11. Query Processing¶
约 10045 个字 预计阅读时间 50 分钟
Abstract
- Basic Steps in Query Processing
- Measures of Query Cost
- Selection Operation
- Sorting
- Join Operation
- Other Operations
- Evaluation of Expressions
11.1 Basic Steps in Query Processing¶

-
Parsing and translation
语法检查-
translate the query into its internal form. This is then translated into relational algebra.
将查询转换为其内部形式。然后将其转换为关系代数。
-
Parser checks syntax, verifies relations
-
解析器检查语法,验证关系
-
-
Optimization
- Amongst all equivalent evaluation plans choose the one with lowest cost.
-
Evaluation
-
The query-execution engine takes a query-evaluation plan, executes that plan, and returns the answers to the query.
查询执行引擎采用查询评估计划,执行该计划,并返回查询的答案。
-
经过语法分析、语义检查翻译成关系表达式,经过查询优化转化成执行计划(目标代码),由求值引擎得到输出。
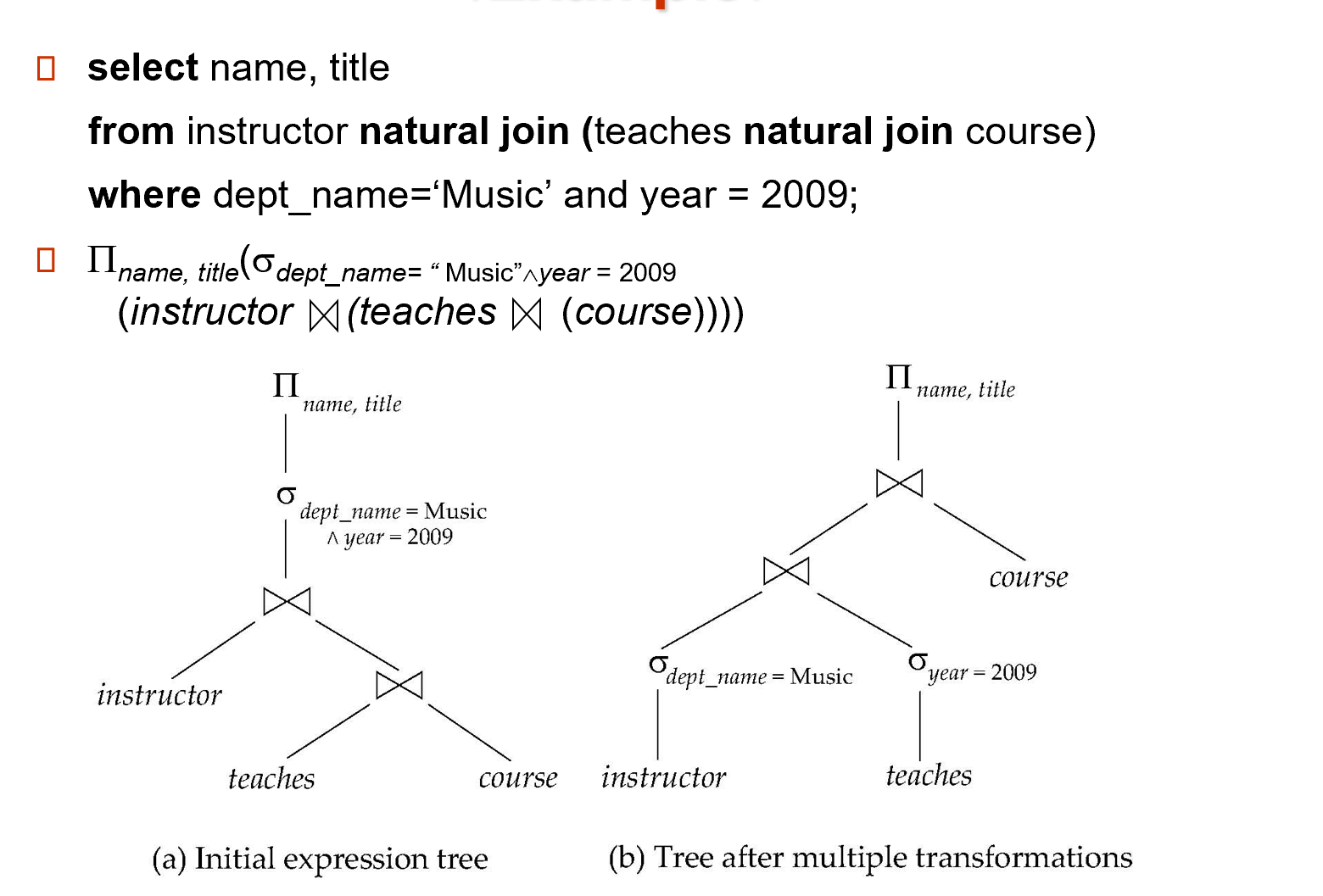
逻辑优化:把选择运算往叶子上推;先连接的是结果比较小的(使用的存储空间较小)。
An evaluation plan defines exactly what algorithm is used for each operation, and how the execution of the operations is coordinated.
评估计划准确定义了每个操作使用的算法,以及如何协调操作的执行。
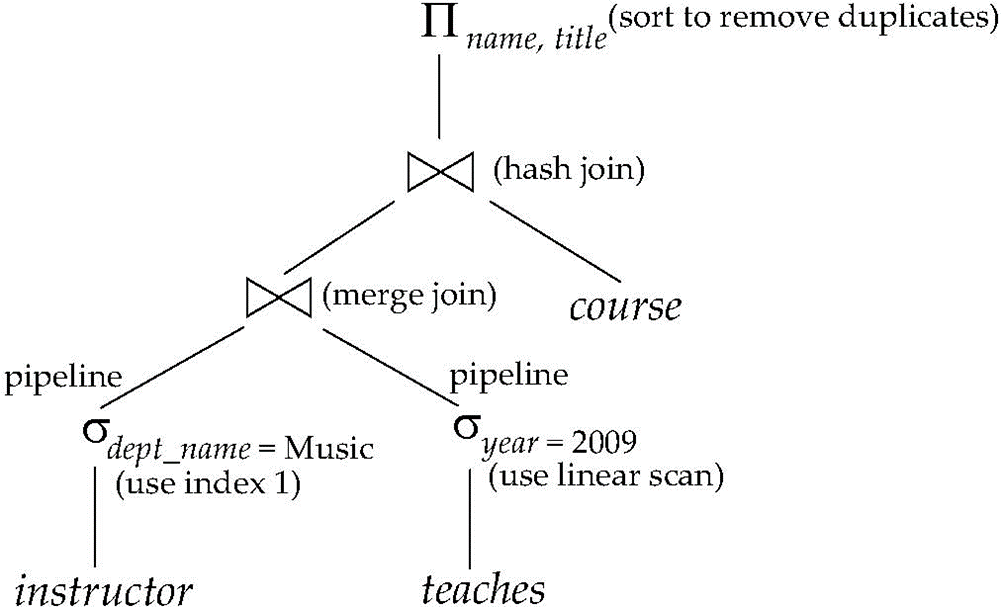
经过代价估算,决定使用哪个算法的代价最小。如上图左边使用了 B+ 树索引,右边使用了线性扫描。
自然连接的算法包括:Hash join,Merge join.....,merge join 要求连接属性本身有序
执行方式包括:顺序执行(顺序存储)和pipeline(流水线)
11.2 Measures of Query Cost¶
Typically disk access is the predominant cost, and is also relatively easy to estimate. 磁盘访问(I/O)是主要成本,并且也相对容易估计。
忽略 CPU cost.
Measured by taking into account
-
Number of seeks (把读写头定位到扇区)
-
Number of blocks read
-
Number of blocks written
通常write所需的时间大于read的时间,因为执行write操作后需要重新读取数据确保写入没有问题(多了验证环节)
For simplicity we just use the number of block transfers from disk and the number of seeks as the cost measures。block transfer就表示block的read和write操作
\(t_T\)– time to transfer one block \(t_S\)– time for one seek * Cost for b block transfers plus S seeks\(b * t_T + S * t_S\)
\(t_T\)和\(t_S\)之间关系:seek花费的时间更长。在磁盘中,\(t_S / t_T \approx 40\),在固态硬盘中,\(t_S / t_T \approx 10\)。因为seek寻道是机械运动,比传输花费的时间更多.
约定:
简单起见,我们忽略CPU的成本(课程查询代价的计算)。并且我们在成本公式中忽略将输出写入到磁盘的成本。
可能是流水线不需要写道磁盘,但是如果题目中明确提出将最终的结果写入到磁盘中,那么就需要考虑写入到磁盘的代价了衡量算法的代价,存在硬件条件的差异,假设内存足够大,可以把整个数据库都装到内存中,那么就只需要一次磁盘的seek操作,然后全部读进内存中就好。但在实际中,我们考虑的是最坏的情况,可用的缓冲区实际内存量取决于其他并发查询和操作系统进程,只有在执行过程中我们才知道有多少缓冲区的大小可以用。
因此最坏情况估计,按照操作最少需要的buffer数量进行计算。(例如,关系R和S的join,最少需要3个buffer,一个存放R的数据,一个存放S,剩下一个放结果)
并且,我们假设所有需要的数据都必须在磁盘中去读,并没有在内存(缓冲区)中命中。
11.3 Selection Operation¶
11.3.1 File scan¶
Algorithm A1 (linear search). Scan each file block and test all records to see whether they satisfy the selection condition. (假定数据块都是连续存放的)
- worst cost =\(b_r*t_T+t_S\)
\(b_r\)denotes number of blocks containing records from relation r
只需要进行一次seek,相应的有关的block都需要进行read
-
average cost =\(b_r/2*t_T+t_S\)
这里如果搜索的是 key attribute(每一个数值都唯一), 那我们扫到这个记录就可以停止。
11.3.2 Index scan¶
Index scan – search algorithms that use an index。selection condition must be on search-key of index.
A2 (primary B+-tree index / clustering B+-tree index, equality on key).
主B+树索引/聚类B+树索引,在主键上等值查找
cost =\((h_i+1)* (t_T+t_S)\)。
B+树的每一个结点就是一个block,并且每一个block在磁盘中是不连续分布的。因此对于B+树上的结点,都需要进行一次seek+transfer。
这里的高度从 1 开始(+1 表示最后到叶子节点,指针指向最终数据,需要从磁盘中读)
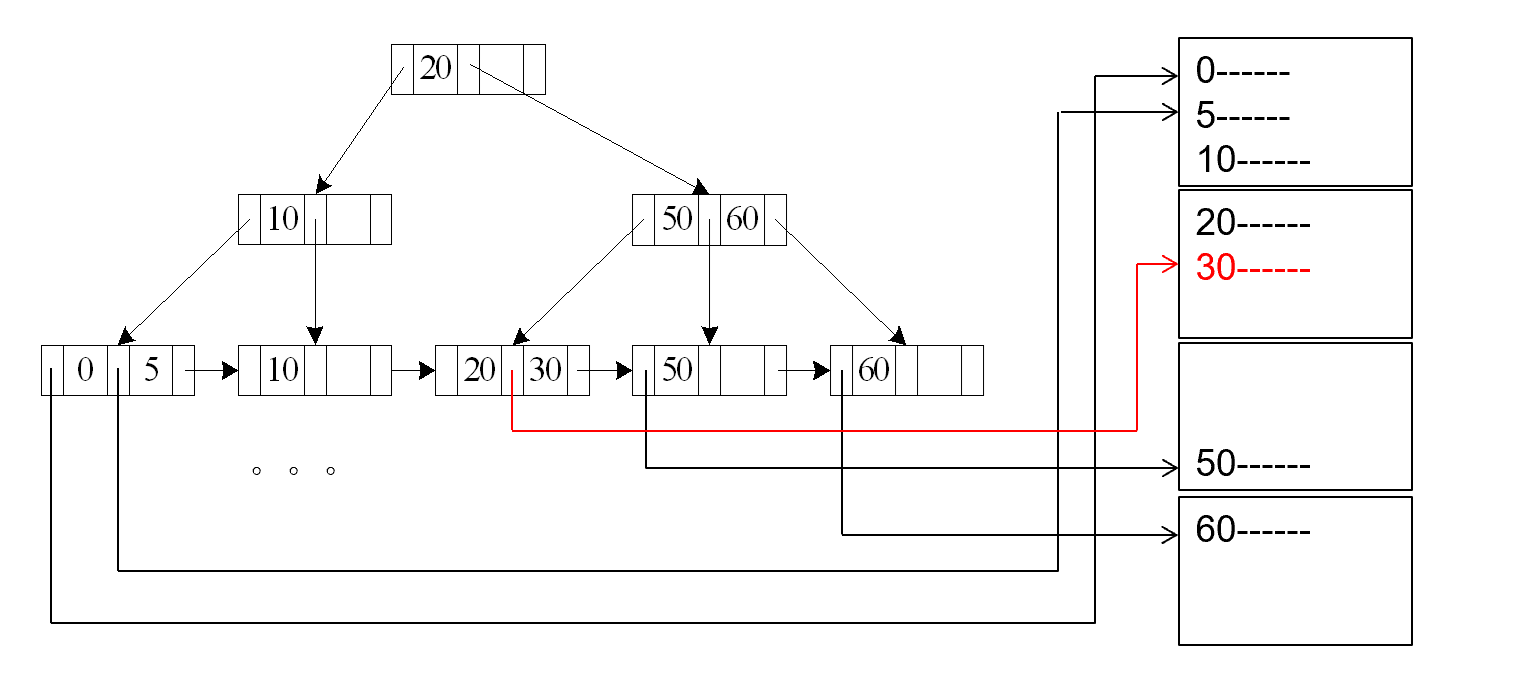
A3 (primary B+-tree index/ clustering B+-tree index, equality on nonkey).
此时索引的值不是主键. 可能存在多条record,在最后一次,从叶子结点出发找到最终结果的过程中,会引发传输的block数发生变化。
Records will be on consecutive blocks (此为seek数保持为1的前提)
b表示,匹配的记录所占块的个数。下方的例子中,文件中的块已经按照查询的条件排好序,连续存放,而匹配的记录一共四条,占用两个块,因此b = 2。
cost =\(h_i *(t_T+t_S) + t_S + t_T *b\)
Example "主索引, nonkey 上的等值查找"
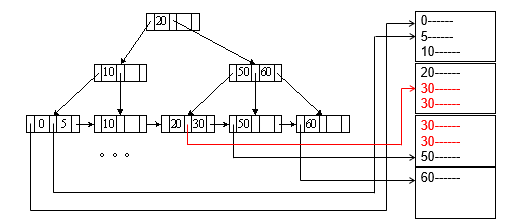
A4 (secondary B+-tree index , equality on key).
辅助索引和主索引相比,主索引要求文件的存储排序根据的属性和index建立根据的属性相同,辅助索引并无这个要求。用一个例子表示辅助索引B+数,equality on key,我们要查找的是key是学号,但是文件存储上,是按照dept_name进行排序的
但是,如果此时是Key上相等,而由于Key对应的记录是唯一的,因此,查找Key时,辅助索引与主索引是没有区别的。
cost =\((h_i + 1) * (t_T + t_S)\)
Example "辅助索引, key 上的等值查找"

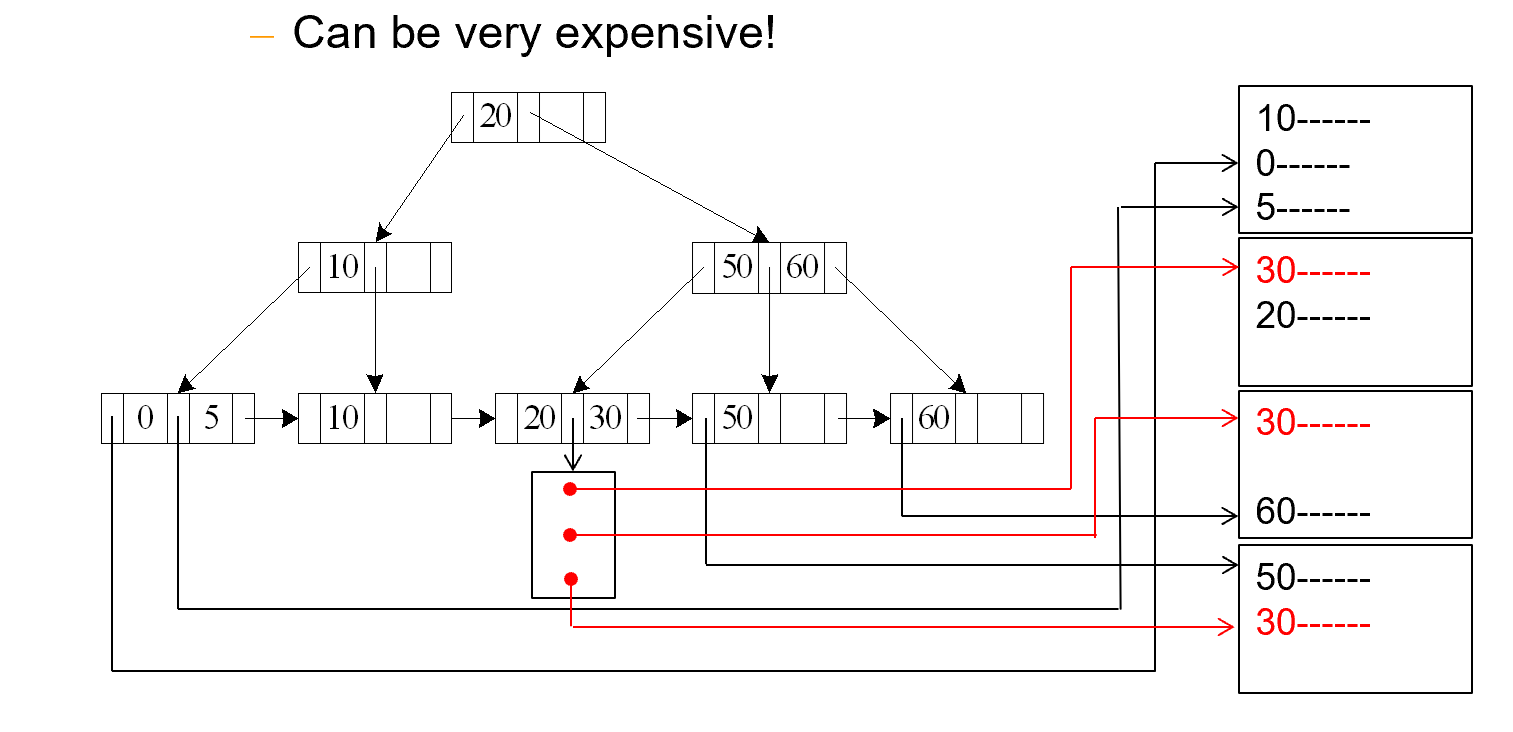
A4’ (secondary B+-index on nonkey, equality).
此时是辅助索引,并且搜索的还是非key,说明我们搜索的record在文件既不是排好序的,也不是唯一的。
Cost =\((h_i + m+ n) * (t_T + t_S)\)
这里 m 表示放指针的块的数量, n 表示对应磁盘里的记录所在的块的数量。
我们按照搜索条件,搜索到一些符合条件的、放着指针的block。假设放指向实际数据记录的指针的block有m个,并且实际的数据都分散在不同的block中,一共存在于n个块中。
\(h_i(t_T+t_S)\)不变,一直找到leaf。接下来搜索m个放置实际记录指针的数据块,对这m个block需要个进行一次seek和transfer(分散的block),知道指针后,对记录进行查找,所有的记录分散在n个block中,那么就需要\(n(t_T+t_S)\)
所以最终结果为Cost =\((h_i + m+ n) * (t_T + t_S)\)
Example "辅助索引, nonkey 上的等值查找"
11.3.4 Selections Involving Comparisons¶
涉及到比较的查询
查询\(\sigma_{A\leq V}(r)\)(or\(\sigma_{A\geq V}(r)\))
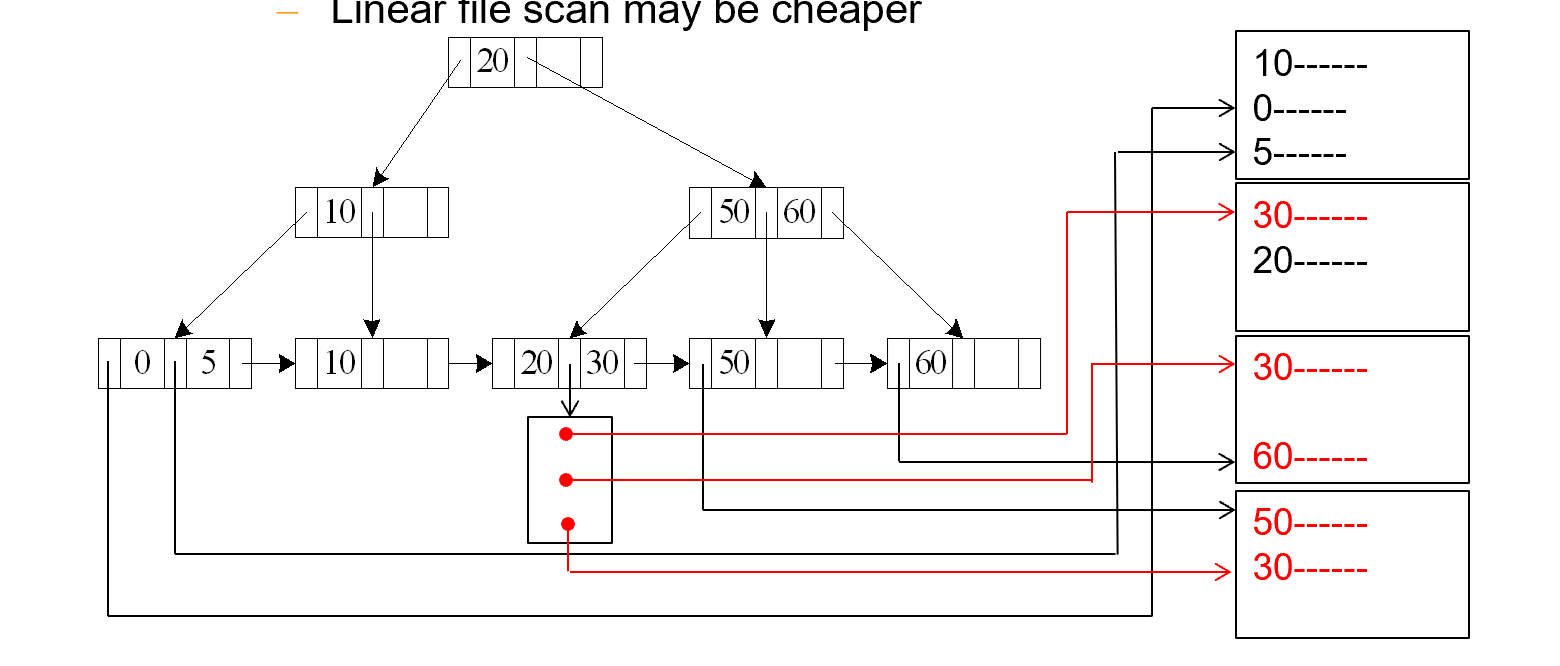
A5 (primary B+-index / clustering B+-index index, comparison). (Relation is sorted on A)
- 查找该属性大于等于A的记录,可以在B+树中找到大于等于A的第一个块,然后对剩下的进行连续的扫描。(因为这个属性在文件中是主索引,因此是记录是按照该属性排好序连续存放的)
需要进行树高次读写头重定位操作与块传输操作,与一次读写头重定位操作找到大于等于A的第一个块,然后b次块传输操作,进行连续的扫描。- Cost =\(h_i * (t_T + t_S) + t_S + t_T * b\)(同情况 3 primary b+ tree,nonkey)
对于查找该属性小于A的记录,不需要利用B+树索引,只需要对放置记录的文件,从头开始扫描,直到第一个该属性大于等于A的记录。
因为这是primary B+tree,搜索键指定文件的排列顺序,也就是文件是按照我们的search key排列好的,并且是连续存放,所以只需要一次seek+b次transfer
Example "主索引, key 上的比较"

A6 (secondary B+-tree index, comparison). 情况类似 A4(secondary B+ tree, nonkey)
- 查找第一个属性大于等于A的记录。使用索引找到第一个大于等于A的记录的叶结点,接下来一次的该叶结点右侧的叶结点进行扫描,这样就能得到所有的符合条件的、放着指针的block
- 然后类比A4,只需要知道放着指针的block的数量m,和符合条件的记录分在block的块数m即可
- Cost =\((h_i + m+ n) * (t_T + t_S)\)
查找该属性小于A的记录,直接从头开始扫描该属性的B+树的叶结点,直到第一个该属性大于等于A的地方,找到这之间的所有的指向记录的指针
这种范围查找。线性搜索花费的时间更少Example "辅助索引, nonkey 上的比较"
11.3.4 Implementation of Complex Selections(AND)¶
Conjunction\(\sigma_{\theta_1} \wedge \ldots \wedge_{\theta_n}(r)\)
可以线性扫描,或者利用某个属性的 index 先查询,把符合的读到内存中,再检查其他属性。 如果有很多个属性都有索引,我们选择中间结果少的。
A7 (conjunctive selection using one index).
-
Select a combination of\(\theta_i\)and algorithms A1 through A6 that results in the least cost for\(\sigma_{\theta_i}(r)\).
-
Test other conditions on tuple after fetching it into memory buffer.
把这个限制条件选择后的这些记录读取到内存(buffer)中去,然后在内存中去测试其他条件。
先对其中一个选择条件进行选择,要求能够过滤尽可能多的记录。
A8 (conjunctive selection using composite index).
Use appropriate composite (multiple-key) index if available.
优先使用已经建立好的复 合索引,最好的情况是,要选择的条件中刚好能够合成现有的一个复合索引
A9 (conjunctive selection by intersection of identifiers).
对每个索引都进行查询,将结果拼起来(取交集)
11.3.5 Algorithms for Complex Selections(OR)¶
-
Disjunction:\(\sigma_{\theta_1} \vee \ldots \vee_{\theta_n}(r)\)
A10 (disjunctive selection by union of identifiers).
- Applicable if all conditions have available indices.
- Otherwise use linear scan.
- Use corresponding index for each condition, and take union of all the obtained sets of record pointers.
- Then fetch records from file
-
请确保所有限制条件对应的属性,都有建立相应的索引,否则,要利用线性扫描来进行上述查询。
> 对每一个条件,都利用前面说到的A1到A6算法,找到相应符合的记录集合,然后再取并集。
-
Negation:\(\sigma_{\neg \theta}(r)\)
- Use linear scan on file
- If very few records satisfy\(\neg \theta\), and an index is applicable to\(\theta\) Find satisfying records using index and fetch from file
11.3.6 Bitmap Index Scan¶
相当于建立一个bitmap,bitmap with 1 bit per page in relation。
操作流程:index scan 找到符合条件的record id,将对应的id block对应的bit设置为1,之后就可以线性扫描获取bit被设置为1的block
好处是减少了B+树 从叶子到数据block的seek操作次数,因为seek本身就是机械运动需要花费更多的时间。
11.4 Sorting¶
For relations that fit in memory, techniques like quicksort can be used
For relations that don’t fit in memory, external sort-merge is a good choice.
对于适合内存的关系,可以使用快速排序等技术。
对于不适合内存的关系,利用外部排序。
假设初始的关系非常大,没办法全部放入内存:
Example: External Sorting Using Sort-Merge
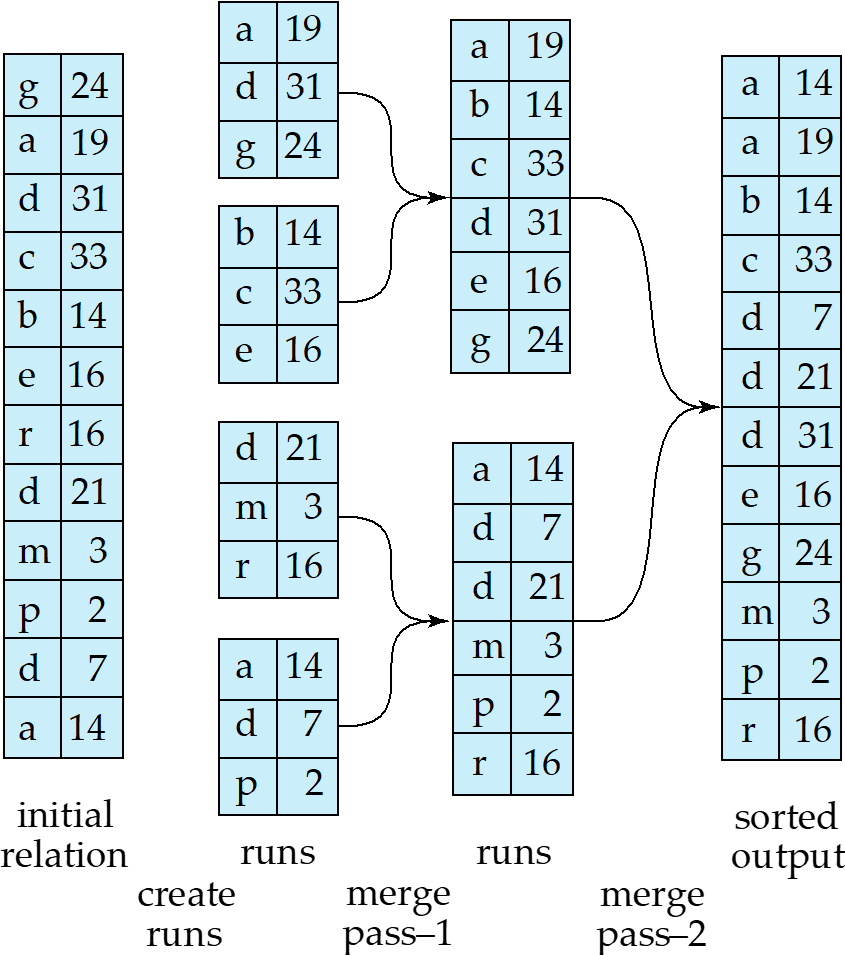
初始内存放不下,只能放\(M\)pages. 一次性读\(M\)块,在内存内排序,排好后先写回,形成一个归并段。再读入第二段到内存中,排序后再写回,得到若干归并段(\(\dfrac{b_r}{M}\)) 会有\(2*\dfrac{b_r}{M}\)次 seek,\(2*b_r\)次 transfer.
首先假设存储这个关系的文件一共有\(b_r\)个block,但是内存一次最多放入m块。因此我们要将\(b_r\)个块分成\(\lceil \dfrac{b_r}{m} \rceil\)个段,每一段都最多m块,然后一段一段地放进内存中进行排序。
在这一过程中,文件中每一个block都会进入到内存中一次。接下来,在内存中完成内部排序后,每一个block又会写出来一次。因此block transfer的次数为\(2 * b_r\)接下来是磁盘读写头的重定向操作。
将所有的block分成$\lceil \dfrac{b_r}{m} \rceil$后,需要读入到内存中,此时每一段需要一次磁盘读写头重定向操作。因为每次把一段放入内存中排好序后,需要重新定位到下一个段。对于每一段,在内存中排好序之后需要写出来,所以seek的总次数为\(2\lceil \dfrac{b_r}{m} \rceil\)
11.4.1 Procedure¶
Let\(M\)denote memory size (in pages).
-
Create sorted runs(归并段)
Repeatedly do the following till the end of the relation:
- Read M blocks of relation into memory
- Sort the in-memory blocks
- Write sorted data to run\(R_i\); increment i.
- 假设生成了\(N\)个归并段
-
Merge the runs
- 归并段的数量严格小于内存最大容量的块数,N < M
假设生成的小的归并段的数量是N,内存中最大块的数量是M,假设\(N <= M-1\),那么只需要单次合并,就可以解决。
此时在内存中使用N个块作为输入缓冲区,使用一个块作为输出缓冲块。
最初,将每一个归并段的第一个块(即属性值最小的块)放入内存中(一共N个,\(\(N = \lceil \dfrac{b_r}{m} \rceil\)\)),在内存中保留一个块作为输出缓冲块。然后进行归并,把归并的结果写到输出缓冲块中。一旦某一条记录被归并掉,那么这条记录就会从它所属的内存的那个输入缓冲块中删除。如果内存中某个输入缓冲块的内容被删除空了,那么就将对应的归并段的下一个块拿上来。
对于输出缓冲块,每当它被写满了,就将其写出来,写到磁盘中。

例如:上图中,生成了两个归并段,其中每一个段都有4块。这说明内存中最多存放4个block,这个关系一共有8个block
由于\(2 < 4(N < M)\),所以一次归并就可以解决问题。首先将两个归并段的第一个块放入到内存中(输入缓冲块buffer),(1,3,5)(2,4,6)。现在输出缓冲块中先写入1,对应的删除(1,3,5)的1。直到输出缓冲块写满,当下一个元素4写入时,需要先把输出缓冲块中的内容写道磁盘中。接着,输出缓冲块要写入5,此时有一个输入缓冲块变空了。这个输入缓冲块的内容就要被(7,9,11)来代替。
2.归并段的数量大于等于内存最大容量的块数
需要多轮次的合并。在每一个轮次中,M-1个归并段被归并起来。
例如,假设M为11,原本有90个归并段。那么每次放入10个归并段,合为1个。最后会产生9个较大的归并段。将这9个较大的归并段放入内存中,再进行一次归并,就会最终得到一个归并结果。(为什么能够将较大的归并段放入内存中呢?本质上还是可以理解为,每一次都是将归并段的第一个block写入到输入缓冲快中,后面的block不会占内存能容纳的块数,不产生影响)
11.4.2 Cost analysis¶
transfer cost

-
最初始时,生成的最小归并段的数目为:\(\lceil \dfrac{b_r}{m} \rceil\)
-
由于每一轮次(将小的归并段,通过归并合并为较大的归并段,例如,刚刚90个小归并段,和并为9个大的归并段,这个过程叫做一轮),归并段的数量减少为原来的\(\dfrac{1}{m-1}\),所以轮数表示为\(log_{m-1}(\dfrac{b_r}{m})\)
-
在生成初始归并段的时候,就需要2br次的传输和2*br/m次的seek。然后最后一轮我们忽略将生成的归并结果写入到磁盘的开销。(因为可能流水线会直接把结果交给下一步操作)$$ total number = 2 b_r + \lceil log_{m-1}\dfrac{b_r}{m}\rceil \times 2b_r - b_r = b_r + 2b_r\lceil log_{m-1}(b_r/m)\rceil $$
seek cost

-
生成归并段的阶段(将归并段内部排好序):需要一次seek读取每一个归并段,由于归并段是由连续的block组成,只需要进行一次seek,后续顺序查找即可,全部读入到输入缓冲快中,排好序后,写回时需要一次seek,后续顺序填补即可
对于一个归并段需要两次seek,那么总数为\(2\lceil b_r/m \rceil\),
2 * the number of runs -
merger阶段:在对初始的归并段进行归并操作的每一轮,每一个块的读写,都需要一个单独的读写头重定位seek,
这是因为读写操作是不知道顺序,你根本不知道哪个块的记录会被率先删除完,输出缓冲块写回磁盘的时候也需要重定向一次,因为可以原本的读写头还在输入的归并段那里。所以每一轮seek操作的次数是\(2b_r\)需要注意的是,最后一轮生成的归并结果不写回到磁盘中,所以少了br次seek操作 $$ \begin{aligned} total number &= 2\lceil b_r/m \rceil + \lceil log_{m-1}\dfrac{b_r}{m}\rceil \times 2b_r - b_r \ &= 2\lceil b_r/m \rceil + b_r(2\lceil log_{m-1}(b_r/m)\rceil - 1 ) \end{aligned} $$
11.4.3 Advanced version¶
每一次读进去都要 seek, 可以改进。为每一个归并段分配多个输入缓冲块。这样我们定位一次之后可以读入多块进入输入缓冲区。
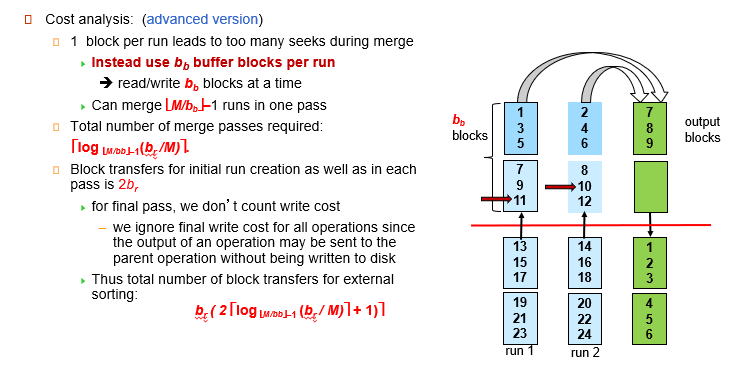
假设我们为每一个归并段,分配\(b_b\)个输入缓冲块。这样一次seek的操作,就能读写进入\(b_b\)块数据,但是这样会导致轮数的增加。因为,输入缓冲块的数量是有限的,这意味着为一个归并段分配更多的输入缓冲块会导致每一轮能够处理的归并段的数量发生减少。
此时,每一轮能够处理的归并段数量变为\(M/b_b - 1\)(请注意此时的输出缓冲块也是bb块,m/bb就表示最多能够容纳的归并段的数量,-1是为了输出缓冲块)。总的轮次变为:
$$
total number of merge pass = \lceil log_{\lfloor{m}/{b_b}\rfloor -1}(b_r / m)\rceil
$$
block transfer
但是传输操作是没有改变的,每一轮都要进行一次所有块的读入,都要进行一次所有块的写出。因此每一轮的传输操作次数依旧是2*br。
总的block transfer的次数变为: $$ 2b_r+2b_r \times \lceil log_{\lfloor{m}/{b_b}\rfloor -1}(b_r / m)\rceil - b_r = b_r(2\lceil log_{\lfloor{m}/{b_b}\rfloor -1}(b_r / m)\rceil + 1) $$
block seek

-
生成归并段的阶段(将归并段内部排好序):需要一次seek读取每一个归并段,由于归并段是由连续的block组成,只需要进行一次seek,后续顺序查找即可,全部读入到输入缓冲快中,排好序后,写回时需要一次seek,后续顺序填补即可。
保持不变,次数仍为 2*br/m -
归并阶段:由于一次读写头的重定向将读取\(b_b\)个block,所以seek的次数将为减少,转化为\(2\lceil b_r/b_b \rceil\).那么总的block seek的次数变为 $$ 2\lceil b_r/m \rceil + [b_r/b_b]\lceil (2log_{\lfloor{m}/{b_b}\rfloor -1}(b_r / m)\rceil - 1) $$
\(b_b\) 的增加,虽然会减少每一轮运行时的读写头重定位次数,从br次到br/bb次,但是会增加轮数,因此还会增加数据传输的次数。
本质是同block transfer时间较短的操作选项弥补时间较长的block seek
11.5 Join Operation¶
Several different algorithms to implement joins
- Nested-loop join
- Block nested-loop join
- Indexed nested-loop join
- Merge-join
- Hash-join
11.5.1 Nested-Loop Join 嵌套循环¶

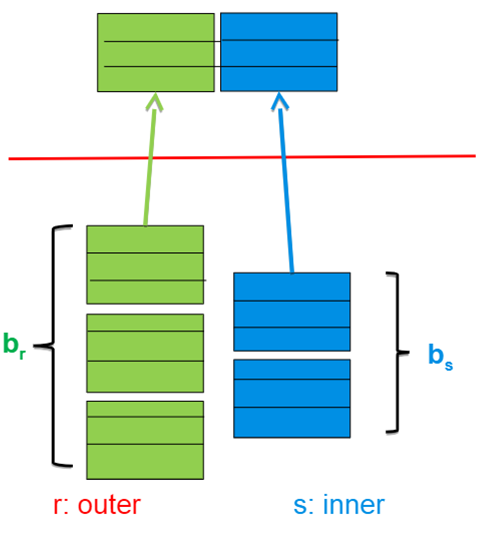
\(r\)is called the outer relation外循环,对应的块数是\(b_r\),and\(s\)the inner relation* of the join.内循环,对应的块数是\(b_s\)
block transfer
这个算法要求把外循环关系的每一条记录和内循环关系s的每一条记录组合起来检查是否满足关系。因此外循环关系的每一块,都只需要进入到内存一次。但是对于外循环关系中的每一条记录,内循环关系的每一块都要进入内存一次。所以传输的次数为: $$ n_r * b_s + b_r\ n_r 表示外循环关系r记录(record)的数目 $$
block seek
-
外循环中,每一块都需要进入到内存中,因此磁盘读写头重定向的次数为\(b_r\)
-
对于内循环,需要去遍历内循环的每一条record,但是内循环的文件s是连续存储的,因此每次进入内循环,只需要读写头重定位一次。
退出内循环后,回到外循环,只需要外循环当前在输入缓冲块的record下移,读写头重新定位到内循环的第一个block。因此,外循环进行多少次,内循环关系的读写头就重定位多少次。 - 上述算法中,外循环每一个元组都要和内循环关系的整个关系进行匹配,因此外循环关系有多少个元组\(n_r\),外循环就要进行多少次,内循环关系的读写头就要重定位多少次。
如果内存能够容纳所有的关系,那么只需要进行2次seek(关系r和关系s),b_r + b_s次transfer。因为这时关系r中所有的块一次性读入到内存中,不需要在跳出内循环进入外循环发现当前输入缓冲块没有record后,重新读写头重定向读取外循环的下一个block。同时由于关系s的所有块都读入内存,所以对外循环每一条record,不需要重新读取内循环所有的block,直接从内存中拿即可
11.5.2 Block Nested-Loop Join¶
块嵌套循环连接

对于外循环的每一个块,将内循环关系的每一个块读入内存中。然后在内存中针对这两个块进行充分的连接。
最坏的情况下,传输需要发生的次数:block transfer
$$ b_r * b_s + b_r $$ 这是因为,外循环关系的每一个块肯定要进入内存一次。对于外循环关系的每一个块,内循环关系的每一个快都要进入到内存一次,需要\(b_r * b_s\)次传输
最坏的情况下,传输需要发生的次数:block seek
对于内循环,一次定位即可将内循环关系的文件顺序地读到内存中去。因此,外循环进行几次,对于内循环关系就会发生多少次读写头重定位操作。
但是每次退出内循环,回到外循环时,都需要对读写头重新定位,以使得外循环关系的文件的下一块进入到内存中。
因此,外循环有多少个块,对于外循环关系文件的读写头重新定位就会发生多少次,对于内循环关系文件的读写头重新定位就会发生多少次。
Seek操作发生的总次数为:\(2 \times b_r\)
从transfer和seek的次数来看,要使总的cost最低,那要使$b_r$尽可能地小,所以我们选择块数少地关系作为外关系,同时减少seek和transfer的次数最好的情况是:假设内存空间足够大,那么两个关系所有的块都能够一次性读入到内存中去。此时block transfer的次数为:\(b_r + b_s\), block seek 的次数为2次
Improvements to block nested loop algorithms:
我们每次退出内循环,回到外循环时,都要进行一次读写头重定位操作。为何不让这次读写头重定位操作一次读取多个块?
现在,假设内存中最大容量是M个块。留一个块作为输出缓冲区,只需要留一个输入缓冲块留给内循环关系(因为不管留几个块给内循环,内循环都是只需要重定位一次,就可以全部读进来),剩下\(M-2\)个块全部留给外循环,作为输入缓冲区。
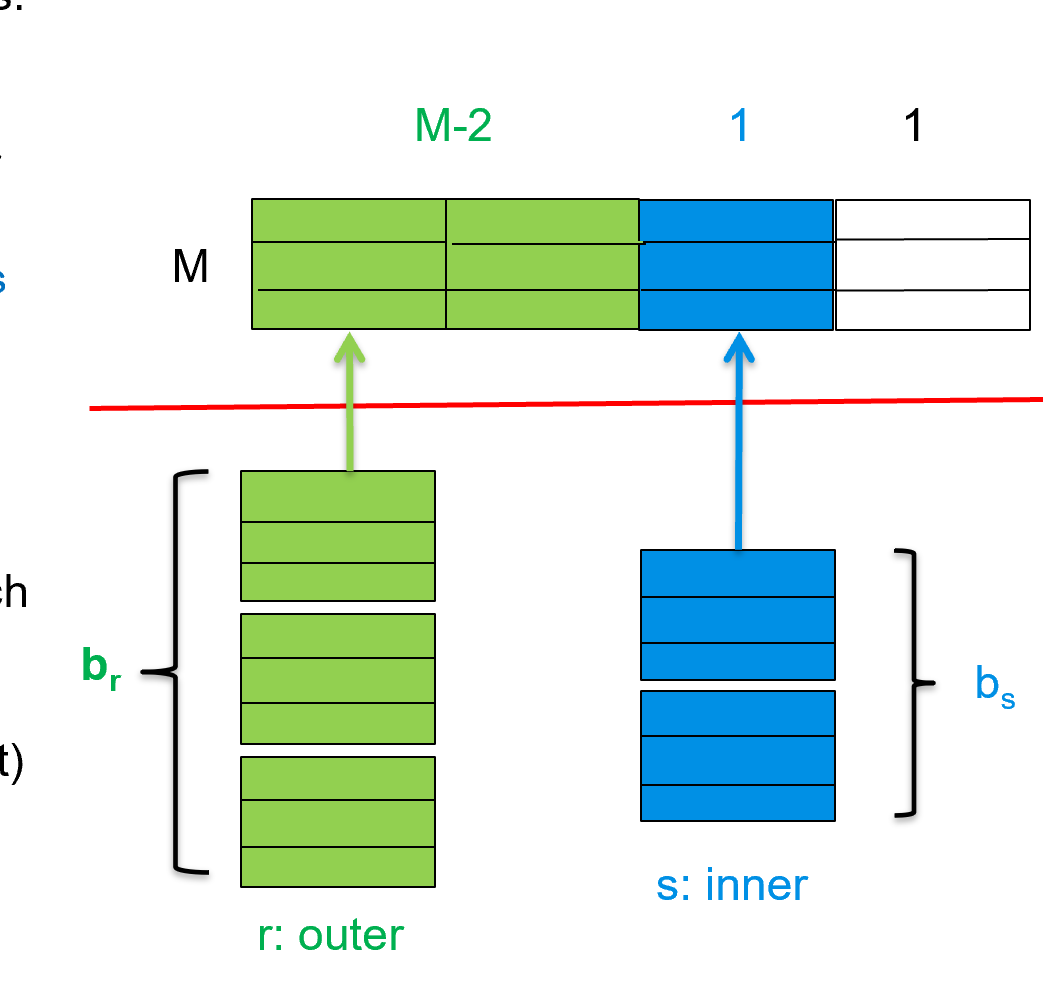
block transfer
外循环的每一个块还是必须要读入内存中一次。这消耗br次Transfer。
每一轮循环,外循环关系读进内存的有m-2个块,因此循环次数变成了原来的M-2分之一。现在循环次数变为:\(\lceil b_r / (m-2) \rceil\)
对于每一轮循环,都需要将内循环关系的所有块全部读进来 $$ total number of transfer: b_r + b_s \times \lceil b_r / (m-2) \rceil $$
block seek
每一轮循环时,要进行一次外循环关系的读写头重定位。
对于内循环,在每次执行内循环的时候,要进行一次内循环关系的读写头重定位。 $$ total number of seek = 2\lceil b_r / (m-2) \rceil $$ Cost =\(\lceil b_r / (M-2) \rceil * b_s + b_r\)block transfers +\(2 \lceil b_r / (M-2)\rceil\)seeks
-
If equi-join attribute forms a key on the inner relation, stop inner loop on first match
如果连接的属性是 key, 那么当我们匹配上之后就可以停止内循环。
-
Scan inner loop forward and backward alternately, to make use of the blocks remaining in buffer (with LRU replacement)
利用 LRU 策略的特点,inner 正向扫描后再反过来,这样最近的块很可能还在内存中,提高缓冲命中率。
11.5.3 Indexed Nested-Loop Join¶
需要连接的属性上,内循环关系针对该属性有一个B+树索引。那么,就没必要每次去遍历内循环的每一个元组。我们只要根据外循环该条记录对应的属性值,在内循环的B+树索引中查找即可。
Index lookups can replace file scans if
-
join is an equi-join or natural join and
适用于自然连接和等值连接,相当于我已知一个属性的值,然后在B+树中寻找相等的值 -
an index is available on the inner relation’s join attribute
连接属性有索引
假设外关系在内存中分配一个输入缓冲区
block transfer- 对于外关系,每一个块都会传输进入内存中,因此需要这需要\(b_r\)次Transfer操作。
- 对于内关系,不用将它读入内存中,直接利用B+树查找即可。内关系不需要传输操作。
block seek- 对于外关系,每一次退出内循环,接着外循环进行时,都要进行一次读写头重定位。因此,需要\(b_r\)次Seek操作。
假设外关系在内存中分配M-2个输入缓冲块
-
block transfer- 对于外关系,每一个块都会传输进入内存中,因此需要\(b_r\)次Transfer操作。
-
block seek- 对于外关系,每一次退出内循环,接着外循环进行时,都要进行一次读写头重定位,因此,读写头重定位的次数与循环的轮数相等。
因此需要\(\lceil br/M-2 \rceil\)次Seek操作。
这里假定给外关系一块内存.\(c\)表示遍历索引并取出所有匹配的元组的时间。
Cost of the join:\(b_r (t_T + t_S) + n_r * c\)
因此选择具有较少record的关系作为外循环

比较后发现,外关系record数量较小的话,适用于indexed nested loops
11.5.4 Merge Join¶
假设两个关系已经基于连接属性排好序,我们可以用归并的思想连接。同样适用于等值连接
-
Sort both relations on their join attribute (if not already sorted on the join attributes).
-
Merge the sorted relations to join them
-
Join step is similar to the merge stage of the sort-merge algorithm.
-
Main difference is handling of duplicate values in join attribute — every pair with same value on join attribute must be matched
主要区别是连接属性中重复值的处理 - 连接属性上具有相同值的每一对都必须匹配(
pair的数量是 m * n) -
假设每一个关系,在内存中只分配一个输入缓冲块
-
block transfer由于两个关系的每一个块一定会进入内存一次,因此,代价为\(b_r+b_s\)。
-
block seekMerge操作中,
两个关系中的块进入内存的顺序是不固定的,因此,最坏情况每一个块进去内存都要进行读写头重定位。因此代价为\(b_r+b_s\)。
假设每一个关系,在内存中分配\(b_b\)个输入缓冲区
\(b_r + b_s\)block transfers +\(\lceil b_r / b_b\rceil + \lceil b_s / b_b\rceil\)seeks
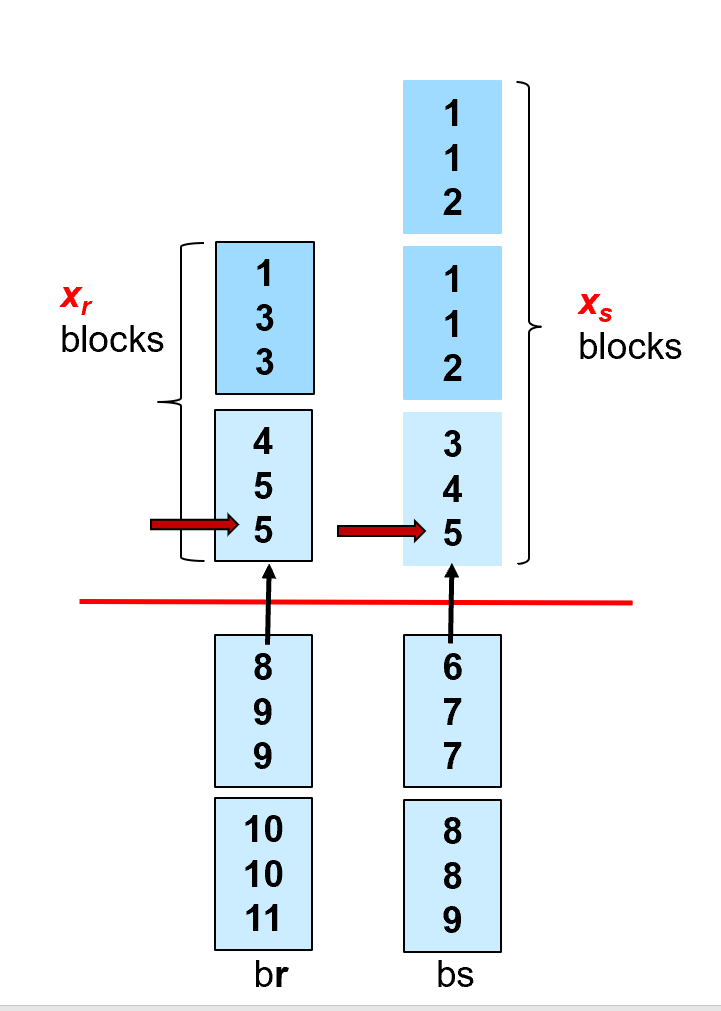
If the buffer memory size is M pages, in order to minimize the cost of merge join, how to assign M blocks to r and s respectively?
假设内存上限为M块,怎么分配输入缓冲区的块数(s关系分配k块,r关系分配M-k块),从而使得Seek的代价最少?
The estimated cost is\(b_r + b_s\)block transfers +\(\lceil b_r / x_r\rceil + \lceil b_s / x_s\rceil\)seeks (\(x_r+x_s=M\))

如果两个表都无序,我们可以先排序再 Merge-join, 这时还要算上排序的代价。

第一步将关系r和关系s的叶结点进行merge,这是得到的是pair是关系r的属性值,和指向关系s的指针集合。block和seek的次数都是br+bs
第二步是将指向关系s指定值的指针按照地址排好序。目的是相邻地址的指针可能在同一个block中,这样就能够减少seek的次数。如果指针都已经在内存内了,那么只需看关系r的block块数,br次的seek和transfer
第三步将地址里面的数据取出来,和原先关系r的属性值进行merge
11.5.5 Hash Join¶
hash join适用于自然连接和等值连接(追求相等,这么hash值也会相等)
通过计算一个哈希函数,对关系r的连接属性与关系s连接属性,通过计算哈希值进行分片。
把大的关系分成一片一片的小关系。
我们要求其中某个的小关系要能一次放到内存中。

原理是:能够连接上的两条记录(等值连接),利用对应的连接属性(在两个关系中值相等)算出来的哈希值是相同的。注意一下hash值相同的,可能能够连接;hash值不同的,一定不能够连接。
因此,将关系s分片中的分片0,与将关系r分片中的分片0,其中包含了所有哈希值为0的,能互相进行等值连接的记录。
我们只需要对关系s算出的分片0与关系r算出的分片0进行连接、对关系s算出的分片1与关系r算出的分片1进行连接、对关系s算出的分片2与关系r算出的分片2进行连接……最后再进行组合就可以了。而不需要考虑关系s算出的分片0与关系r算出的分片1进行连接等,因为哈希函数是相同的,假设s中某一个记录该属性的值被映射到片0,r中某一个记录该属性的值被映射到片1,那么s中的这一个记录和r中的这一个记录在连接属性上一定不相等,因此,s的片i与r的片j(i!=j)一定不需要考虑。
同时,需要保证的是,其中一个关系(例如关系s)的分片大小,能够放入到内存中去。
将关系s的每一个分片,直接一次性的读到内存中去,(例如此时读入片0),然后再对关系r中的片0,对于每一个块,或者每一个记录,与s关系的片0在内存中直接进行匹配连接。
这样一来,每一个分片,例如r的分片0与s的分片0,都只需要传输进入内存一次。对r的片0的每一个块进行循环读入,将每一个块和已经全部在内存中的s的片0进行匹配,
循环读入片0的块,不需要反复读入关系s的片0,减少seek和transfer的次数。因此,s的分片0不需要在每次r的片0的每一个块读进去的时候,重新循环读入一次,而是一直存在于内存中,等待r的一块一块读进来进行匹配。
此外,在后面进行分片的join操作时,这是在内存中进行的。对于关系r的分片i的每一个块,去跟已经在内存中的关系s的分片i进行连接。这个过程可以利用内存中关系s的分片i的哈希索引进行。
可以在内存中建立起比较有效的哈希索引。在对关系r的分片i的每一条记录的连接属性值,在关系s的分片i中进行查找进行等值连接的时候,通过这个哈希索引函数计算一下,就能在关系s的分片i查找到符合等值连接的记录。
hash函数应该如何设计呢?应当将关系r和关系s至少分成多少片?
因为我们需要保证,关系s的每一个分片都能装入到内存中去。也就是说每一个分片的block数量要小于每一个buffer所能容纳的block数量
还有问题:假如表S很大,M相对来说很小。此时利用hash函数,将关系s进行分片,分的片数就需要很多。那么假如内存不够大,一次无法分配出来这么多的分片,应当如何处理?
-
首先理解,为什么内存不够大,就无法一次分配这么多的分片?
这是因为假如我们把关系s分为N个分片,那么每一个分片在内存中都要具有一个block大小的输入缓冲区。第i个缓冲区的作用就是接受hash值为i的record。当第i个输入缓冲区写满了,就要写出去。因此N>M,内存中块的数量不够N,无法将关系s分为N个分片 -
解决方法:多次分片。假设第一次分片,我们把关系r和关系s分为了4个分片,但这些分片大小还太大,放不进去内存中。此时需要再次进行细分,递归地分割。
【definition】
- 能够被分片,分片一次性放入到内存中的那个关系(如上述例子中的关系s),叫做build input(建立输入)。
- 对于上述例子中的关系r,叫做probe input(探针输入)。

- 对于关系r,使用一个哈希函数h,进行分片。对于每一个分片,内存中都需要一个输入缓冲块。
- 对于关系s,使用相同哈希函数h,进行分片。对于每一个分片,内存中都需要一个输入缓冲块。
这也就说明为什么有的分片无法执行(内存太小) - 对每一个hash值i
- 将\(si\)加载到内存中去,然后针对\(si\)的等值连接属性,构建一个内存
哈希索引。这个内存哈希索引,使用与刚刚分片时不同的哈希函数h’。 - 从磁盘中一次读入\(r_i\)的每一个元组\(t_j\)(
本质上是将ri的每一个block都读入要内存中,对block内的record进行操作),在内存中与\(s_i\)进行匹配连接。对于元组tj,利用刚刚在分片si中构建好的hash索引,在si中匹配对应的属性上的等值元组tk,将tj和tk进行来连接得到结果
- 将\(si\)加载到内存中去,然后针对\(si\)的等值连接属性,构建一个内存
但是实际上,利用hash函数进行分片,其分出来的片不一定是均匀的。为了保证build input的每一个分片都能够放入到内存中。需要添加一个修正因子f,让分片的数量n大于标准值
\(n \geq \lceil b_s / m \rceil * f\)
11.5.5.1 Recursive partitioning¶
Recursive partitioning required if number of partitions n is greater than number of pages M of memory.
递归的分割用于:内存大小不够大,需要分割出来的最小片数n,大于了内存的最大块数M,因此需要分割出来的片数n不能每一片都在内存中有一个输入缓冲区
-
不需要分割的情况:
要让关系S的每一分片都能放进内存所需的最小n,小于内存中最大存放的块的数量M,即每一个片都可以在内存中获得输入缓冲区 $$ \begin{aligned} &M > n+1\ \Rightarrow &n \geq \lceil b_s/M \rceil \ \Rightarrow & M > (b_s / M) + 1\ \Rightarrow & M > \sqrt{b_s} \end{aligned} $$
A relation does not need recursive partitioning if\(M > n_h + 1\), or equivalently\(M > (b_s/M) + 1\), which simplifies (approximately) to\(M > \sqrt{b_s}\).

-
已知信息:内存为12M,一个block有4K byte。那么内存中的最大容量是3K 个block
-
如果有一个关系,希望不用递归的分割,求这个关系最大有多少block
利用数学关系式,可以得到\(M > \sqrt{b_r}\)
所以\(b_r < M^2\),因此这个关系最多具有3K\(\times\)3K个block,对应的byte数量就是3K\(\times\)3K\(\times\)4K
11.5.5.2 Cost of Hash-Join¶

如果没有使用递归的分割
-
block transfer
-
利用hash函数分割时,关系r和关系s的每一个块都要读入到内存的输入缓冲块一次,然后再写出来。这样就消耗了\(2(b_s+b_r)\)次的block transfer
-
接下来进入连接环节。对于关系 r 的每一个分片 i ,我们将 build input的si 读入到内存中,后续将 ri 中的每一个block一次读到内存中,与 si 进行连接
这样就消耗了\(b_r+b_s\)次block transfer
-
由于部分填充块的存在,hash分割占用的块数可能略多于\(br +bs\)。 访问此类部分填充的块最多可为每个关系增加\(2nh\)的开销,因为每个\(nh\)分区都可能具有必须写入和读回的部分填充的块。
-
总的transfer的数量为:\(3(b_r+b_s) + 4n_h\)
-
-
block seek
-
假设我们对关系r与关系s的每一个分片,在内存中分有\(b_b\)块输入缓冲区
-
在进行hash分片时,我们一次读写头重定位,就能读入内存\(b_b\)块。相当于一次读入\(b_b\)块后,在内存中将这\(b_b\)块的所有记录进行映射,放到输出缓冲区中输出。
读写头重定位的成本是:\(2(b_r/b_b + b_s/b_b)\)
-
在连接的过程中,需要将\(n_h\)个分区都进行重定向,所以需要\(2n_h\)
-
总的seek数量为:\(2(b_r/b_b + b_s/b_b) + 2n_h\)
-
2. 如果使用了递归的分割

-
假设每次分片,对于每一个关系(r或者s)的每一个分片,内存中都分配bb块作为输入缓冲区,同时内存中还留有一个bb块大小的输出缓冲区。
那么一次分片就能得到\(\lfloor M/b_b \rfloor - 1\)个分片于是我们能够计算出分片的轮数:\(\lceil log_{\lfloor M/b_b \rfloor - 1}(b_s/M) \rceil\)
每一次分片,都让分片的大小变为之前的\(1/\lfloor M/b_b \rfloor - 1\)
-
block transfer
- 每一轮分片,都需要将r关系的所有块读到内存中一次,再从输出缓冲块中输出来一次;s关系也一样。因此,对于有递归的分割的过程,数据传输的总次数为:\(2(b_r+b_s)\lceil log_{\lfloor M/b_b \rfloor - 1}(b_s/M) \rceil\)
- 后续的连接操作,对于每一个分片i,我们将build input的si读入到内存中。对于这个si,我们将ri中一块一块读到内存来。这样最终的结果是,关系r与关系s的每一块都读到了内存中一次。
总的传输次数为:\(2(b_r+b_s)\lceil log_{\lfloor M/b_b \rfloor - 1}(b_s/M) \rceil + (b_r + b_s)\)
-
block seek
-
对于r关系读到内存中的过程,由于对于每一个分片,输入缓冲区一共有bb块,因此一次读写头重定位就可以读进去bb块。并且对于每一个分片,由于输出缓冲区也有bb块,因此一次读写头重定位就可以输出bb块。
因此,每一轮对s与r的分片,其读写头重定位的总次数为:\(2(\lceil b_r/b_b \rceil + \lceil b_s/b_b \rceil)\)
-
再乘以分片的轮数,得到Seek操作的总次数:\(2(\lceil b_r/b_b \rceil + \lceil b_s/b_b \rceil)\lceil log_{\lfloor M/b_b \rfloor - 1}(b_s/M) \rceil\)
-
11.6 Other Operations¶
- Duplicate elimination can be implemented via hashing or sorting.
On sorting duplicates will come adjacent to each other, and all but one set of duplicates can be deleted.
在排序的过程(生成、合并归并段就进行去重) Hashing is similar - Aggregation
Sorting or hashing can be used to bring tuples in the same group together, and then the aggregate functions can be applied on each group.
生成归并段的时候,同一段的就可以统计统一结果
11.7 Evaluation of Expressions¶