6. Storage, Networks and Other Peripherals¶
约 5903 个字 预计阅读时间 30 分钟
Abstract
- Introduction
- Disk Storage and Dependability
- Networks (Skim)
- Buses and Other Connections between Processors Memory, and I/O Devices
- Interfacing I/O Devices to the Memory, Processor, and Operating System
- I/O Performance Measures:
Examples from Disk and File Systems - Designing an I/O system
- Real Stuff: A Typical Desktop I/O System
6.1 Introduction¶
除了 CPU 的设备我们都认为是 I/O.
Assessing I/O system performance is very difficult.
不同的场景有不同的评估(可扩展性expandability, 可靠性resilience,performance)。
Performance of I/O system depends on:
- connection between devices and the system
- the memory hierarchy
- the operating system
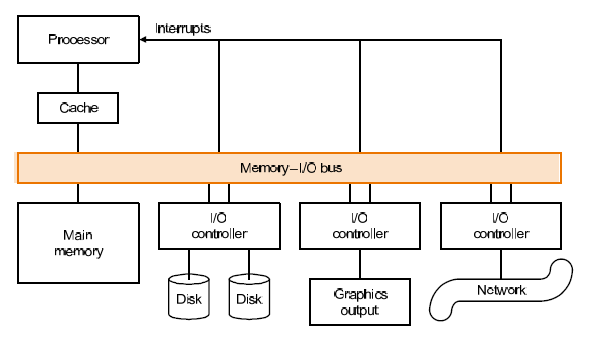
example: Typical collection of I/O device
CPU 和 I/O 由总线连接. I/O 往往通过中断的方式通知 CPU 有事件处理。
不同的设备有不同的驱动(I/O controller)
Three characters of IO
-
Behavior
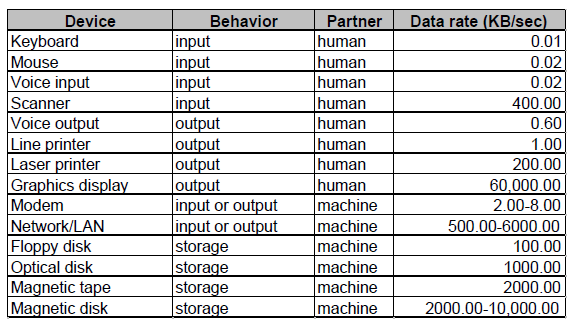
Input (read once), output (write only, cannot read) ,or storage (can be reread and usually rewritten) 输入/输出/存储
-
Partner
Either a human or a machine is at the other end of the I/O device, either feeding data on input or reading data on output. 和谁对接?人/机器
-
Data rate
The peak rate at which data can be transferred between the I/O device and the main memory or processor. 数据传输速率
I/O performance depends on the application.
-
Throughput 吞吐量/带宽
单位时间传输的数据量;单位时间 I/O 的操作数。-
How much data can we move through the system in a certain time?
例如,在许多超级计算机应用中,大多数 I/O 要求都是针对长数据流的,传输带宽是一个重要特性。
-
How many I/O operations can we do per unit of time?
例如,国家所得税局主要处理大量小文件。
-
-
Response time
e.g., workstation and PC
-
both throughput and response time e.g., ATM 不同的应用场景关心不同的方面。
6.1.1 Amdahl’s law¶
Sequential part can limit speedup。make common case fast 无法加速的部分会限制总体的加速

处理器的运行时间分为并行部分和串行部分,串行部分只需一个处理器即可,不发生改变,并行部分可以分摊到100个处理器。要想加速尽可能地明显,显然并行部分的时间需要尽可能的长,这样才能最大化减少运行时间。继而说明结论 Sequential part can limit speedup
Remind us that ignoring I/O is dangerous.

仅仅CPU性能提升,IO设备性能不变,总体的提升幅度会缩水
6.2 Disk Storage and Dependability¶
Two major types of magnetic disks
- floppy disks 软盘(内存)
- hard disks
- larger
- higher density
- higher data rate
- more than one platter
6.2.1 The organization of hard disk¶
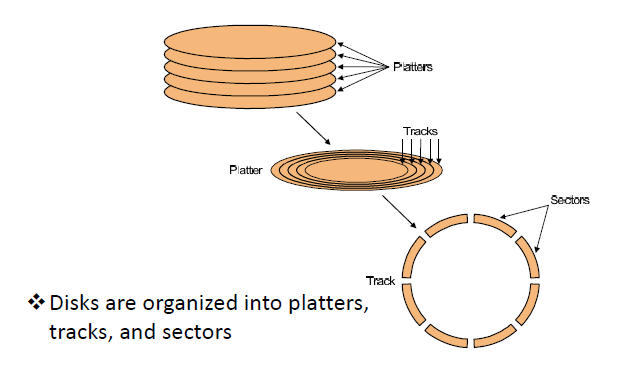
-
platters: disk consists of a collection of platters, each of which has two recordable disk surfaces
磁盘由一组盘片组成,每个盘片有两个可记录的磁盘表面
-
tracks: each disk surface is divided into concentric circles
每个圆盘表面被划分为同心圆
-
sectors: each track is in turn divided into sectors, which is the smallest unit that can be read or written
每个轨道依次划分为扇区,这是可以读或写的最小单位
6.2.2 To access data of disk¶
-
Seek: position read/write head over the proper track
数据不一定刚好在当前圈上,需要找到数据对应的圈。
average seek time(3 to 14 ms) -
Rotational latency: wait for desired sector
找到圈后,等待旋转到数据起点。
RPM : rotation per minute
-
Transfer: time to transfer a sector (1 KB/sector) function of rotation speed
把硬盘数据搬到内存。
-
Disk controller :which controls the transfer between the disk and the memory
Example "Disk Read Time"

6.2.3 Flash Storage¶
Nonvolatile semiconductor storage 非易失性半导体存储
- 100× – 1000× faster than disk
- Smaller, lower power, more robust
- But more $/GB (between disk and DRAM)
Flash Types
-
NOR flash: bit cell like a NOR gate
-
Random read/write access
可以随意读写
-
Used for instruction memory in embedded systems
因此在嵌入式中作为指令存储
-
-
NAND flash: bit cell like a NAND gate
-
Denser (bits/area), but block-at-a-time access
密度可以更高,但是读写要以 block 为单位,不能任意读写
-
Cheaper per GB
-
Used for USB keys, media storage
-
Flash bits wears out(磨损) after 100000’s of accesses.
寿命短。因此不适合做 RAM/硬盘的替代。 当已经被磨损时,就把本来的数据映射到其他内存。
6.2.4 Disk Performance Issues¶
一般得到的是 average seek time.

依靠操作系统的调度,disk controller的分配,以及prefetch,实现获取sector
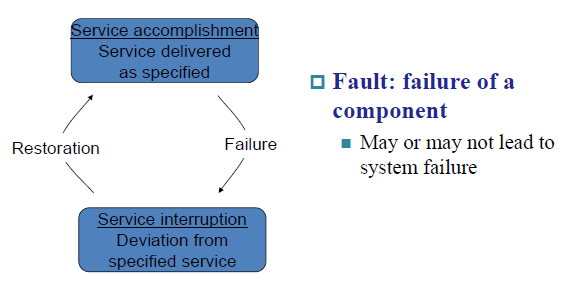
6.2.5 Dependability¶
衡量硬盘的指标就是可靠性 Dependability(Reliability).
Computer system dependability is the quality of delivered service such that reliance can justifiably be placed on this service. 连续提供服务的时间。
-
MTTF mean time to failure 平均无故障时间
-
MTTR mean time to repair 平均修复时间
-
MTBF (Mean Time Between Failures) 平均故障间隔时间
= MTTF+ MTTR
因此可用的时间就是 \(\dfrac{MTTF}{MTTF+MTTR}\)
平均故障间隔时间包括上一个故障的修复时间+平均无故障时间。在平均故障间隔时间内,可用的时间仅包括平均无故障时间,在修复时是不可用的
improve MTTF
Fault avoidance
preventing fault occurrence by construction 在硬盘寿命到达前替换硬盘
Fault tolerance
**using redundancy to allow the service to comply with the service specification despite faults occurring, which applies primarily to hardware faults **
使用冗余允许服务在发生故障时仍符合服务规范,主要适用于硬件故障
eg
多个地方备份,多个CPU同时计算Fault forecasting
predicting the presence and creation of faults, which applies to hardware and software faults 预测故障的存在和产生,适用于硬件和软件故障
6.2.6 Redundant Arrays of (Inexpensive) Disks¶
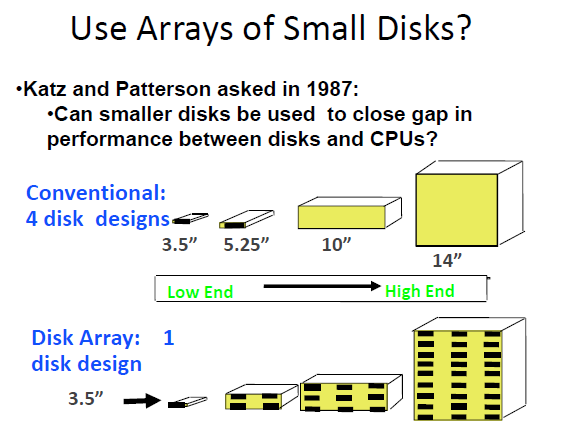
不同设备对硬盘的需求量不同。
能不能用小硬盘组合成大硬盘?
好处是可以有多个读写口,同时访问。坏处是坏掉的概率更大(只要一个小磁盘坏了,整个就坏了)。

Hot spares support reconstruction in parallel with access: very high media availability can be achieved. 热备份可以支持数据重建。
RAID: Redundant Arrays of Inexpensive Disks
-
Files are "striped" across multiple disks 文件保存在多个磁盘中
-
Redundancy yields high data availability
-
Disks will still fail
-
Contents reconstructed from data redundantly stored in the array
数据可以从冗余的用于备份的硬盘里恢复,代价是容量会有损失。
-
缺点:Capacity penalty to store redundant info 存储冗余信息的容量损失
Bandwidth penalty to update redundant info 更新冗余信息的带宽损失
widely used: Block-interleaved distributed parity,能够忍受一个磁盘的错误,需要一个磁盘进行检查
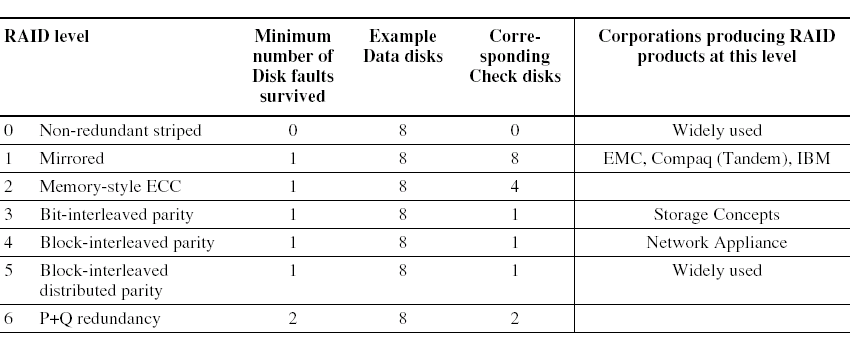
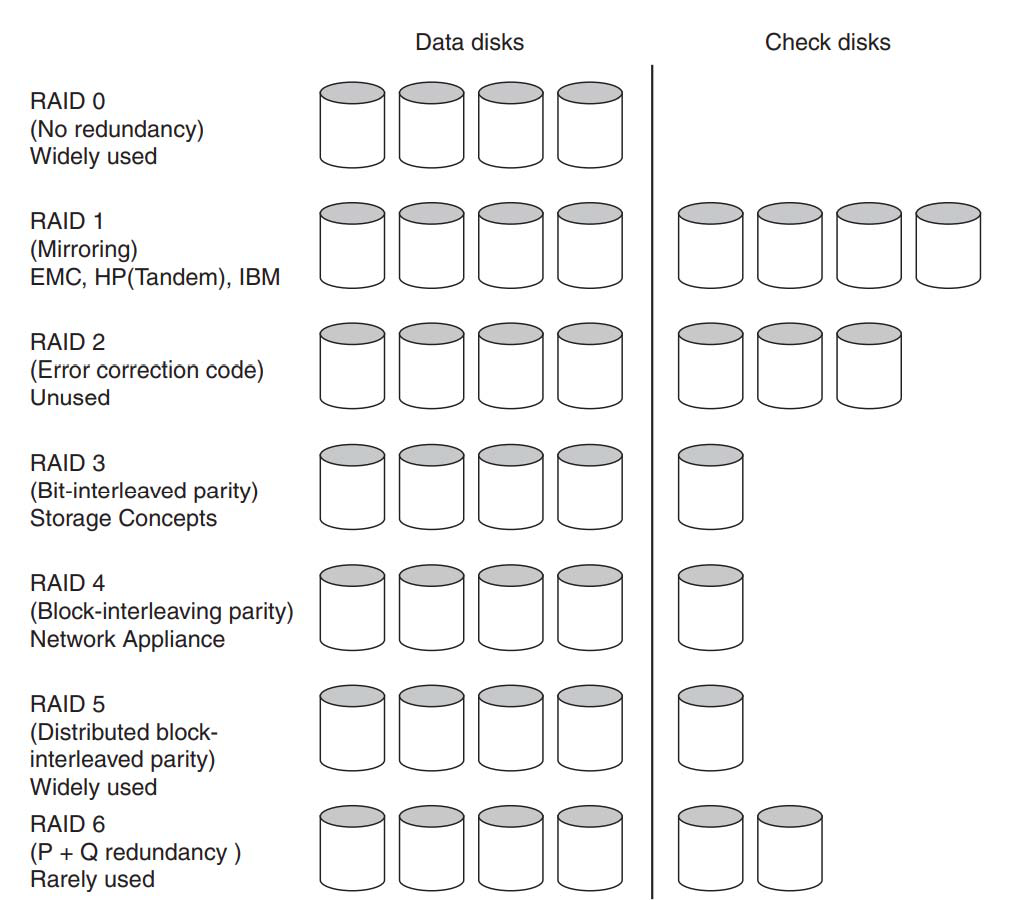
RAID 0: No Redundancy¶
Data is striped across a disk array but there is no redundancy to tolerate disk failure.
数据被放在多个盘里提高并行,速度可以提高(因为能同时访问)
RAID 0 something of a misnomer as there is no Redundancy
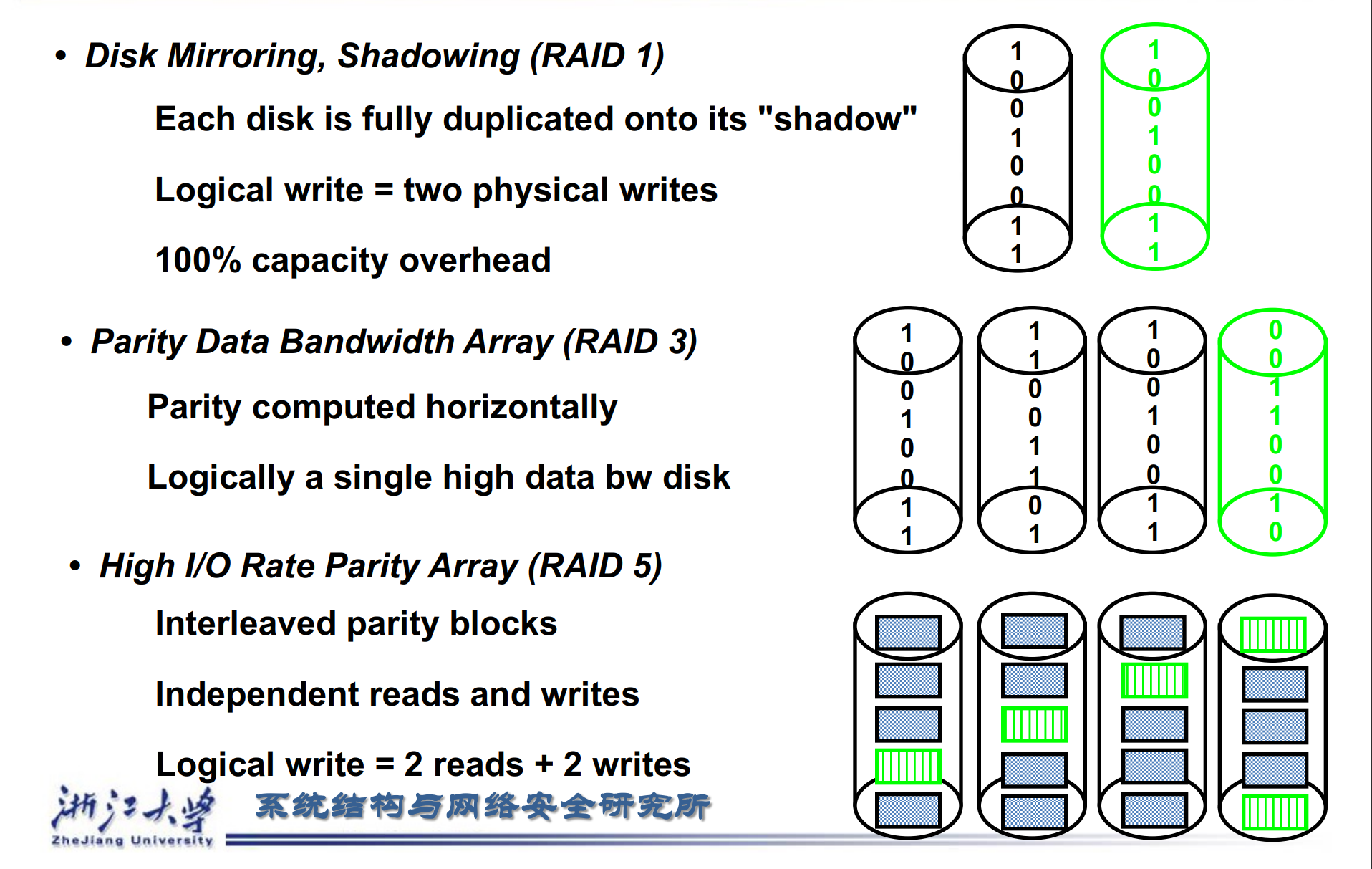
RAID 1: Disk Mirroring/Shadowing¶

-
Each disk is fully duplicated onto its “mirror”
每一个盘的内容都被复制放到另一个盘里。
-
Bandwidth sacrifice on write
写的时候需要同时写两个盘,读可能被优化。
-
Most expensive solution: 100% capacity overhead
RAID 3: Bit-Interleaved Parity Disk¶
P contains sum of other disks per stripe mod 2 (“parity”)
如第 1、2、3 个盘的第一个 bit 做奇偶校验放在第 4 个盘。
当其中一个盘挂掉的时候,读出其他盘的数据我们可以推出原来盘的数据。

RAID 4: Block-Interleaved Parity¶
RAID 3 relies on parity disk to discover errors on Read
RAID 3 依靠奇偶校验磁盘来发现读取时的错误
RAID 4 的改进之处:
Every sector has an error detection field
Relies on error detection field to catch errors on read, not on the parity disk
Allows independent reads to different disks simultaneously
允许同时对不同磁盘进行独立读取
我们希望自己的盘有自己的 error detection, 不需要校验盘来检验自己对不对,盘与盘之间没有依赖关系。也就是说自己知道自己是否出错
请注意:以下一个列表示一个disk,一个disk由很多的block组成,每一个block都有校验位

每个 block 做校验位(与其他盘无关,纵向计算校验位),放到备份盘中。
当我们同时读 D0, D5 时 Parity bit 会被读两次。
small write algorithm
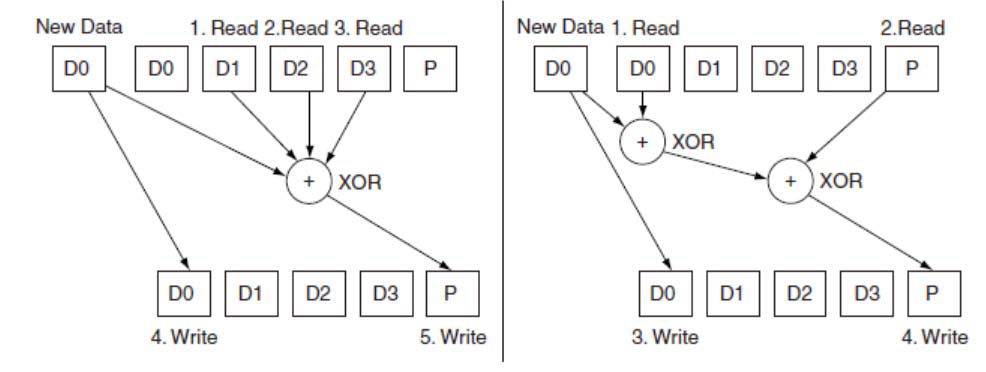
用new data D0替换原先的D0
-
方法一:读取D1,D2,D3,和D0进行XOR,将new data D0写入D0,校验结果写入P -
方法二:需要读取原数据D0,和new data D0进行比较,得到变化的bit在哪一位(XOR),然后读取P,更新变化的bit(XOR 1取反),将结果写回P
所以logical write = 2 reads + 2 writes
RAID 5: High I/O Rate Interleaved Parity¶
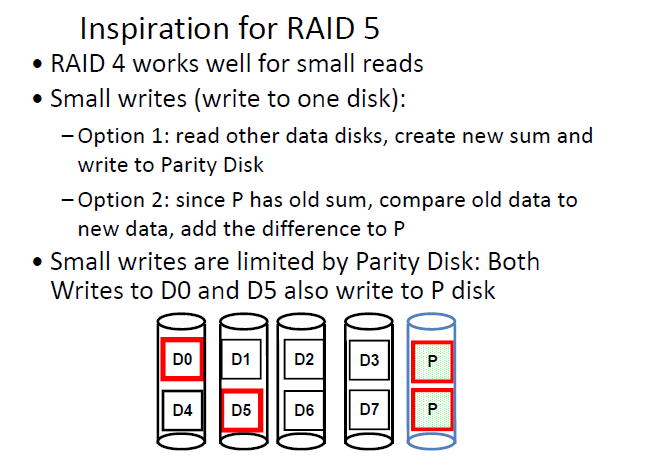
不能同时写D0和D5,因为它们都需要写P disk,造成冲突,但是对于同时读没有问题
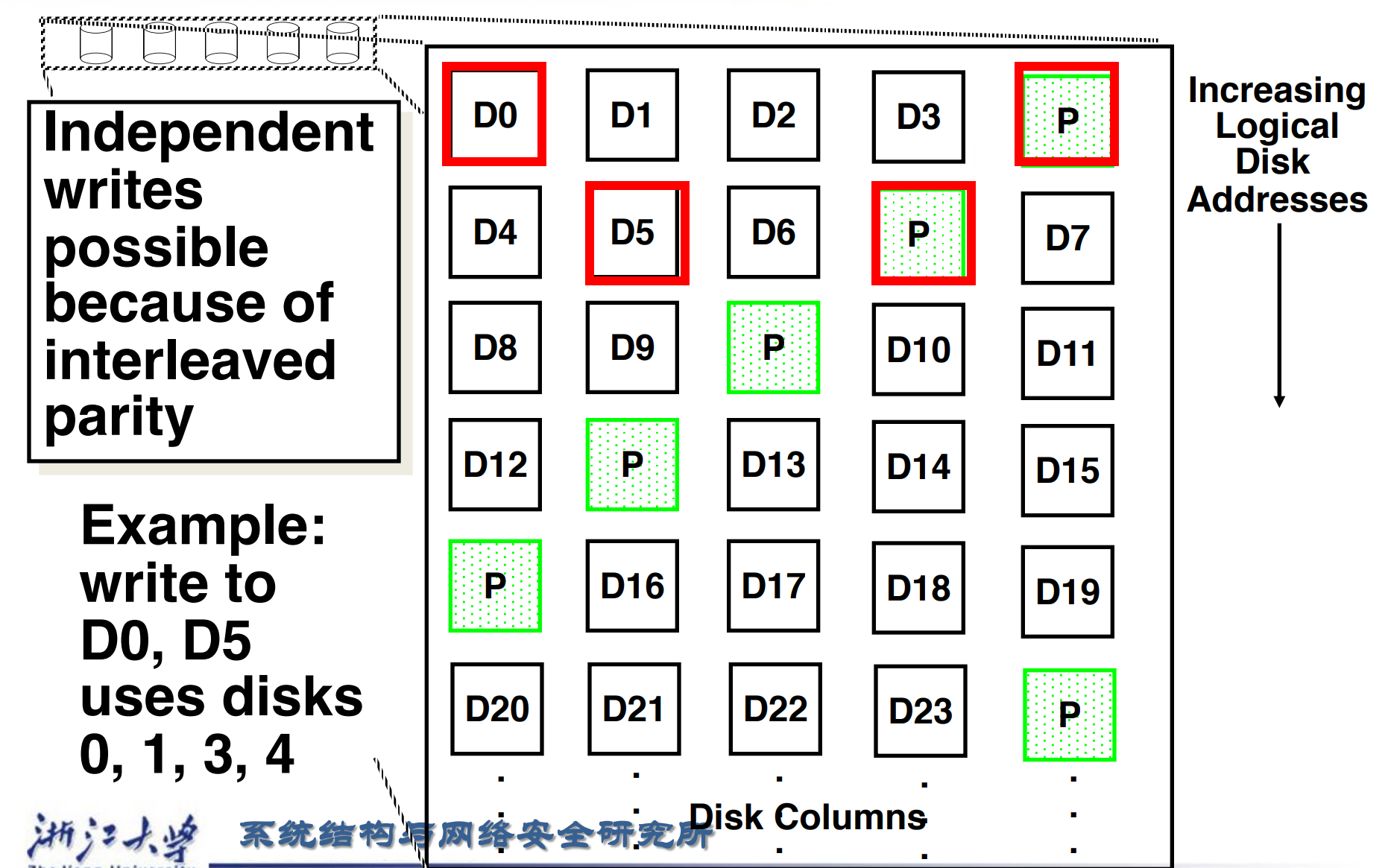
修改过后,存储校验位不再局限于某一个disk,而是分散开。例如block D4,D5,D6,D7的校验位放在Disk3的block P。这样同时写D0,D5时,即使修改P,也是修改不同的disk
RAID 6: P+Q Redundancy¶
有 P, Q 两位,可以恢复出两个盘的内容。
当单个故障校正不够时,可以将奇偶校验推广为对数据进行第二次计算和另一个信息检查盘。
Summary "RAID Techniques"

3. 对于small write,因为RAID3是位交叉,所有的disk都要read,然后计算校验码,写入到对应的disk中,所以RAID的速度最慢。对于RAID4,不能实现并行写入,但是RAID5能够实现同时写入,所以RAID5的throughput最大。
4. 对于large write,RAID3,4,5具有相同的throughput,因为所有的disk都需要read
6.3 Buses and Other Connections between Processors Memory, and I/O Devices¶
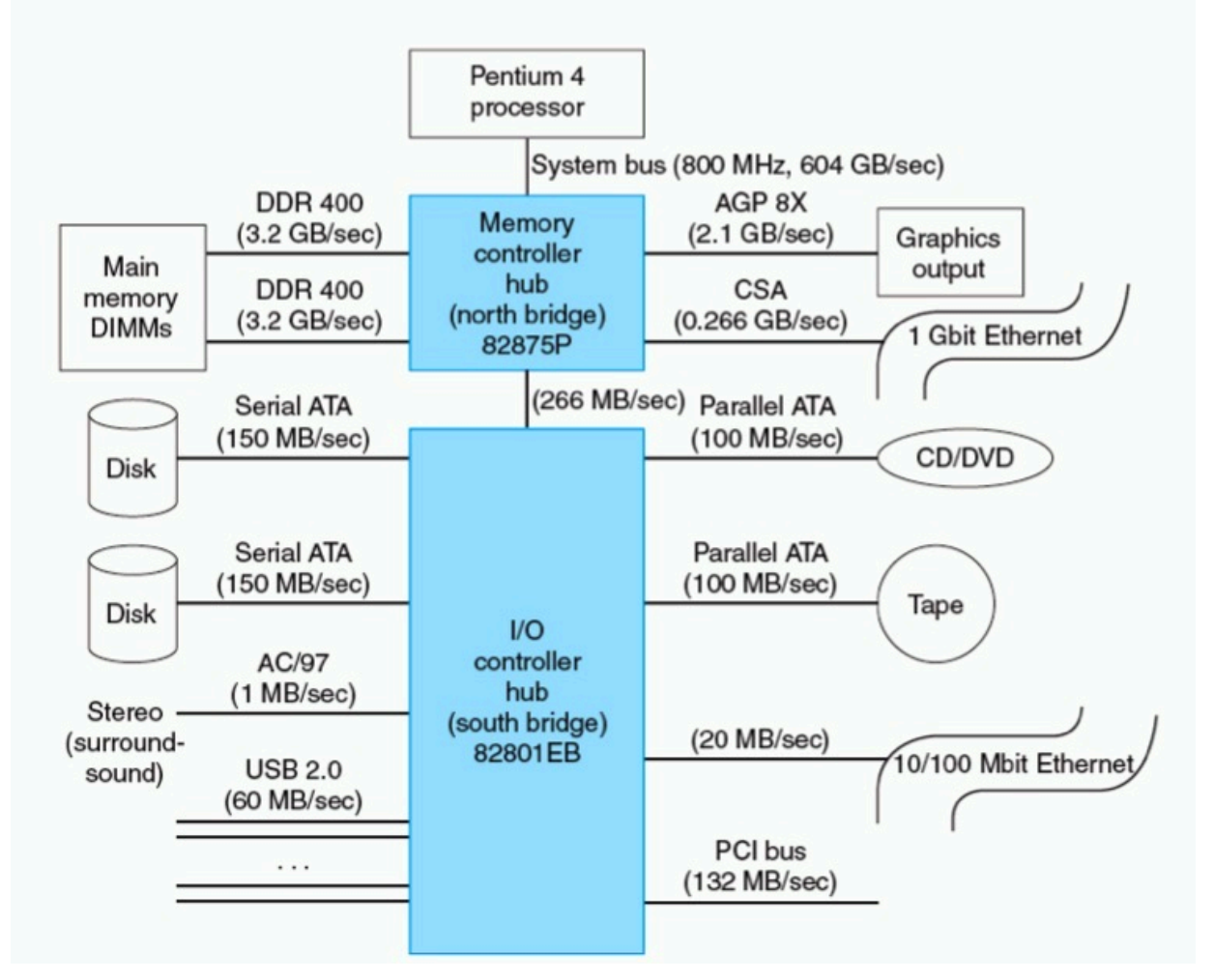
Bus: Shared communication link (one or more wires)
各种设备通过它进行通讯
Difficult Design:
-
may be bottleneck
很容易成为性能的 bottleneck(瓶颈).
-
length of the bus(
影响传输的速度) -
number of devices
-
tradeoffs (fast bus accesses and high bandwidth)
-
support for many different devices
-
cost
6.3.1 Bus Basics¶
总线不是一条线,而是多条线组合在一起。把各种路、设备连接起来。
A bus contains two types of lines
-
Control lines:
signal requests and acknowledgments, and to indicate what types of information is on the data lines.
比如给外设发送读取命令,外设发送可以读的信号。
-
Data lines:
carry information (e.g., data, addresses, and complex commands) between the source and the destination.
Bus transaction
sending the address and receiving or sending the data
总线传输的两部分,送地址,送数据。
include two parts: sending the address and receiving or sending the data
- input: inputting data from the device to memory
- output: outputting data to a device from memory
站在memory的角度,momory获得数据成为input,momory输出数据到device成为output
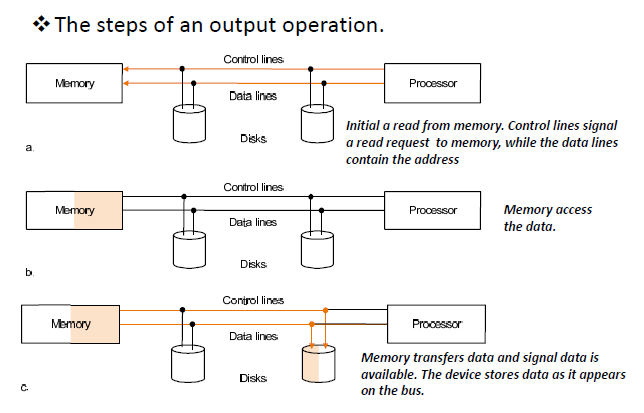
初始化在内存中的read,control line传输一个read信号,data line传出read的地址addressmomory 根据地址取出数据,然后告诉处理器自己准备好了memory传输控制信号和数据,devices接受总线上的数据
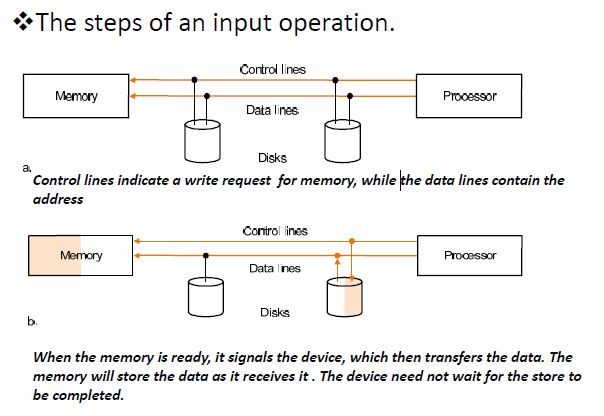
处理器向内存发送write信号,data line传输 write 的地址当内存准备就绪时,它会向设备发出信号,然后设备传输数据。内存将在接收数据时存储数据。设备无需等待存储完成。
Types of buses
-
processor-memory : short high speed, custom design)
CPU和memory之间的总线
-
backplane : high speed, often standardized, e.g., PCI)
所有的IO设备连接到backplane,然后通过backplane和CPU进行交互
-
I/O : lengthy, different devices, standardized, e.g., SCSI)
IO设备直接和CPU进行连接

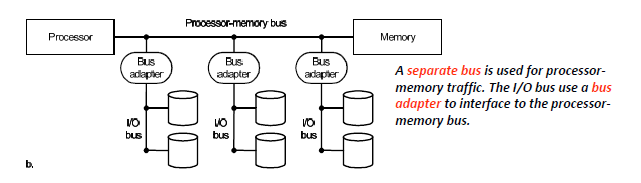
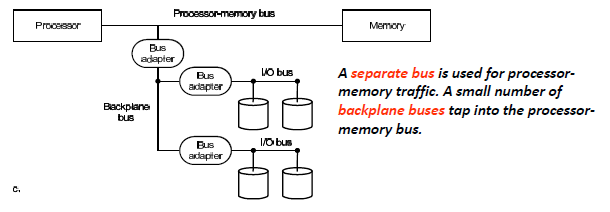
-
Older PCs often use a single bus for processor‐to‐memory communication, as well as communication between I/O devices and memory.
较旧的 PC 通常使用单总线(backplane)进行处理器到内存的通信,以及 I/O 设备和内存之间的通信。IO设备直接连接到backplane上,他们的速度需要遵守一样的协议。速度慢由于只有一条bus,所以processor和某一个device通信的时候,便不能和其他设备通信,同理其他设备和其他设备之间也不行
-
A separate bus is used for processor memory traffic. The I/O bus use a bus adapter to interface to the processor memory bus.
memory和process之间的传输依靠processor-memory bus,I/O bus 使用bus adapter连接到处理器和内存的主线遵循不同协议,速度有快有慢
-
A separate bus is used for processor memory traffic. A small number of backplane buses tap into the processor memory bus.
在2的基础上,添加backplane背板总线,I/O设备同意通过bus adapter连接到backplane,然后backplane连接到处理器和内存的主线
6.3.2 Synchronous vs. Asynchronous¶
同步总线或者异步总线
-
Synchronous bus: use a clock and a fixed protocol, fast and small but every device must operate at same rate and clock skew requires the bus to be short
同步总线:
使用时钟和固定的协议,快速且小巧,但每个设备必须以相同的速率运行,由于时钟偏移的存在要求总线短clock skew, 即上升沿无法对齐(
总线短,传输延迟低,始终偏差小) -
Asynchronous bus: don’t use a clock and instead use handshaking
异步总线:
不要使用时钟,而是使用握手协议Handshaking protocol:A serial of steps used to coordinate asynchronous bus transfers.
用于协调异步总线传输的一系列步骤。
Asynchronous example 异步传输的例子
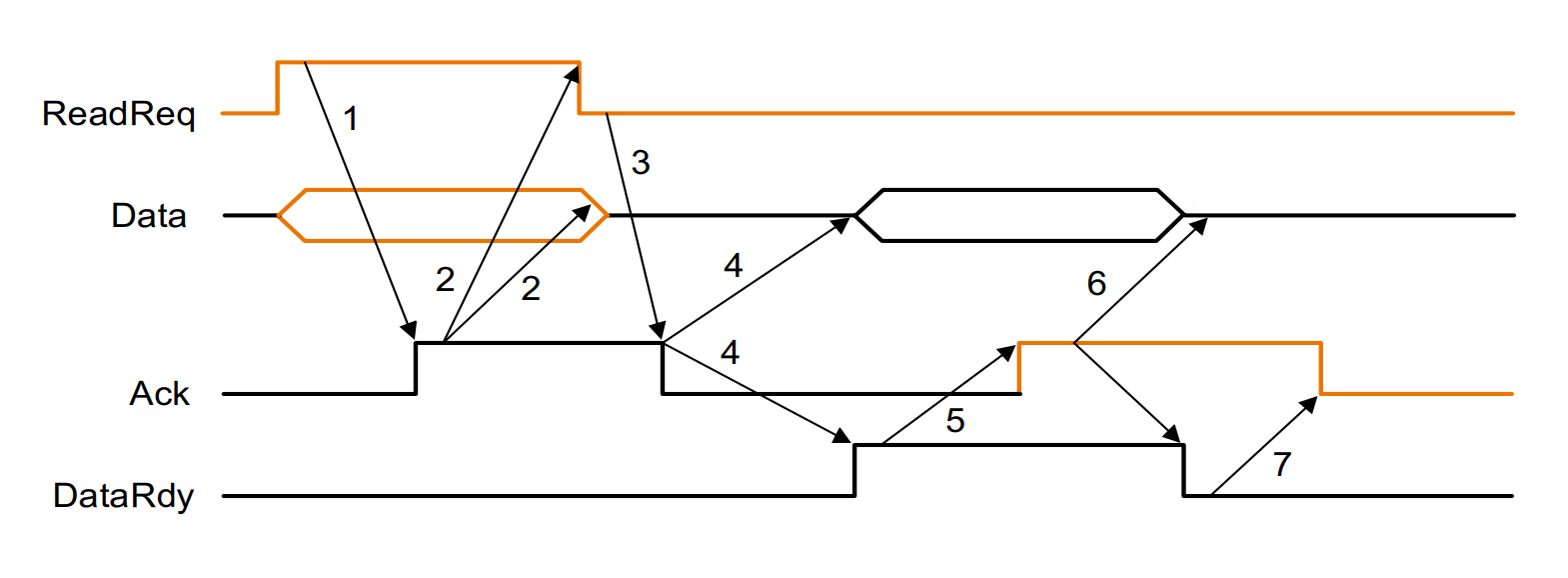
-
When memory sees the ReadReq line, it reads the address from the data bus, begin the memory read operation,then raises Ack to tell the device that the ReadReq signal has been seen.
读数据时, CPU 把 read request 拉起来。内存看到后,会把 Data 总线上的数据读走(即地址),随后进行内存读取,同时把 Ack 信号拉起来,告诉 IO 设备我们已经接收到 read request 了.
-
I/O device sees the Ack line high and releases the ReadReq data lines.
IO 设备看到 Ack 后把自己的 read request 放下
-
Memory sees that ReadReq is low and drops the Ack line.
内存看到 read request 放下后,把 Ack 也放下
-
When the memory has the data ready, it places the data on the data lines and raises DataRdy.
内存读出数据后,会把 data ready 拉起来,把数据放在 data line 上
-
The I/O device sees DataRdy, reads the data from the bus , and signals that it has the data by raising ACK.
IO 设备看到 data ready 后会把数据取走,并把 Ack 信号拉起
-
The memory sees Ack signals, drops DataRdy, and releases the data lines.
内存看到 Ack 信号后会放下 data ready 信号
-
Finally, the I/O device, seeing DataRdy go low, drops the ACK line, which indicates that the transmission is completed.
随后 IO 设备放下 ack 信号
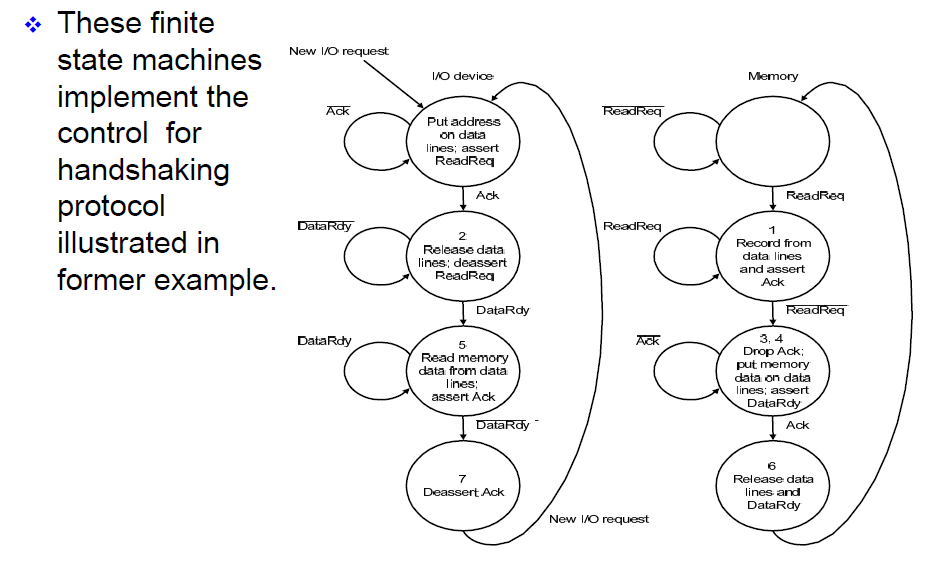
-
6.3.3 Bus Arbitration¶
multiple device desiring to communicate could each try to assert the control and data lines for different transfers.
a bus master is needed. Bus masters initiate and control all bus requests.
总线上有很多设备,多个设备要访问同一个内存时,需要总线仲裁,获得总线的所有权。
实际上现在 master 的设备也有多个,不同 master 之间也有竞争(CPU, 显存等都是一个 master)。
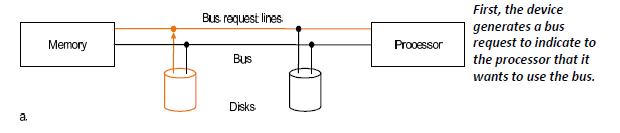
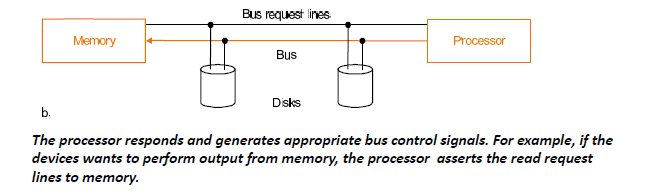
-
First, the device generates a
bus requestto indicate to the processor that it wants to use the bus.首先,设备生成总线请求,向处理器指示它要使用总线。
-
The processor responds and generates appropriate
bus control signals. For example, if the devices wants to perform output from memory, the processor asserts the read request lines to memory.处理器响应并生成适当的总线控制信号。例如,如果设备想要从内存执行输出,则处理器会将读取请求行置位到内存。
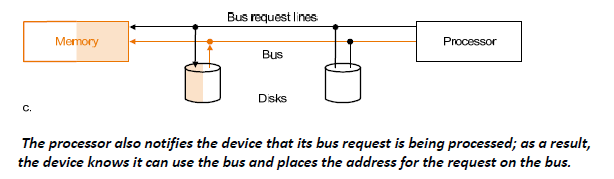
-
The processor also notifies the device that its bus request is being processed; as a result, the device knows it can use the bus and places the address for the request on the bus.
处理器还通知设备其总线请求正在处理中;因此,设备知道它可以使用总线,并将请求的地址放在总线上。
上面的例子中只有一个 CPU 是 master, 可以占领总线,并让 IO 设备执行操作。
能主动发起操作(操作 Bus)的设备叫做 Bus Master, 一般是 CPU.
决定哪个 master 能够操作总线的设备叫做总线仲裁。
一般都是多个设备共享一条总线进行数据通信,其中如果多个设备同时发送接收数据的话,从而产生总线竞争,会导致通信冲突导致通信失败,所以在总线上要引入一个仲裁机制来决定什么时间谁来占用总线的通信
Deciding which device gets to use the bus next
four bus arbitration schemes:
- daisy chain arbitration (not very fair): 靠近master的优先占用总线
- centralized, parallel arbitration (requires an arbiter), e.g., PCI
- self selection, e.g., NuBus used in Macintosh
- collision detection, e.g., Ethernet
Two factors in choosing which device to grant the bus:
-
bus priority
-
fairness
公平性,不让某个设备一直占用总线。
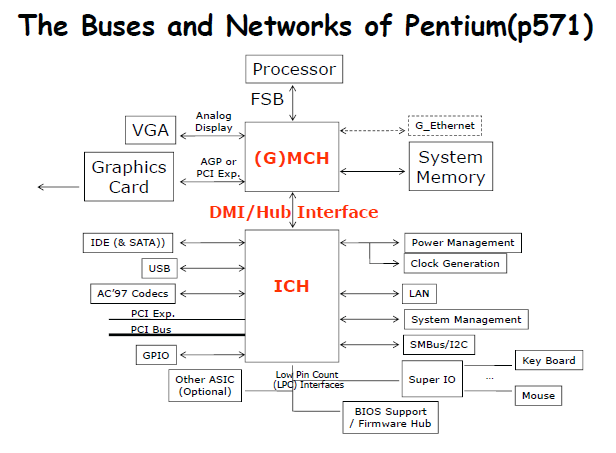
Performance analysis of Synchronous versus Asynchronous buses¶
评价总线的性能 - 带宽 bandwidth
Example

200-ns memory 表示内存从收到地址到准备好数据需要200ns
一次传输32bits,也就是4Bytes,对应的时间包括发送地址50ns,寻找数据200ns,发送数据到设备50,一共300ns,然后计算带宽

握手时间和在内存中寻找数据的时间存在着重叠。异步时钟 step1 结束时内存已经拿到地址了,这个过程中 step234 可以同时做。
也就是说step1是发送地址接收地址,step234是在内存中寻找数据,step567是返回对应的数据。per handshake的时间是40ns。其中在内存中找数据需要与200ns memory比较
一共就是40 + 200 + 120 = 360ns
-
When memory sees the ReadReq line, it reads the address from the data bus, begin the memory read operation,then raises Ack to tell the device that the ReadReq signal has been seen.
读数据时, CPU 把 read request 拉起来。内存看到后,会把 Data 总线上的数据读走(即地址),随后进行内存读取,同时把 Ack 信号拉起来,告诉 IO 设备我们已经接收到 read request 了.
-
I/O device sees the Ack line high and releases the ReadReq data lines.
IO 设备看到 Ack 后把自己的 read request 放下
-
Memory sees that ReadReq is low and drops the Ack line.
内存看到 read request 放下后,把 Ack 也放下
-
When the memory has the data ready, it places the data on the data lines and raises DataRdy.
内存读出数据后,会把 data ready 拉起来,把数据放在 data line 上
-
The I/O device sees DataRdy, reads the data from the bus , and signals that it has the data by raising ACK.
IO 设备看到 data ready 后会把数据取走,并把 Ack 信号拉起
-
The memory sees Ack signals, drops DataRdy, and releases the data lines.
内存看到 Ack 信号后会放下 data ready 信号
-
Finally, the I/O device, seeing DataRdy go low, drops the ACK line, which indicates that the transmission is completed.
随后 IO 设备放下 ack 信号
-
Increasing data bus width
-
Use separate address and data lines
-
transfer multiple words
一次传输多个数据
Increasing the Bus Bandwidth

1个block能够存储4到16个words,传输以block为单位
同步总线传输的位数是64位,传输地址和传输数据所需时间为1个clock cycle
每一个bus operation中间需要间隔2个cycle
memory access time在内存中寻找数据的时间,对于前四个words,需要使用200ns,后续每四个words只需要20ns,也就是说起步慢,后续快
burst 传输,地址发一次,读多个数据。如读地址 4, 我们可以返回 4 5 6 7 的数据。
- the 4-word block transfers


地址只需要传输一次,就能够读取多个数据。由于总线一个cycle只能传输64bits,所以4个words需要2个cycle,已知总线频率是200MHz,对应的一个cycle的时间就是5ns,就能计算出read memory所需的时间为40cycles。对于4个word,就需要1+40+2+2 = 45cycles。一共有64个block
- the 16-word block transfers

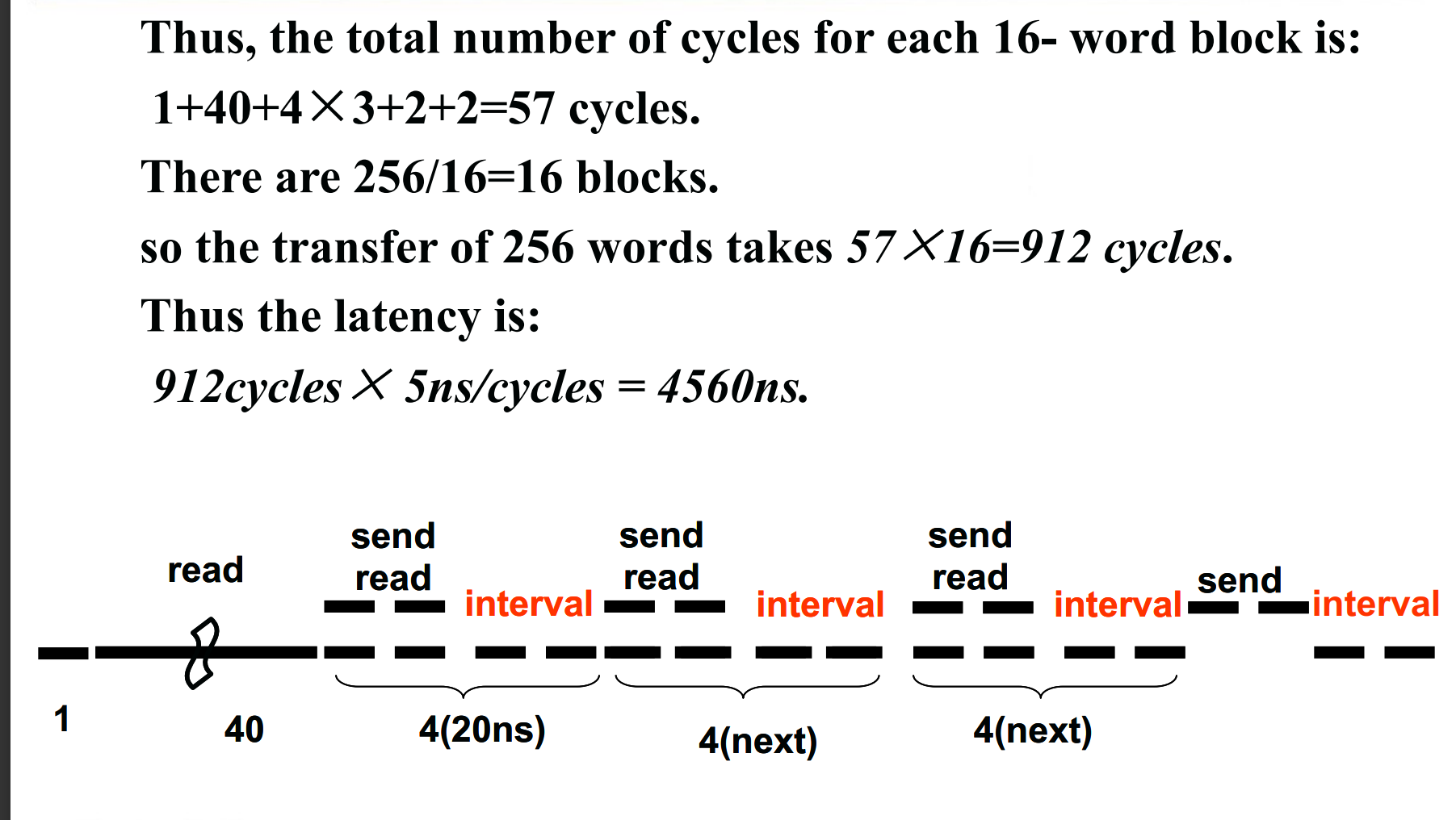
read memory 和 transfer data能够重叠

6.4 Interfacing I/O Devices to the Memory, Processor, and Operating System¶
Three characteristics of I/O systems
-
shared by multiple programs using the processor.
-
often use interrupts to communicate information about I/O operations.
通常使用中断来传达有关 I/O 操作的信息。
-
The low‐level control of I/O devices is complex
Three types of communication are required:
IO 设备(需要驱动)怎么和 OS 通信
-
The OS must be able to give commands to the I/O devices.
OS 要能给 IO 设备发出命令,比如启动、关机。
-
The device must be able to notify the OS, when I/O device completed an operation or has encountered an error.
IO 有方式,在设备完成操作或者遇到错误时,要能通知 OS.
比如打印结束,可以继续传输数据了。
-
Data must be transferred between memory and an I/O device.
数据要能在内存和 IO 设备之间传输。
Give commands to I/O Devices
CPU 要能访问到 IO 设备,需要有一个地址。(注意这个地址不能进入 cache, 否则我们就无法获得 IO 设备的最新状态了)
-
memory-mapped I/O
把内存地址中的一部分分出来给 IO 设备用,这样就可以用 ld sd 来访问。
-
special I/O instructions
e.g. x86 中 in al,port out port,al. RISC-V 中没有
IO 设备需要有对应的寄存器存储状态
- The Status register (a done bit, an error bit...)
- The Data register, The command register
6.4.1 Communication with the Processor¶
-
Polling: The processor periodically checks status bit to see if it is time for the next I/O operation.
处理器定期检查状态位以查看是否到了进行下一次 I/O 操作的时间。但是会占用 CPU.
-
Interrupt: When an I/O device wants to notify processor that it has completed some operation or needs attentions, it causes processor to be interrupted.
当 IO 设备完成操作给 CPU 一个中断,等待其响应。好处是 CPU 可以一直做自己的事情。
-
DMA (direct memory access): the device controller transfer data directly to or from memory without involving processor.
DMA(直接内存访问):设备控制器无需处理器即可直接向内存传输数据或从内存传输数据,不需要 CPU 参与。
Interrupt-Driven I/O mode¶
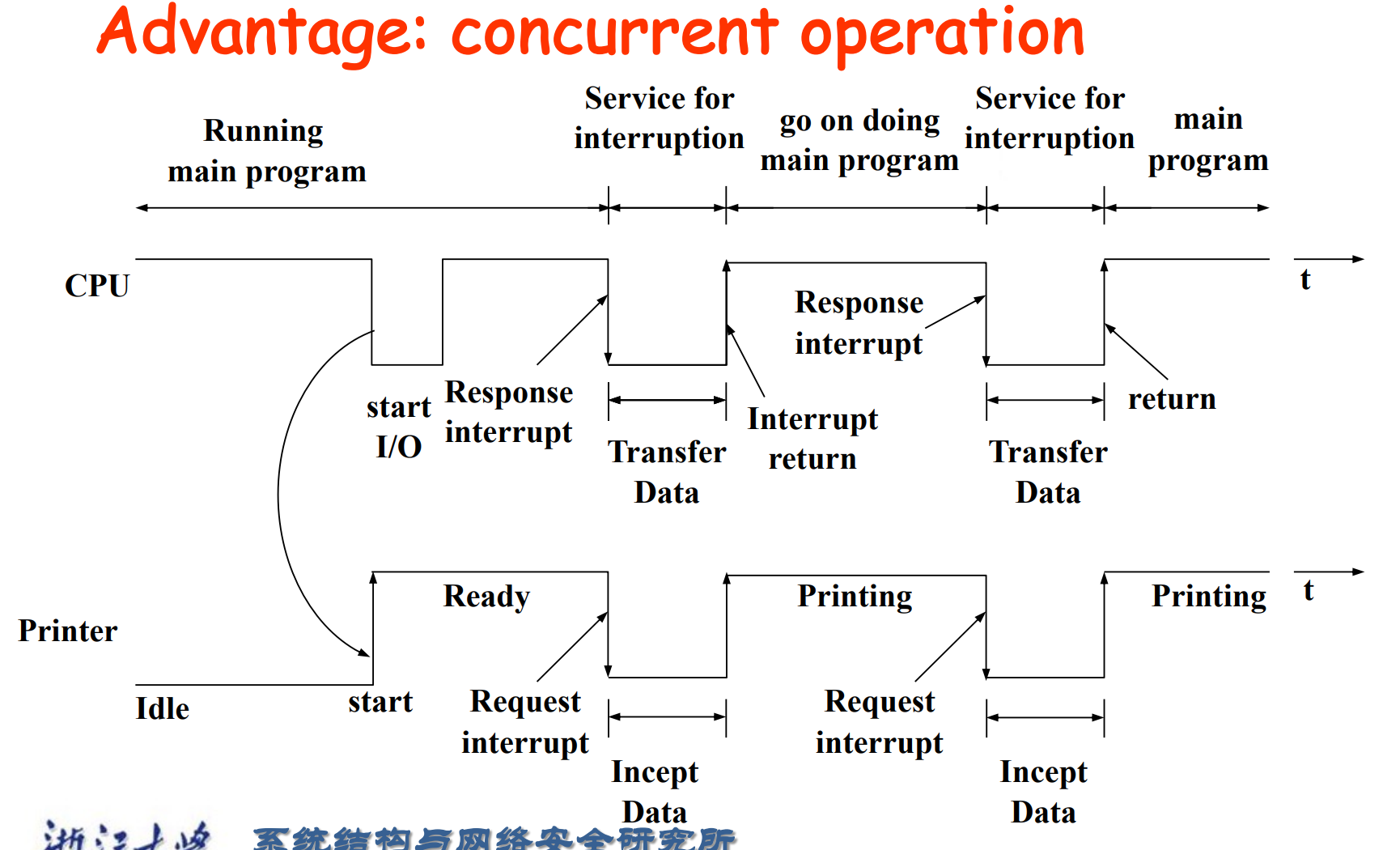
假设 IO 是个打印机。每次打印一个字符,就会给 CPU 发一个中断。CPU 会去读取打印机的状态,看是否完成。完成后 CPU 继续做自己的事情。
DMA transfer mode¶
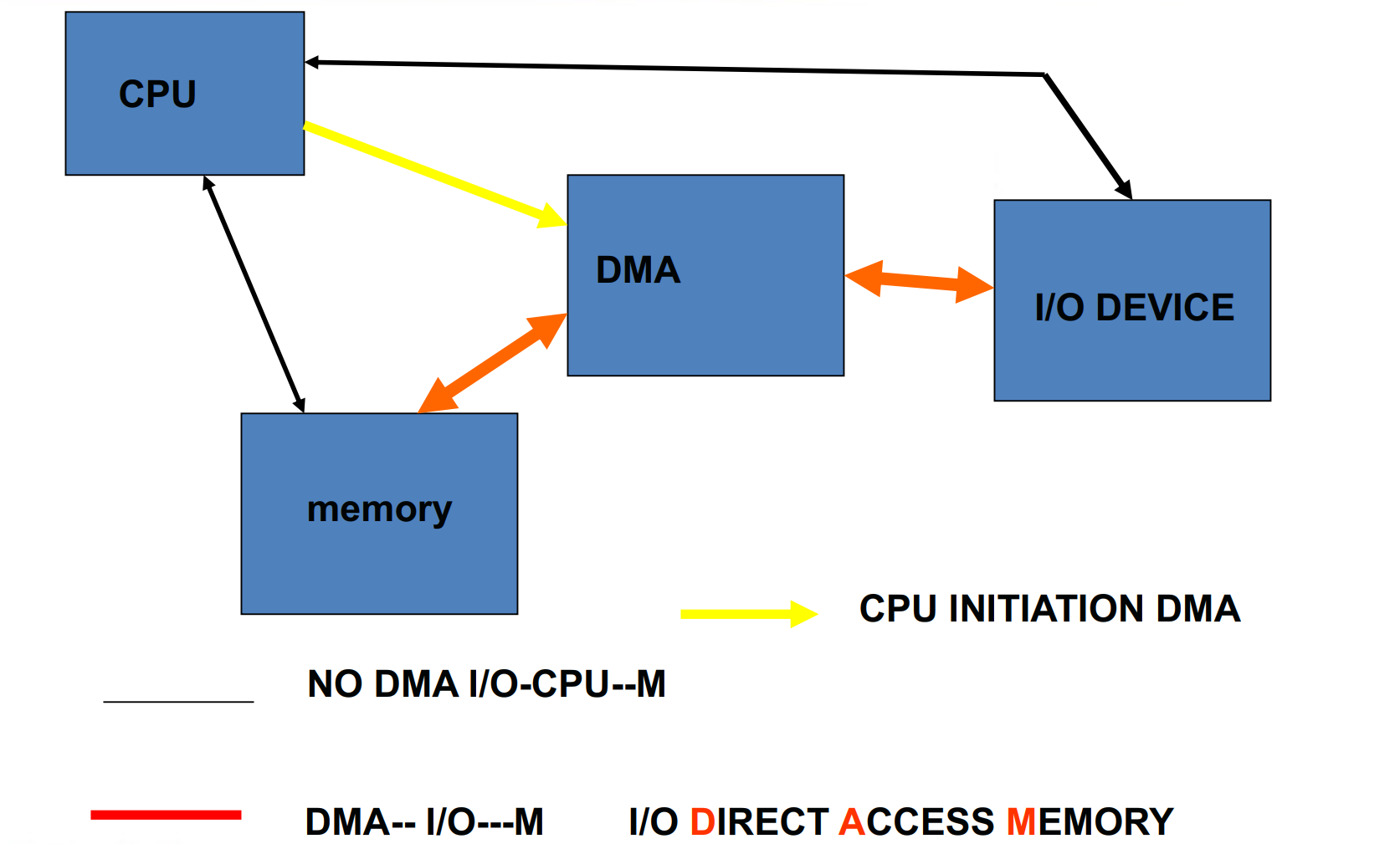
CPU 需要配置 DMA. DMA 会和 IO 设备交互,把数据搬到内存,不需要 CPU 参与。
A DMA transfer need three steps:
-
The processor sets up the DMA by supplying some information, including the identity of the device, the operation, the memory address that is the source or destination of the data to be transferred, and the number of bytes to transfer.
CPU 配置 DMA,包括哪个设备、做什么操作、内存地址、数据大小等。
-
The DMA starts the operation on the device and arbitrates for the bus. If the request requires more than one transfer on the bus, the DMA unit generates the next memory address and initiates the next transfer.
DMA 开始操作设备,占用总线。如果需要多次传输,DMA 会生成下一个内存地址,开始下一次传输。 DMA 也是挂在总线上的 master, 优先级没有 CPU 高。因此他会趁 CPU 空闲的时候搬运数据,可以充分利用总线。
-
Once the DMA transfer is complete, the controller interrupts the processor, which then examines whether errors occur.
DMA 完成后,给 CPU 发中断,CPU 检查是否有错误。
Note "Compare polling, interrupts, DMA"
The disadvantage of polling is that it wastes a lot of processor time. When the CPU polls the I/O device periodically, the I/O devices maybe have no request or have not get ready.
polling 的坏处是浪费了大量的 CPU 的时间。CPU 定期轮询 IO 设备可能没有请求或者没有准备好。
If the I/O operations is interrupt driven, the OS can work on other tasks while data is being read from or written to the device.
如果 IO 操作是中断驱动的,OS 可以在数据从设备读取或写入时处理其他任
Because DMA doesn’t need the control of processor, it will not consume much of processor time.
DMA 不需要 CPU 控制,不会消耗 CPU 时间。
但 DMA 其实只是搬运数据时有用,其实和 polling interrupt 不对立。
Overhead of Polling in an I/O System



Overhead of Interrupt-Driven I/O


polling 必须时时刻刻查询,中断只需要在真正有数据传输(比如 5% 的时间)时再去处理。
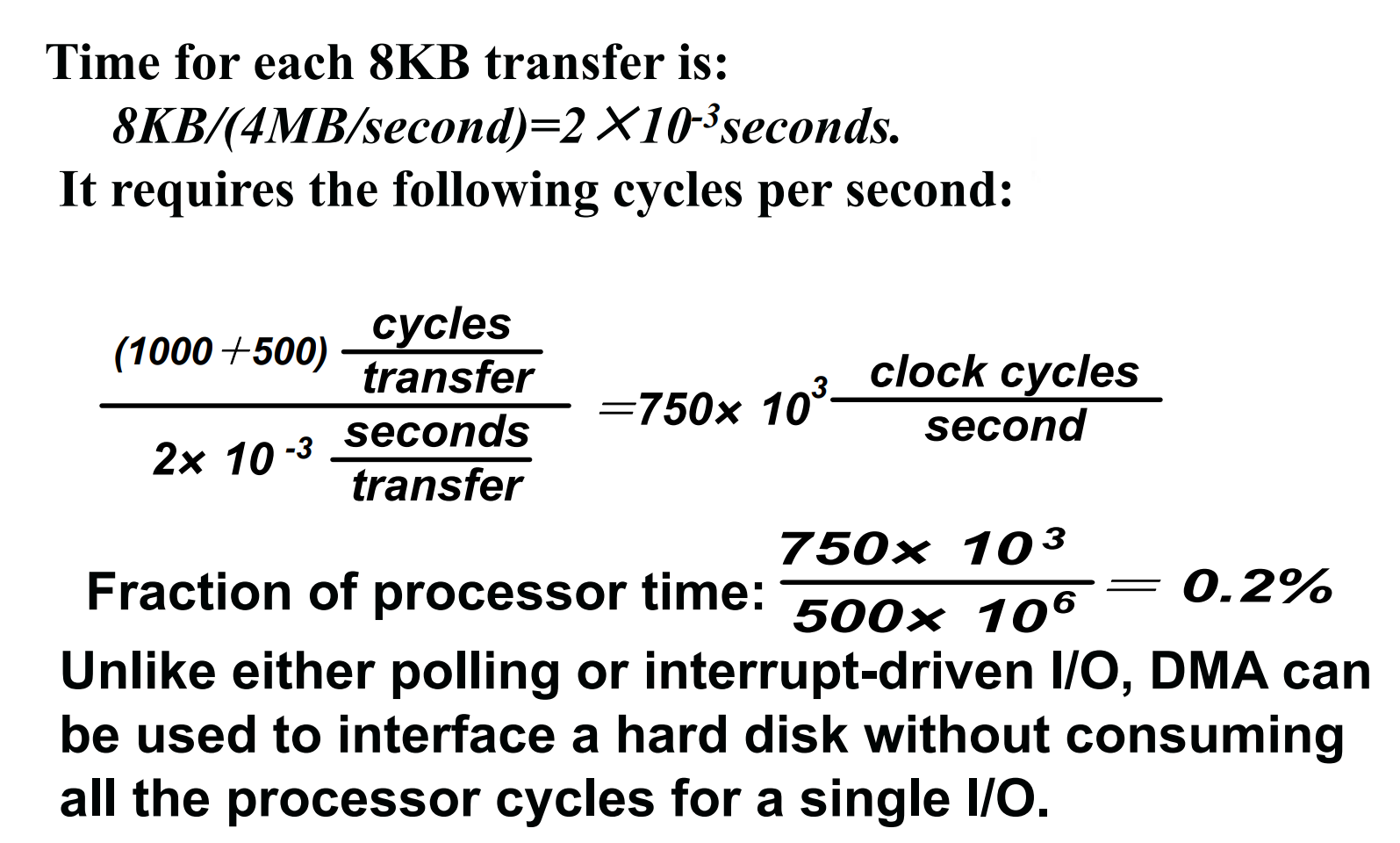
Overhead of I/O Using DMA

6.5 I/O Performance Measures: Examples from Disk and File Systems¶
CPU 有 benchmark, IO 也有 benchmark 来衡量性能。
I/O rate: the number of disk access per second, as opposed to data rate
Designing an I/O system¶
整个计算机系统 CPU+bus+I/O
-
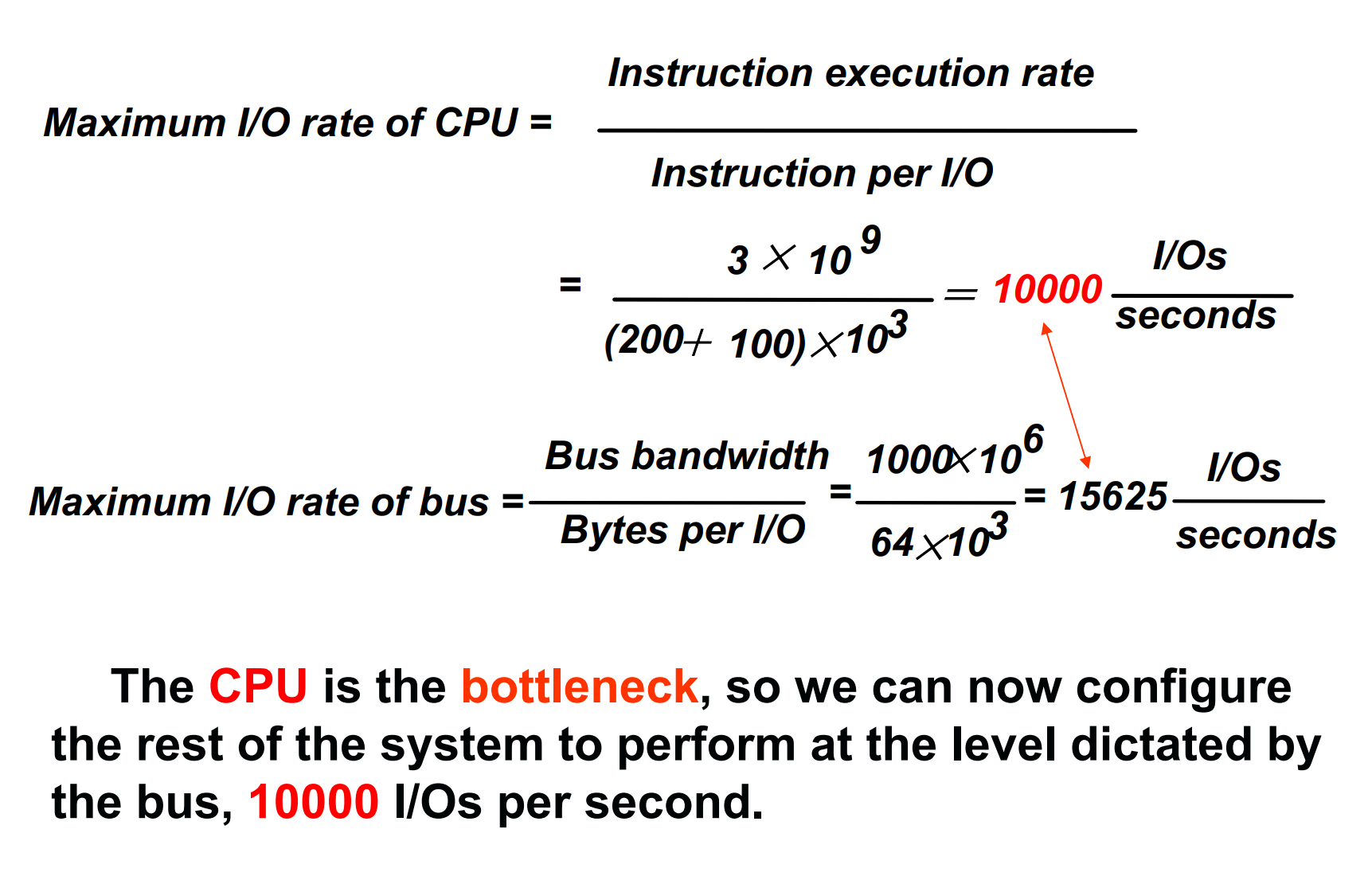
Find the weakest link in the I/O system, which is the component in the I/O path that will constrain the design. Both the workload and configuration limits may dictate where the weakest link is located.
找到 I/O 系统中最薄弱的环节,即 I/O 路径中会限制设计的组件。工作负载和配置限制都可能决定最薄弱的环节位于何处。
速度由最慢的决定。 看哪个部分最弱,其他部分保证可以满足最弱的条件即可。
-
Configure this component to sustain the required bandwidth.
-
Determine the requirements for the rest of the system and configure them to support this bandwidth.
Example