13. Transactions¶
约 5538 个字 8 行代码 预计阅读时间 28 分钟
Abstract
- A Simple Transaction Model
- Concurrent Executions
- Serializability
- Recoverability
- Transaction Isolation Levels
- Transaction Definition in SQL
13.1 Transaction Concept¶
A transaction is a unit of program execution that accesses and possibly updates various data items. 事务是程序执行的单元,用于访问并可能更新各种数据项。(原子性的操作)
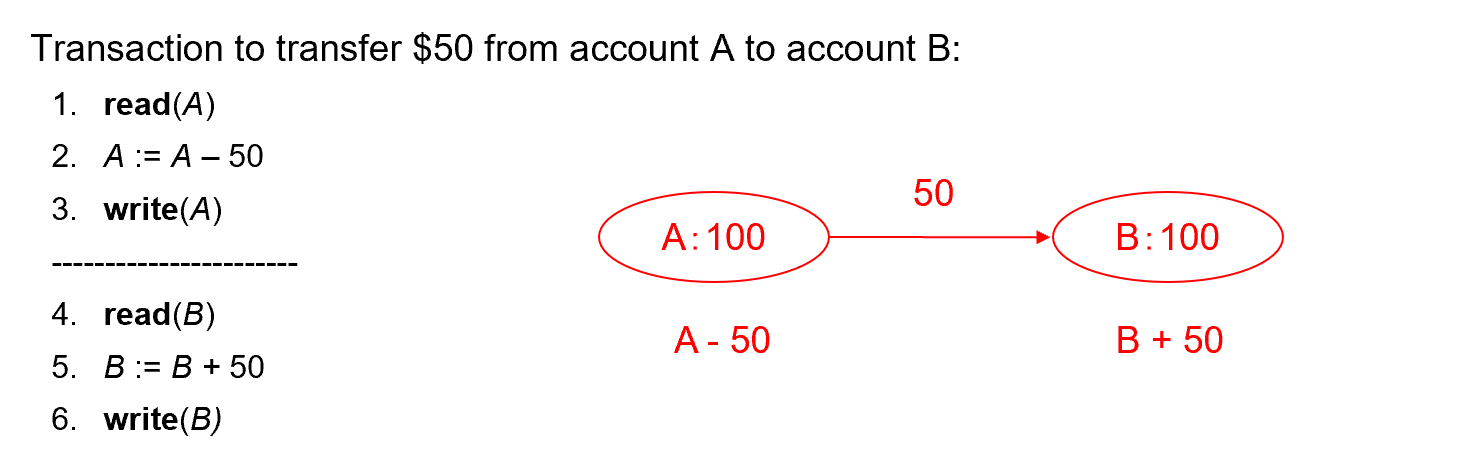
e.g. transaction to transfer $50 from account A to account B
update account
set balance=balance-50
where account_number=A;
update account
set balance=balance+50
where account_number=B;
commit;
-
Failures of various kinds, such as hardware failures and system crashes
各种故障,如硬件故障和系统崩溃
-
Concurrent execution of multiple transactions
并发执行多个事务
ACID Properties
-
Atomicity(原子性):要么事务的所有操作都正确反映在数据库中,要么没有(全有或者全无)
由数据库恢复功能保证
-
Consistency(一致性)
保证数据库内的内容正确性,与实际业务相符。如转账是一个人余额减少一个人增加。
在隔离状态下执行事务,可以保证数据库的信息一致性。保证数据库内容的正确性。
-
Isolation(隔离性)
尽管有多个事务同时执行,但每个事务必须不知道其他同时执行的任务。必须对其他并发执行的事务隐藏中间的事务结果。即一个事务不会被另一个事务所影响。
满足隔离性,最理想的情况就是一个事务执行完毕后再执行下一个事务。但是出于性能上的考虑,往往实际上是多个事务并发执行。这就要求事务执行的过程中,不受并行执行的事务影响。例如,不能读取到另一个还没有commit的事务写入的值。
-
Durability(持久性)
事务提交后被缓存,掉电不能失去 buffer 里的内容。
事务成功完成后,即使系统出现故障,事务对数据库的影响也应当永久存在。
13.2 A Simple Transaction Model¶
这个模型中,把事务对数据库的修改简化为读写(不考虑insert和delete)两种操作。
Transactions access data using two operations:(事务通过两种操作访问数据)
-
read(X), which transfers the data item X from the database to a variable, also called X, in a
work areain main memory belonging to the transaction that executed the read operation.它将
数据项 X 从数据库传输到主内存中属于执行读取操作的事务的工作区中的变量(也称为 X)。如果数据在buffer中,通过read操作将数据读取到work area,如果数据不在buffer中,先通过input将数据从disk读取到buffer,再执行将数据从buffer 读取到work area
-
write(X), which transfers the value in the variable X in the main memory
work areaof the transaction that executed the write operation to the data item X in database.它将执行写入操作的事务的
主内存工作区中变量 X 中的值传输到数据库中的数据项 X。
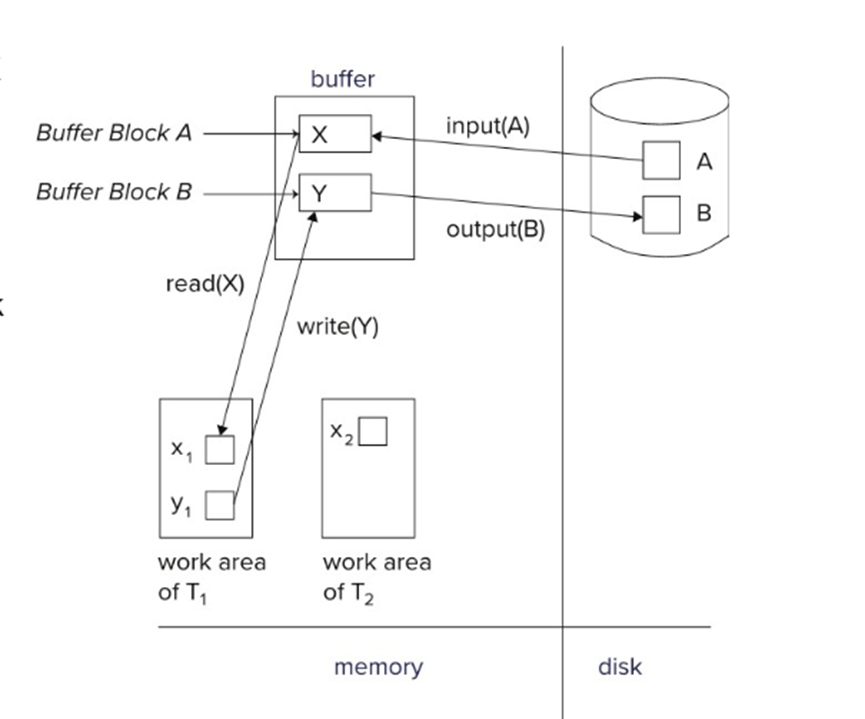
每个事务,都有一个工作空间。工作空间中有该事务需要访问到的数据。这些数据,在某些内存块的里面。如果是write,修改好了这些数据以后,会再写回到内存中去。
!!! Example "Example of Fund Transfer"以转账操作为例:
-
Atomicity requirement
如果事务在步骤 3 之后和步骤 6 之前失败,则资金将“丢失”,从而导致数据库状态不一致 故障可能是由于软件或硬件造成的 系统应确保部分执行的事务的更新不会反映在数据库中(如果执行结束之后出现了问题,数据库应该要撤销之前的操作)
-
Durability requirement
如果事务结束了,我们就把更新同步
-
Consistency requirement
-
Explicitly(显式) specified integrity constraints
e.g. primary keys , foreign keys
数据库把这个定义放在内部,会自己维护
-
Implicit (隐式) integrity constraints
e.g. sum of balances of all accounts minus sum of loan amounts must equal value of cash-in-hand
在事务执行期间,数据库可能会暂时不一致。 当事务成功完成时,数据库必须保持一致。错误的事务逻辑可能导致不一致
-
-
Isolation requirement
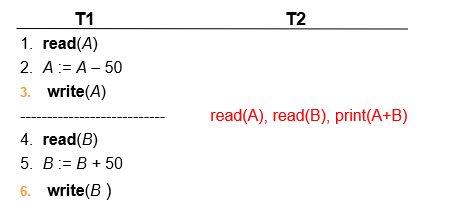
在 step 3 6 之间,另一个事务如果可以访问这个被部分更新的数据库,那么A+B 会小于正确答案。这是因为破坏了隔离性。
隔离性要求:执行事务串行(one after another)
13.2.1 Transaction State¶
-
Active – the initial state; the transaction stays in this state while it is executing
事务在正常执行的状态
-
Partially committed – after the final statement has been executed.
如果事务的操作,已经执行了最后一条语句,就进入准备提交阶段。能否提交取决于具体的执行。
-
Failed -- after the discovery that normal execution can no longer proceed.
不能正常提交。或者是执行过程中发现问题。
-
Aborted(中止) – after the transaction has been rolled back and the database restored to its state prior to the start of the transaction. Two options after it has been aborted:、
事务回滚并将数据库恢复到事务开始前的状态之后(要将该事务进行过的所有操作全部清空)
- restart the transaction
- kill the transaction
-
Committed – after successful completion.

13.3 Concurrent Executions¶
允许多个事务在系统中同时运行的优点是:
-
increased processor and disk utilization,leading to better transaction throughput
提高处理器和磁盘利用率,从而提高事务吞吐量
E.g. one transaction can be using the CPU while another is reading from or writing to the disk
-
reduced average response time for transactions: short transactions need not wait behind long ones.
减少事务响应时间
事务是并发执行的,如果不加以控制可能会有以下问题
Anomalies in Concurrent Executions 并发执行中的异常
Lost Update(丢失修改)Dirty Read(读脏数据)Unrepeatable Read (不可重复读)-
Phantom Problem(幽灵问题 ) -
Lost Update(丢失修改)
Example "Lost Update Example"
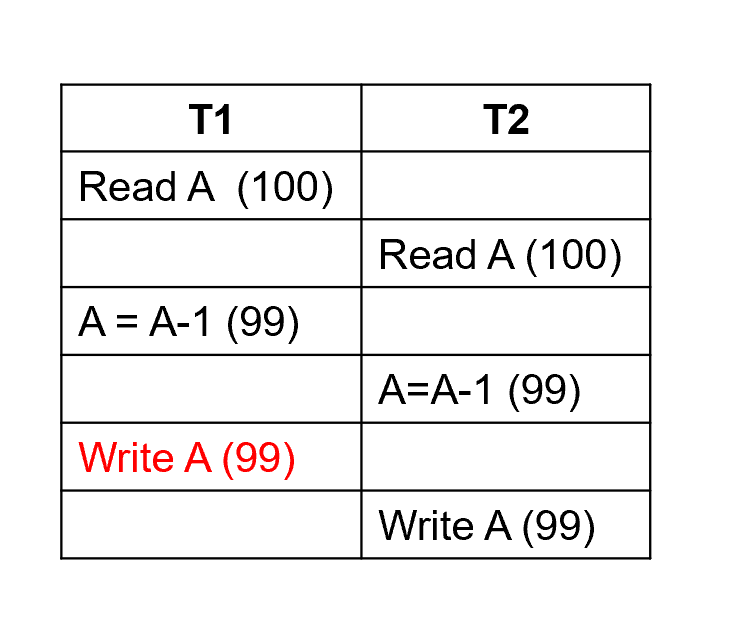
一个人订票后,另一个人读到这里第一个人还没有修改的余量。导致丢失了一次修改。
-
Dirty Read(读脏数据)
Example "Dirty Read"
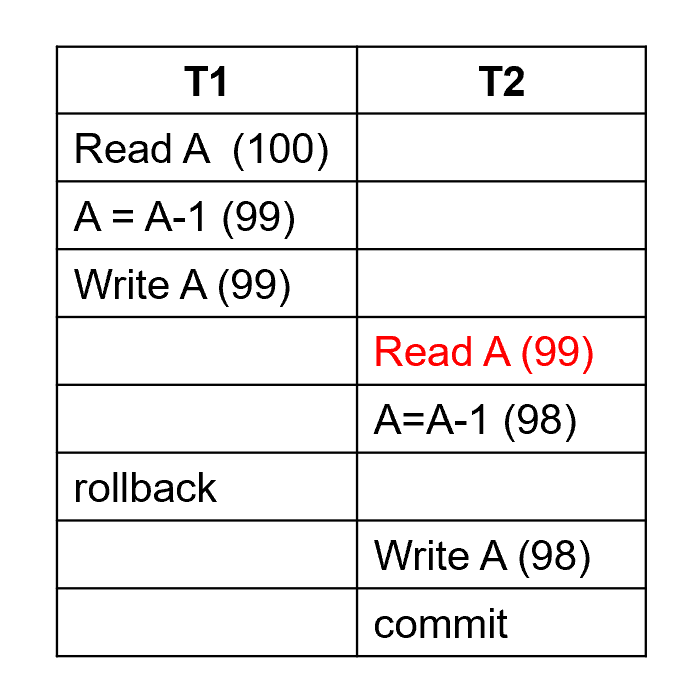
还没有提交的脏数据。假设另一个事务最终没有提交那个脏数据,而是产生回滚,那么读取脏数据的事务对数据库产生的修改将是不正确的。
一个人订票后,另一个人读数据后,但是第一个人放弃了,但是第二个人仍然是用的脏数据。
-
Unrepeatable Read (不可重复读)
Example "Unrepeatable Read"
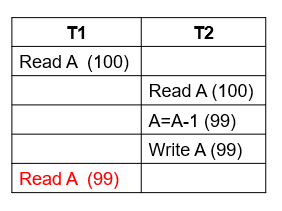
在事务T2没有提交的时候,T1就进行读取。这样,由于隔离性的要求是:在一个事务没有提交时,其他的任何事务都不会影响这个事务。但是,此时T2事务却影响了T1事务读取数据的结果,不满足数据库隔离性的要求。
Isolation 要求我们读到的数据应该是一样的。 -
Phantom Problem(幽灵问题)
Example "Phantom Problem"

同样,在事务T2没有提交的时候,T1就又进行了一次查询。此时T2的插入操作,影响了T1在一个事务当中的查询结果,使前后两次查询结果不一致,因此产生幽灵问题,不满足隔离性的要求。
unrepeatable 是针对已经存在的数据,但是数据的值不同. Phantom 是指数据数量会变多/减少。幽灵问题和不可重复读问题的区别是:
不可重复读是针对一个数据的前后两次读取值不一致的情况,这个数据本身就是存在于数据库中的。
而幽灵问题是指前后两次相同的查询,会多出一些记录,或者少掉一些记录来。
不可重复读问题比较好解决,只需要在事务T1第一次对数据A进行读取时,加上一个S锁即可。那么事务T2将不能对A进行更改。
但幽灵问题解决起来较为困难,代价较高。
13.3.1 Schedules¶
Schedule – a sequences of instructions that specify the chronological order in which instructions of concurrent transactions are executed.
Schedule – 指定并发事务指令执行的时间顺序的指令序列
成功完成执行的事务将有一个提交指令commit作为最后一条语句
- 默认情况下,事务假定执行提交指令作为其最后一步
未能成功完成其执行的事务将有一个中止指令abort作为最后一个语句
事务的执顺序,可以是交叉执行。
-
例1:
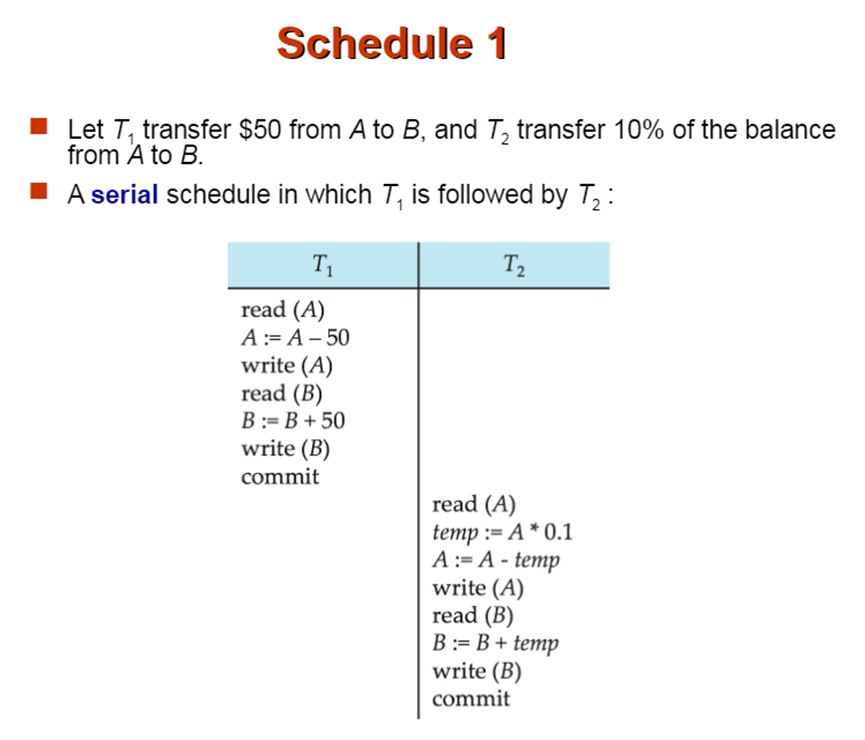
T1 是一个转账事务,T2将百分之十A的余额转给B。
这两个事务完全是
串行执行的,这是串行调度。串行调度,一定是满足隔离性的。
例2:

也是一个串行调度,交换了顺序。
显而易见,串行调度一定是满足隔离性的。
例3:

通过上述变化,最终结果中,A+B仍然是200。这是由于,二者在时间上交错的部分都是不矛盾的,也就是说,交错的部分进行互换,是不影响结果的(
也就是说T1的read(B)及后续操作,可以移动到T2的read(A)操作之前)。因此,这就等价于例1。
同样,这个事务的调度满足隔离性要求。
In Schedules 1, 2 and 3, the sum A + B is preserved.
例4:

事务T1的write(A)在事务T2的write(A)之后,且无法交换。
事务T1的write(B)在事务T2的write(B)之前,且无法交换。
因此,上述两个事务存在丢失修改的问题。写入了两次A,第一次为90,第二次为50,结果为50。
访问相同的数据时,Read和Read操作可以交换,Read和Write操作、Write和Write操作均不能交换。
13.3.2 Serializability¶
Basic Assumption – Each transaction preserves database consistency.
每一个事务都能够保持数据的一致性
A (possibly concurrent) schedule is serializable if it is equivalent to a serial schedule.
如果一个(可能是并发执行的)计划(事务集合),可以等同为一个串行的计划,那么这个计划称为可串行化的。
串行调度一定是可串行化的,交错执行不一定。
- conflict serializability(冲突可串行化)
- view serializability(视图可串行化)
13.3.2.1 Conflict Serializability¶

访问相同的数据时,Read和Read操作可以交换,Read和Write操作、Write和Write操作均不能交换。
也就是说Read和Read不矛盾,Read和Write,Write和Wirte是冲突的
指从冲突操作的角度考虑,是可串行化的。例如Schedule 3中,将交叉执行的两个事务转化为串行执行的两个事务的过程中,两两进行交换的操作,没有产生前后依赖关系(即冲突)的,最终转化称为两个串行执行的事务,这就叫做冲突可串行化。
a conflict between \(l_i\) and \(l_j\) forces a (logical) temporal order between them.
\(l_i\) 和 \(l_j\) 之间的冲突会强制它们在它们之间形成(逻辑)时间顺序。
冲突的操作次序决定事务执行的顺序(因为冲突,不发交换顺序)
如果一个交叉调度是冲突可串行化的,那么串行化以后事务的顺序是由其中一对冲突的操作的先后次序决定的。哪一个事务的冲突操作在前,哪一个事务串行化以后的先后次序就在前。
注意这里针对的是同一个数据项 Q.
conflict equivalent & conflict serializable
If a schedule S can be transformed into a schedule S´ by a series of swaps of non-conflicting instructions, we say that S and S´ are conflict equivalent.
如果一个时间表 S 可以通过一系列不冲突指令的交换转换为时间表 S',我们说 S 和 S 是冲突等价的。(交换不冲突的指令,得到的是冲突等价的调度)
We say that a schedule S is conflict serializable if it is conflict equivalent to a serial schedule.
如果一个调度是冲突可串行化的,那么它冲突等价于串行调度
example:冲突可串行化例子
此处访问不同的数据,read和write能够交换example:不是冲突可串行化的例子
访问相同的数据,read和write不能交换,冲突


13.3.2.2Testing for Serializability¶
Consider some schedule of a set of transactions \(T_1, T_2, \ldots, T_n\)
Precedence graph(前驱图) — a directed graph where the vertices are the transactions (names).
通过考察所有冲突的操作对,画出一个有向图。 如果事务\(Ti\)有一个操作和\(Tj\)的某个操作冲突,如果\(Ti\)的这个操作在\(Tj\)的对应冲突的操作之前,那么\(Ti\)这个节点就和\(Tj\)这个节点之间,存在一条\(Ti\)指向\(Tj\)的有向边。
如果找到环,说明是不可串行化的。否则可以利用拓扑排序(寻找入度为0的点,说明当前事务不与任何事务产生冲突,可以优先执行)。
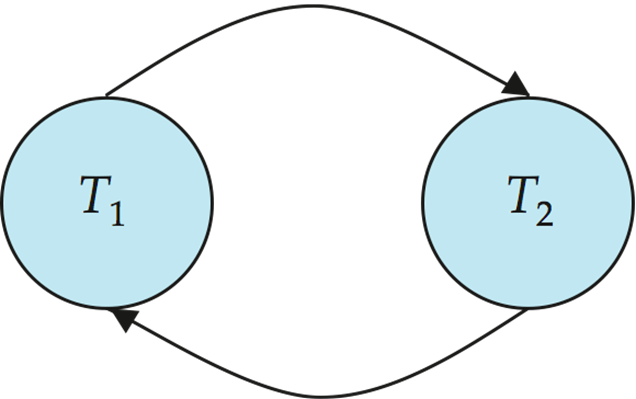
A schedule is conflict serializable if and only if its precedence graph is acyclic.
调度是冲突可串行化的当且仅当前驱图是无环图
如果有向图不存在环,那么这些事务将是冲突可串行化的,并且串行化以后这些事务的执行顺序是对有向图进行
拓扑排序的顺序。
Example
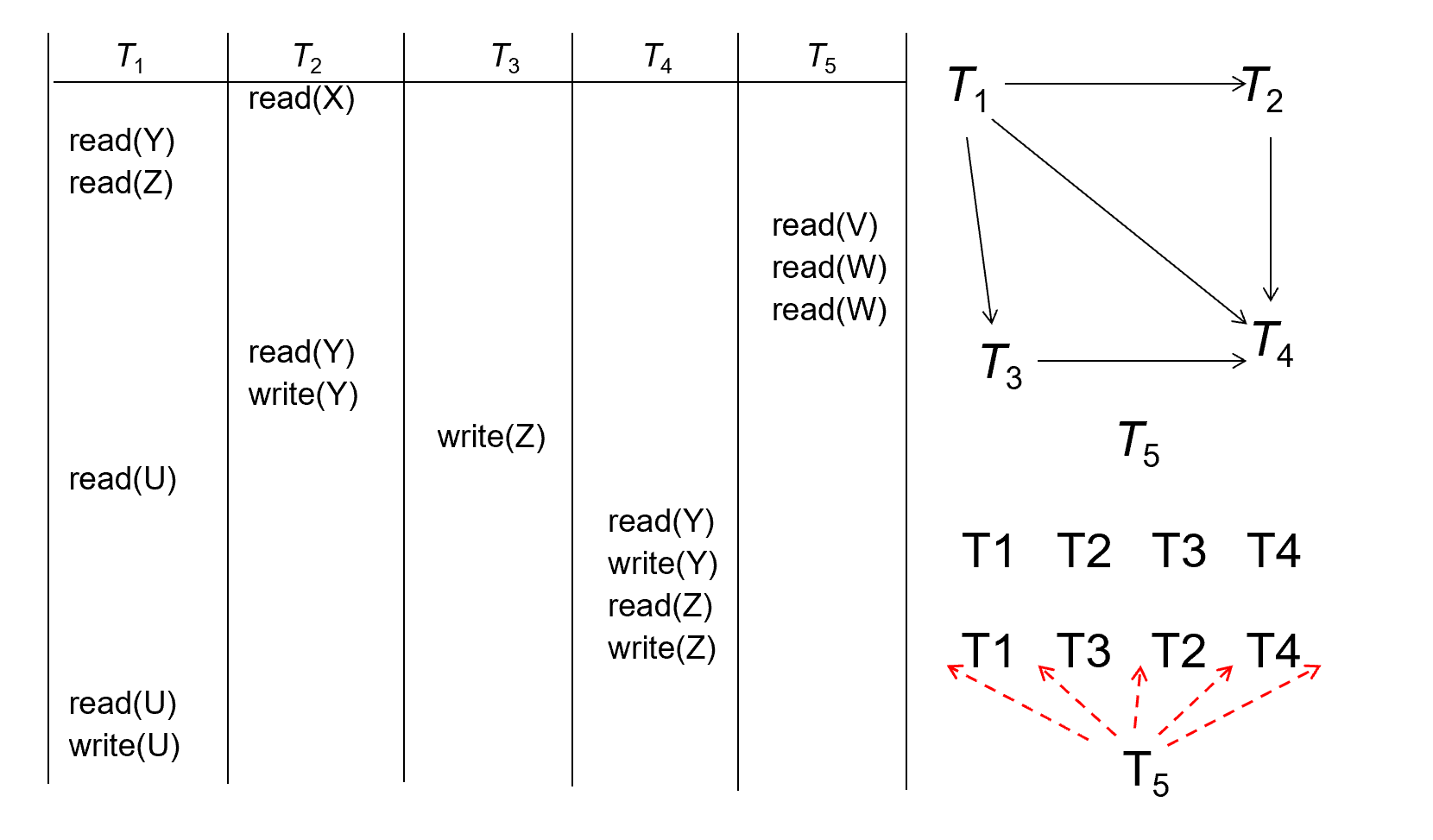
- T1 的 readY 和 T2 的 writeY 冲突,由于T1的readY靠前,所以画一条从T1指向T2的线段
- T1 的 readZ 和 T3 的 writeZ 冲突,需要一条从T1指向T3的边
-
……
进行拓扑排序(
选择入度为0的点),先选择T1,然后将T1出发的边都删除,可以发现T2和T3的入度都是0,此时存在两种情况。 -
T1,T2,T3,T4
- T1,T3,T2,T4
- T5可以随机放置,五种情况。最后有 10 种调度方式。
13.3.2.3 View Serializability¶
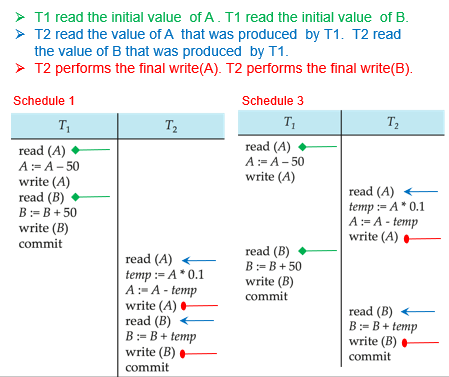
条件如下:
1. 一个交叉调度是视图可串行化的,必要条件之一是:这个交叉调度与其对应的串行调度之间,读到各个数据的初始值的是同一些事务。
例如:
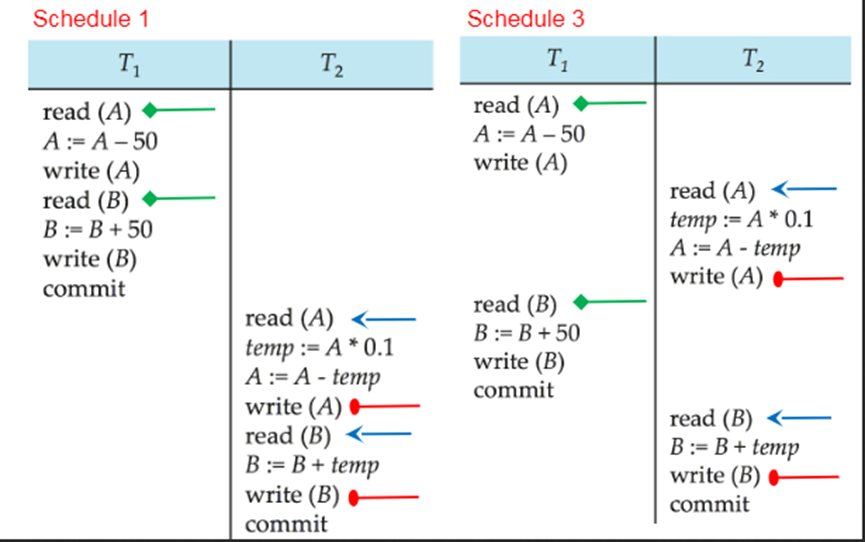
交叉调度Schedule 3中,读取到A的初始值的是T1,读取到B的初始值的也是T1;
而在其对应的串行调度中,读取到A的初始值的是T1,读取到B的初始值的也是T1。
2. 一个交叉调度是视图可串行化的,必要条件之一是:假设其对应的串行调度中的事务Ti执行了Read(Q)操作,并且Q的值是由串行调度中的事务Tj产生的,那么这个交叉调度中,事务Ti执行了Read(Q)操作,Q的值也应当是对应的事务Tj产生的。
例如:
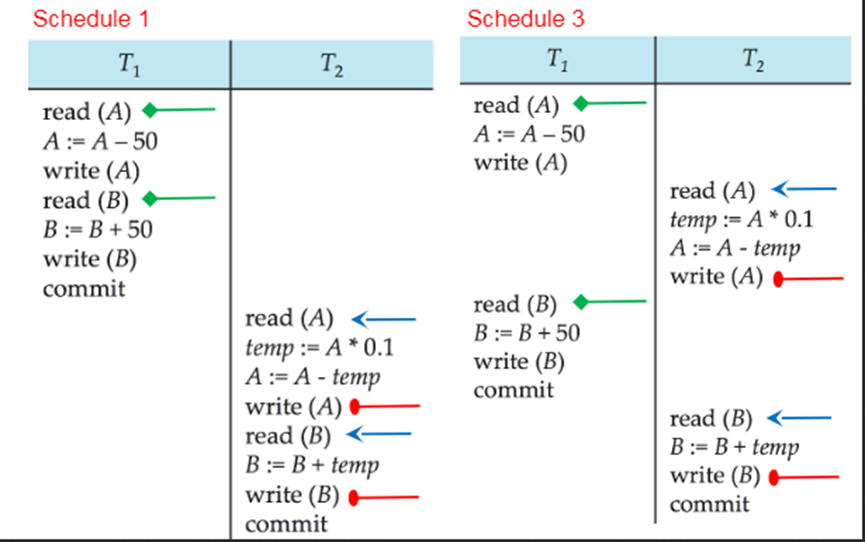
交叉调度Schedule 3中,T2事务读取了A的值,A的值是由T1事务产生的;T2事务读取了B的值,B的值是由T1事务产生的。
而在其对应的串行调度中,T2事务读取了A的值,A的值是由T1事务产生的;T2事务读取了B的值,B的值是由T1事务产生的。
3. 一个交叉调度是视图可串行化的,必要条件之一是:这个交叉调度与其对应的串行调度之间,写入各个数据的终末值的是同一些事务。
例如:
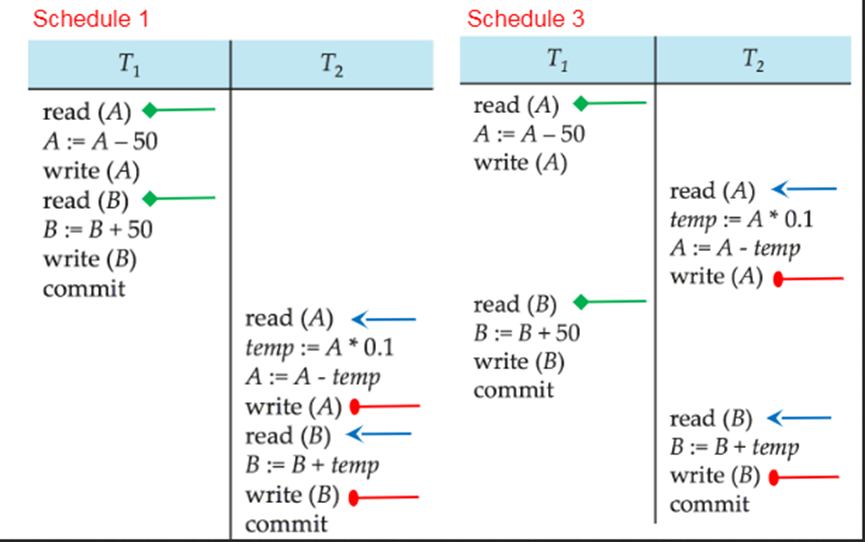
交叉调度Schedule 3中,写入A的终末值的是T2,写入B的终末值的也是T2;
而在其对应的串行调度中,写入A的终末值的是T2,写入B的终末值的也是T2;
上述三个必要条件组成视图可串行化的充分条件。
重要结论:冲突可串行化的都是视图可串行化的,反之不一定。

但是,上面这个交叉调度是视图可串行化的。它串行化得到的串行调度是T27->T28->T29。
- 交叉调度中T27读取Q的初始值,串行调度中T27读取Q的初始值
- 只有一个readQ没有影响
- 交叉调度中Q的最终值由T29写入,串行调度中Q的最终值也由T29写入
这个交叉调度的该串行调度满足上述视图可串行化的三个条件。
13.3.2.4 Other Notions of Serializability¶
有的调度既不是冲突可串行化又不是视图可串行化,但它是可串行化的。

- 不是冲突可交换,readB和writeB冲突
- 不是视图可串行,在串行中T1先读到B,但是在本视图中T5先读到B
等价于 T1-T5.
加减操作是可结合的,这里需要了解事务里具体是什么操作。但我们的简单模型对此不加以区分。
13.4 Recoverable Schedules¶
Recoverable schedule(可恢复调度)
— if a transaction \(T_j\) reads a data item previously written by a transaction \(T_i\) , then the commit operation of \(T_i\) appears before the commit operation of \(T_j\).
如果在一个调度中,事务B读取了事务A先前写入的数据,那么事务A的提交操作,出现在事务B之前,这就称为可恢复调度。
The following schedule (Schedule 11) is not recoverable if T9 commits immediately after the read.

T9 读取了T8写入的数据,然而,T9的提交操作在T8之前。如果之后T8进行了回滚,那么T9事务将向用户显示了不一致的数据库状态。这就会产生“读脏数据”的问题。
如果一个事务读了另一个事务的脏数据,提交次序需要有约束,要在被读事务的后面提交。
13.4.1 Cascading Rollbacks¶
Cascading rollback(级联回滚)
– a single transaction failure leads to a series of transaction rollbacks. Consider the following schedule where none of the transactions has yet committed (so the schedule is recoverable)
上面这个例子中,T11读取了T10写入的值(脏数据),T12又读取了T11写入的值(脏数据.因此,T10发生回滚后,T11也要发生回滚,过后T12也要发生回滚。

Can lead to the undoing of a significant amount of work.
我们更希望用非级联的恢复,否则开销太大。
如何解决?禁止读取脏数据
也就是说,需要等\(T_{10}\)完成commit,\(T_{11}\)才能执行Read操作。缺点是:减小了事务执行的吞吐量
13.4.2 Cascadeless schedule¶
Cascadeless schedules(无级联调度)
— cascading rollbacks cannot occur; for each pair of transactions Ti and Tj such that Tj reads a data item previously written by Ti, the commit operation of Ti appears before the read operation of Tj.
不会发生级联回滚;对于每对事务 Ti 和 Tj,使得 Tj 读取 Ti 之前写入的数据项,Ti 的提交操作出现在 Tj 的读取操作之前。
Cascadeless schedules(无级联调度)
-
不能发生级联回滚;
-
对于每对事务 $Ti $和 \(Tj\),使得 $Tj \(读取 (Ti \(之前写入的数据项,\)Ti\) 的提交操作出现在\) Tj $的读取操作之前。
Every cascadeless schedule is also recoverable 每个无级联计划也是可恢复的
数据库必须提供一种机制,使得所有可能的时间调度都是:
① 冲突或视图可序列化
② 可恢复的,最好是非级联调度的。
从而需要并发控制协议来保证可串行化
并发控制协议允许并发调度,但是要确保并发调度是冲突(或视图)可序列化的,并且是可恢复(最好是无级联回滚的)。
弱一致性水平
一些应用程序愿意接受较弱级别的一致性,允许部分不可序列化的调度,以减少代价。
例如,想要获得所有账户的大致总余额的只读交易;
又例如,为查询优化计算的数据库统计数据可能是近似的。
Tradeoff accuracy for performance 用正确性换取性能
13.5 Transaction Isolation Levels¶
A database must provide a mechanism that will ensure that all possible schedules are
-
either conflict or view serializable, and
保证可串行的
-
are recoverable and preferably cascadeless
保证可恢复的(最好是非级联)
数据库里提供一种协议,每个事务要遵从协议,遵从协议下产生的调度一定是可串行、可恢复的。 这是完全的隔离,代价比较高。
In SQL set transaction isolation level serializable
我们可以设置数据库的隔离级别。
-
Serializable — default
意味着四种问题(幽灵问题、不可重复度、读脏数据、丢失修改)都不能存在。
-
Repeatable read — only committed records to be read, repeated reads of same record must return same value.
However, a transaction may not be serializable – it may find some records inserted by a transaction but not find others.
不管幽灵问题。 -
Read committed — only committed records can be read, but successive reads of record may return different (but committed) values.
只读别的事务已经提交的数据
(不关心幽灵问题,也不关心不可重复读问题,但要保证不读脏数据)
-
Read uncommitted — even uncommitted records may be read.
别的事务未提交的更改过的数据也可以读(连脏数据也允许读)。
Lower degrees of consistency useful for gathering approximate information about the database
13.6 Concurrency Control Protocols¶
通过什么机制决定事务的串行次序
每个并发事务都自觉遵守这个协议,那么就会自发形成一种相互等待关系,形成一种调度,而这种调度可以证明都是可串行的、可恢复的。
-
Lock-Based Protocols 基于锁的协议
-
Lock on whole database vs lock on items
读之前要访问一个共享锁,写之前要访问一个排他锁,冲突了就要等待。通过锁就规定了一个执行的次序。
共享锁(读锁)(S锁)
独占锁(写锁)(X锁)
-
-
Timestamp-Based Protocols 基于时间戳的协议
-
Transaction timestamp assigned e.g. when a transaction begins
事务执行时分配一个时间戳。执行次序按照时间戳排序。 -
Data items store two timestamps
- Read timestamp
- Write timestamp
-
Timestamps are used to detect out of order accesses
-
-
Validation-Based Protocols 基于验证的协议
-
Optimistic concurrency control 对并发控制保持乐观态度。
-
Low rate of conflicts among transactions
-
Each transaction must go through 3 phases:
Read phase -> Validation phase -> Write phase
访问数据,或者修改数据后,在要提交的时候,验证一下和其他事务是否冲突。(在partially committed阶段)
-