相应的physical page number所需的位数也增加,可以会比virtual page number的位数要多
5.5.2 Page Tables¶
可能存在同时运行多个程序的情况。此时每一个程序都需要一个自己的virtual memory。因为不同程序执行时,可能存在virtual memory page相同的可能。因此每一个程序都需要有自己的page table
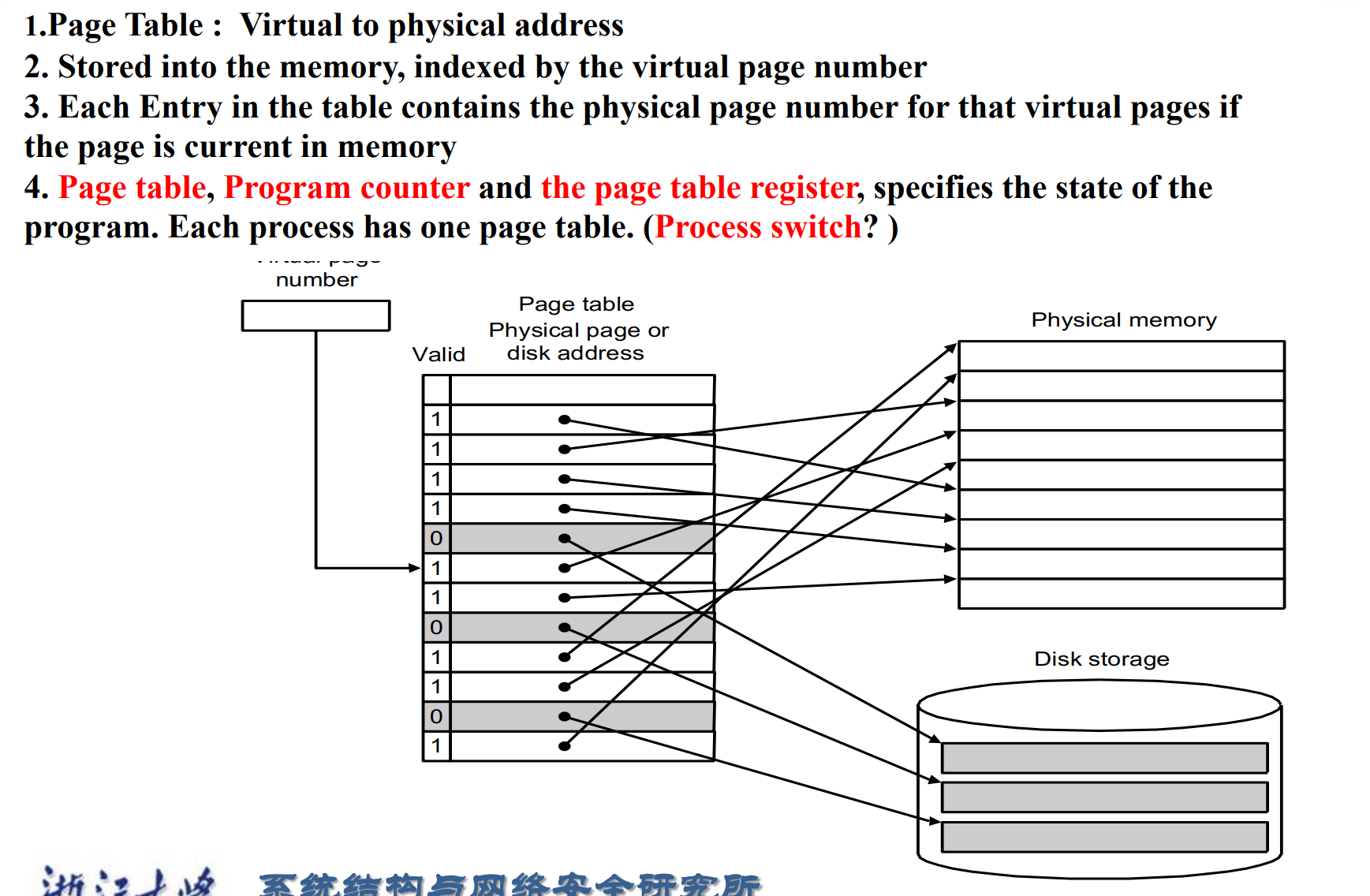
page table本身存在 memory 里,记录地址的映射关系。(索引是虚拟地址的高位,找到表中对应项,就是物理地址,前提是page刚好在内存中)
每个进程都有自己的 Page table, Program counter and the page table register.
如何切换进程呢?切换到对应的page table,然后将program count转化到进程当前所处的状态
Virtual memory systems use fully associative mapping method.
为了提高命中率,我们采用全相联的方式。这导致替换策略(比如 LRU)很复杂,但因为是 OS 编写,所以问题不大。
page table register的作用:用于追踪page table在内存中的位置
page table中还存在 valid bit,表示page是否在内存中
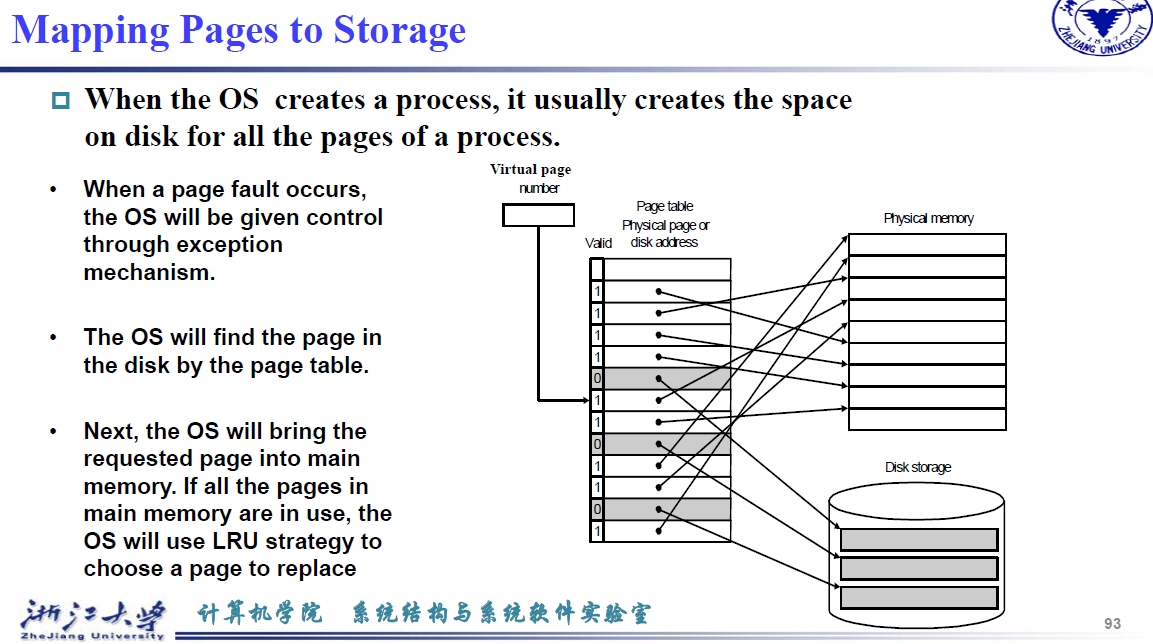
当操作系统创建进程的 时候,它会在disk中也创建一个page集合。如果page fault发生,操作系统会将控制权交给异常机制,找到缺失的页在disk中的位置。然后将对应的page写入到内存中,如果内存中的page已经满了,就会采用LRU策略替换掉最近最少使用的page

entry size 指的是页表里每条的大小,也就是virtual page number 指向 physical page number的那个条目的大小(包含valid bit....)
页表要能把所有的页都能放下。(每个虚拟页都需要存放对应的物理页) 。首先需要计算出虚拟页的页数,再乘以每一个entry的size,得到的就是page table 的size
我们需要减小页表的大小。

disk write 很慢,因此我们用 write-back 的策略,需要有一个 dirty bit.
The dirty bit is set when a page is first written. If the dirty bit of a page is set, the page must be written back to disk before being replaced.
如果设置了页面的dirty bit,则在替换之前必须将页面写回磁盘。
5.5.3 Making Address Translation Fast--TLB¶
在 pgtbl 上找也是很慢的,因此我们引入了 TLB.(CPU 内)
The TLB (Translation-lookaside Buffer) acts as Cache on the page table
给出虚拟地址,先在 TLB 找,找不到再去内存里的页表找。一般 16~512 entries.
判断是否成功在TLB找到对应的physical page number?使用tag,tag对应的也是virtual page number的高位
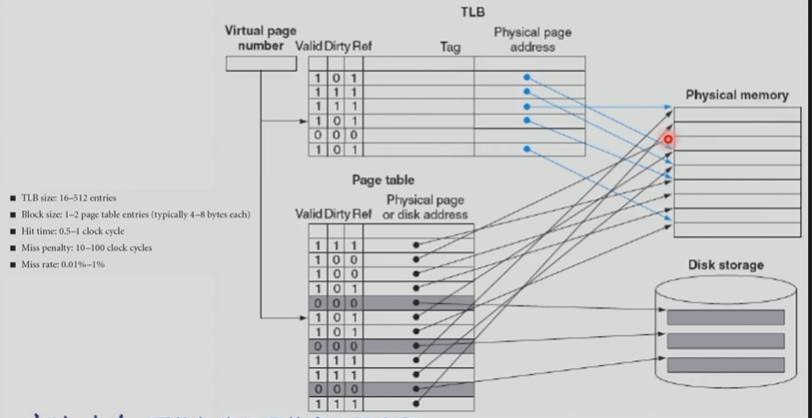
Example "FastMATH Memory Hierarchy"
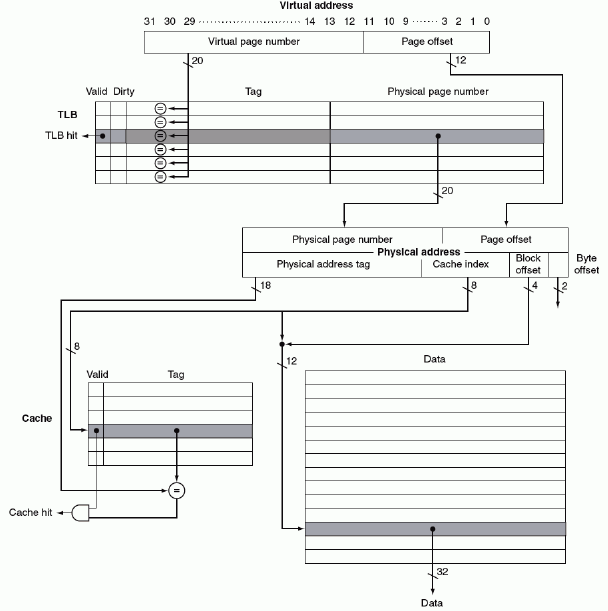
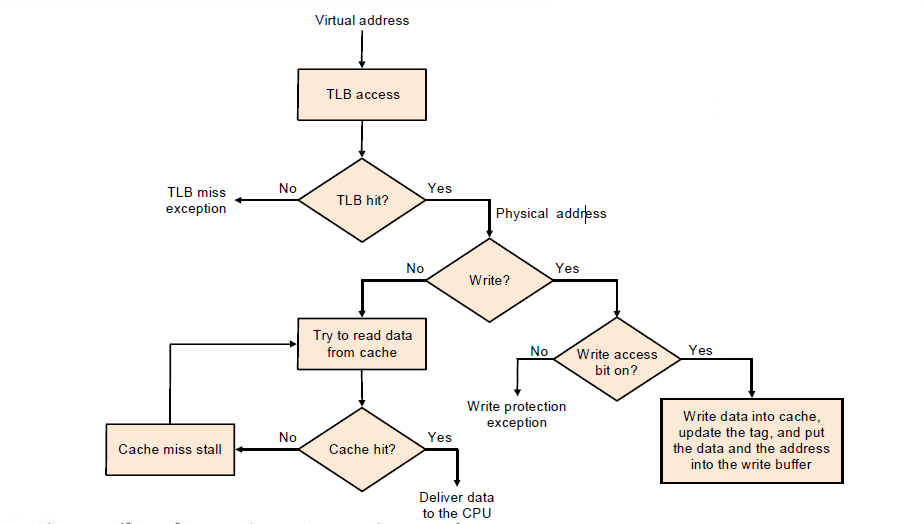
Virtual address先到TLB中进行寻找,miss执行TLB miss exception,hit得到对应的physical page number。然后我们根据physical page number的高位也就是physical address tag先到cache中进行寻找,如果cache找不到就再到内存中寻找
Possible combinations of Event

最后三个不可能。把page table当成memory即可,page table miss 意味着当前page在磁盘中,不在内存中,那么一定不在cache和TLB中
5.5.4 Page faults¶
When the OS creates a process, it usually creates the space on disk for all the pages of a process.
OS 启动时,把要用的 page 全部放到一个地方(swap space) 便于查找,记录页在硬盘的什么位置。(有的 OS 可能用另外的表来维护页在硬盘的位置)
- When a page fault occurs, the OS will be given control through exception mechanism.
- The OS will find the page in the disk by the page table.
- Next, the OS will bring the requested page into main memory. If all the pages in main memory are in use, the OS will use LRU strategy to choose a page to replace
Protection in the virtual memory System¶

只有操作系统知道其他进程的地址空间。