14. Concurrency Control¶
约 6723 个字 预计阅读时间 34 分钟
Abstract
- Lock-Based Protocols(基于锁的协议)
- Deadlock Handling (死锁处理)
- Multiple Granularity (多粒度)
- Insert and Delete Operations
- Multiversion Schemes (多版本机制)
- timestamp-Based Protocols (基于时间戳的协议)
- Validation-Based Protocols (基于有效性的协议)
14.1 Lock-Based Protocols¶
基于锁的并发控制
A lock is a mechanism to control concurrent access to a data item
锁是一种控制对数据项的并发访问的机制
-
exclusive(X) 排他锁
Data item can be both read as well as written.
X-lock is requested using lock-X instruction. -
shared(X) 共享锁
Data item can only be read.
S-lock is requested using lock-S instruction.
要写一个数据,先申请获得 X 锁;要读一个数据,先申请获得 S 锁。
访问结束后释放这个锁。
访问数据之前必须获得对应的锁,如果锁冲突了需要等待。
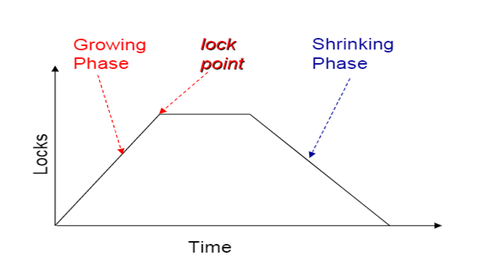
14.1.1 The Two-Phase Locking Protocol¶
事务的加锁和减锁分为两个阶段。
-
Phase 1: Growing Phase (增长阶段)
- transaction may obtain locks
- transaction may not release locks
-
Phase 2: Shrinking Phase(缩减阶段)
-
transaction may release locks
-
transaction may not obtain locks
一个事务一旦开始释放锁,就不能再加锁了。
-
事务两个阶段的分界线(lock point), 即获得了
最后一个锁(完成获得这个动作)的时间点。 这样每个事务都有一个 lock point, 按照这个时间排序即可得到串行化的执行顺序。

Two-Phase Locking Protocol assures serializability.
It can be proved that the transactions can be serialized in the order of their lock points.定理: 一些事务可以按照其lock point的顺序,进行冲突可串行化的调度。
可以按 lock points 串行化,但不是只能按照这么串行化
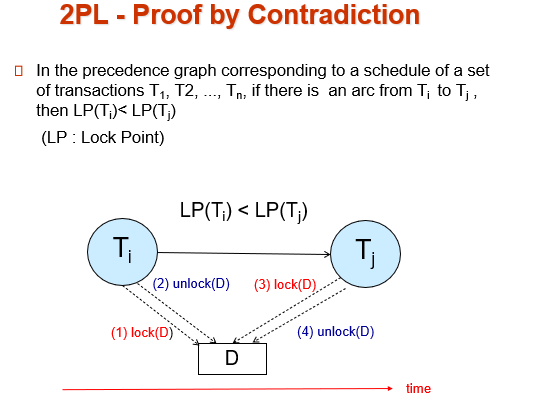
证明:如果在前驱图中\(Ti\)对(\(Tj\)\)有一条指向的有向边,那么\(Ti\)的lock point一定小于(\(Tj\)\)的lock point。因为,如果\(Ti\)对(\(Tj\)\)有一条指向的有向边,那么\(Ti\)和\(Tj\)之间肯定有一对冲突的操作访问相同的数据。
只有\(Ti\)将这个数据的锁放掉后,(\(Tj\)\)才可以给这个数据加锁。由于lock point过后,事务不会再加锁,因此此时\(Ti\)放锁一定处于ti lock point之后,\(Tj\)加锁一定处于\(Tj\) lock point之前。因此,ti的lock point 一定小于\(Tj\)的lock point。
因此,假设前驱图中有环,那么就表明lock point的关系为T1lock point < T2lock point <…< Tn lock point < T1lock point。
得到T1lock point < T1lock point,矛盾。
因此这些事务的前驱图中一定没有环。因此这些事务可以进行冲突可串行化的调度(按照拓扑排序的顺序)。
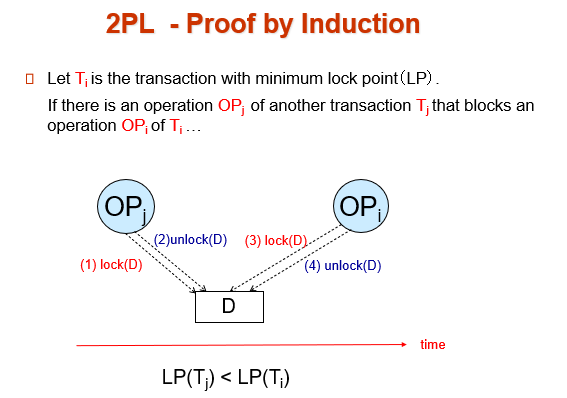
\(OP_j\) block operation \(OP_i\), \(OP_j\)先对D进行上锁,在\(OP_j\)完成解锁之后,才能执行\(OP_i\)的上锁操作,所以\(T_j\)的lock point早于\(T_i\)的lock point
上面基本的两阶段封锁协议无法保证事务的可恢复性(要求不能读取脏数据)
Extensions to basic two-phase locking(基本两阶段封锁) needed to ensure recoverability of freedom from cascading roll-back
扩展基本两阶段封锁,以确保从级联回滚中恢复自由
-
Strict two-phase locking(严格两阶段封锁):
a transaction must hold all its exclusive locks till it commits/aborts.
所有的X锁需要在事务即将提交或者停止时才能解锁Ensures recoverability and avoids cascading roll-backs.
X 锁加的时间更长,X锁要到事务即将提交或者即将回滚的时候再放开,以防止读脏数据的问题。
好处:保证可恢复性,防止读脏数据的问题。
坏处:代价是X锁的时间更长,其他事务等待的时间变长,会降低并发度。 -
Rigorous two-phase locking(强两阶段封锁):
a transaction must hold all locks till commit/abort.
所有的锁(S锁和X锁)都需要在事务即将提交或者停止时才能释放transactions can be serialized in the order in which they commit.
所有锁都要到即将提交或者即将回滚的时候再放开。
Two-phase locking is not a necessary condition for serializability.两阶段封锁协议是可串行化的充分条件
两阶段封锁协议,不是可串行化的必要条件
也就是说,遵循两阶段封锁协议一定能得到可串行化的事务,但是可串行化的事务,并不一定满足两阶段封锁协议。
eg:
所有read/write操作针对的是不同的对象,此时可以任意上锁解锁,不满足两阶段封锁协议
以下是read/write操作针对相同的对象
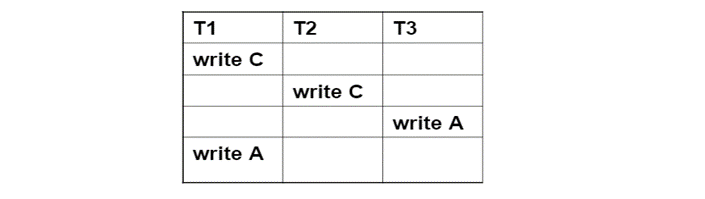
这些事务的前驱图如下:
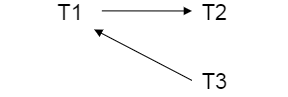
因此,这些事务可以按照T3->T1->T2进行冲突可串行化的调度。
这些事务的加锁与放锁操作如下:

可以看出,T1事务放锁之后,又进行了加锁操作。因此,T1事务不满足两阶段封锁协议。两阶段封锁协议要求只能存在增长阶段和缩减阶段,也就是说在一个事务内unlock之后不能再次lock
事务满足两阶段封锁协议,是可以进行冲突可串行化调度的充分条件,而不是必要条件。
14.1.2 2PL - Proof¶
-
Proof by Contradiction
如果有 \(T_i\)->\(Tj\) 的有向边,那 \(T_i\) 的 lockpoint 一定小于 \(Tj\).
\(T_i\)->\(Tj\) 肯定有一个冲突的访问(对同一个数据)那 \(Tj\) 在获得锁的时候\(T_i\)已经放锁了,得证。
-
Proof by Induction
只需证明: Lock point 最小的事务,可以无障碍地交换到调度最前。
假如有事务拦住他了,证明这是不可能发生的。(与 lock point 最小矛盾)
\(OP_j\) block operation \(OP_i\), \(OP_j\)先对D进行上锁,在\(OP_j\)完成解锁之后,才能执行\(OP_i\)的上锁操作,所以\(T_j\)的lock point早于\(T_i\)的lock point
14.1.3 Lock Conversions¶
带有锁转换的两阶段封锁协议:
有些时候,访问数据库数据时,我们需要先读数据,再修改数据。如果我们读取数据加上S锁,修改数据先放掉S锁,再加上X锁,就不满足两阶段封锁协议,导致事务之间可能不能冲突可串行化。假如一开始就加上X锁,又会降低并发度。
解决方案是:一开始加上S锁,等到要修改数据时,将S锁升级为X锁。
Two-phase locking with lock conversions:
- First Phase: 进行加锁操作,也可以进行锁升级操作。
- can acquire a lock-S or lock-X on a data item
can convert a lock-S to a lock-X (lock-upgrade*)
- Second Phase: 进行放锁操作,也可以进行锁降级操作。
- can release a lock-S or lock-X
can convert a lock-X to a lock-S (lock-downgrade*)
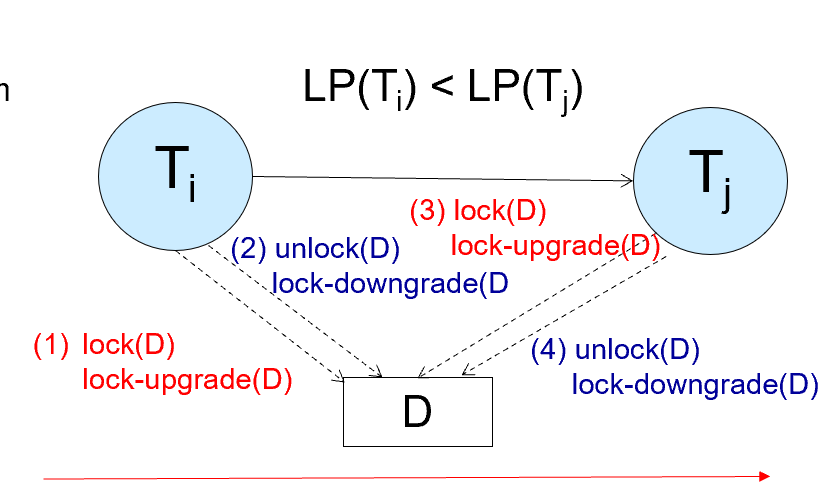
带有锁转换的两阶段封锁协议,也可以保证事务按照lock point排序,是可以实现冲突可串行化调度的。
例如Ti发生在Tj之前,只有Ti的锁发生降级或者释放后,Tj才能对一个对象进行锁升级或者加锁,这样Ti的lock point就小于Tj的lock pointThis protocol assures serializability.
申请哪个锁是由数据库内部管理决定,不是由程序员显示调用。(自动加锁)


如果已经有锁了,直接读;否则申请读锁。
14.2 Implementation of Locking¶
A lock manager can be implemented as a separate process to which transactions send lock and unlock requests.
锁管理器可以作为事务发送锁定和解锁请求的单独进程来实现
锁管理器通过发送锁授予消息(或在死锁的情况下要求事务回滚的消息)来回复锁请求 请求事务将等待,直到其请求得到响应
锁管理器维护一个称为锁表(lock table)的数据结构,以记录已授予的锁和待处理的请求
锁定表通常作为内存中的哈希表实现,该哈希表根据被锁定的数据项的名称编制索引
14.2.1 Lock Table¶
Lock table records granted locks and waiting requests.
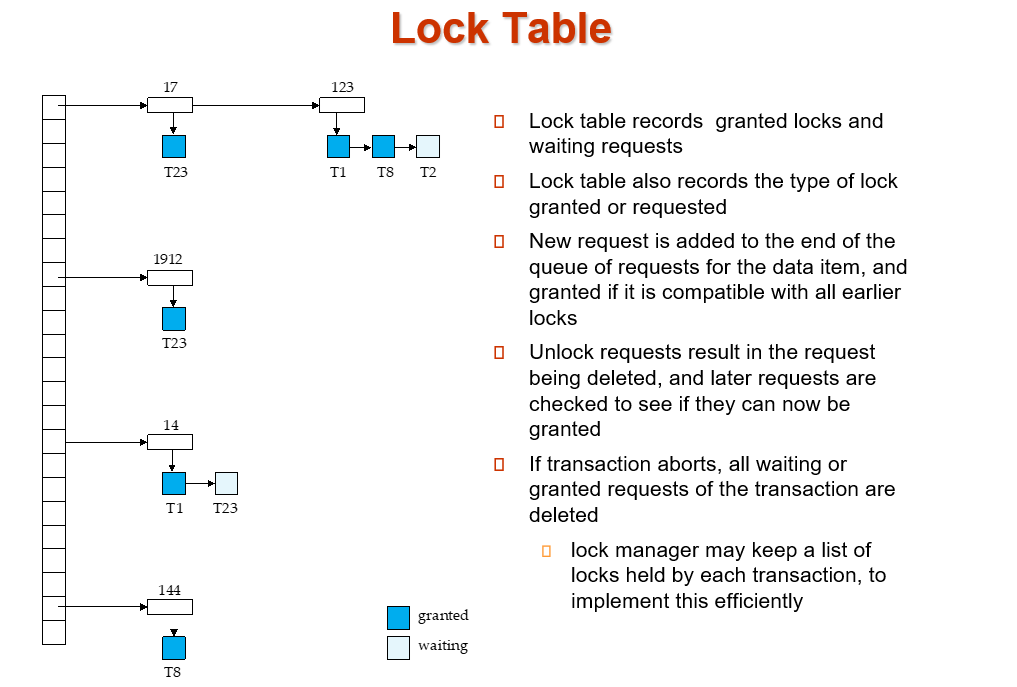
锁定表记录已授予的锁定和等待请求
锁定表还记录授予或请求的锁定类型
新请求将添加到数据项请求队列的末尾,如果该请求与所有早期锁兼容,则授予新请求 解锁请求会导致请求被删除,并检查后续请求以查看它们现在是否可以授予
如果事务中止,则删除事务的所有等待请求或已授予请求(
也就是释放所有的锁)。锁管理器可以保留每个事务持有的锁列表,以有效地实现这一点
每个记录的 id 可以放进哈希表。
如这里记录 123, T1、T8 获得了 S 锁,但 T2 在等待获得 X 锁。
T1: lock-X(D) 通过 D 的 id 找到哈希表上的项,在对应项上增加。根据是否相容决定是获得锁还是等待。
unlock 类似,先找到对应的数据,拿掉对应的项。同时看后续的项是否可以获得锁。
如果一个事务 commit, 需要放掉所有的锁,我们需要去找。因此我们还需要一个事务的表,标明每个事务所用的锁。
14.2.2 Deadlock Handling¶
System is deadlocked if there is a set of transactions such that every transaction in the set is waiting for another transaction in the set.
如果存在一组事务,使得集合中的每个事务都在等待集合中的另一个事务,则系统将死锁。
Two-phase locking does not ensure freedom from deadlocks.

由于要遵循两阶段封锁协议,因此T1给A加锁了以后,在没有给B加锁之前,不会将A的锁放掉; T2 给B加锁了以后,在没有给A加锁之前,不会将这B的锁放掉;
因此,产生了互相等待,然而此时T1不会把A的锁放掉,T2也不会把B的锁放掉,从而互相等待是无限循环。
解决方法:1. Deadlock prevention 2. Timeout-Based Schemas
Deadlock prevention protocols(死锁预防协议) ensure that the system will never enter into a deadlock state.
Some prevention strategies:
-
Require that each transaction locks all its data items before it begins execution (predeclaration).
执行前一次性获得所有锁(在执行之前预先知道需要的锁)。一个事务要进行,申请的锁要么全部给这个事务,让这个事务进行,要么一个都不给这个事务,让这个事务不要进行,防止与其他事务形成死锁。
-
Impose partial ordering of all data items and require that a transaction can lock data items only in the order specified by the partial order (graph-based protocol).
对数据访问规定一种次序。比如规定必须先拿咖啡再拿咖啡伴侣。对数据的访问规定一种次序(偏序集)(有向无环图),那么就不会产生死锁(循环等待)。
例如,假设有两个事务:
T1: A-50 B+50
T2: B-10 A+10
我们可以执行作:
T1: A-50 B+50
T2: A+10 B-10
这样,可以降低出现死锁的概率。
规定先访问A,再访问B。T1事务先给A上锁,此时T2事务将无法执行,知道T1事务完成对B上锁,对A,B都解锁之后,才执行事务B
timeout-Based Schemes:
-
a transaction waits for a lock only for a specified amount of time. After that, the wait times out and the transaction is rolled back.事务仅在指定的时间内等待锁定。等待超时,事务将回滚。
-
thus deadlocks are not possible.
-
simple to implement; but starvation is possible. Also difficult to determine good value of the timeout interval.
时长不好规定。但可能有事务老是申请不到自己的锁。
14.2.3 Deadlock Detection¶
定期检查数据库内是否有死锁,如果有就选择一个事务将其回滚。
wait-for graph
请注意:此处出现了第二种类型的图
前驱图:Ti->Tj表示Ti需要在Tj之前完成,对应有lock-point Ti小于Tj等待图:Ti->Tj表示Ti在等待Tj,也就是说Tj需要在Ti之前完成
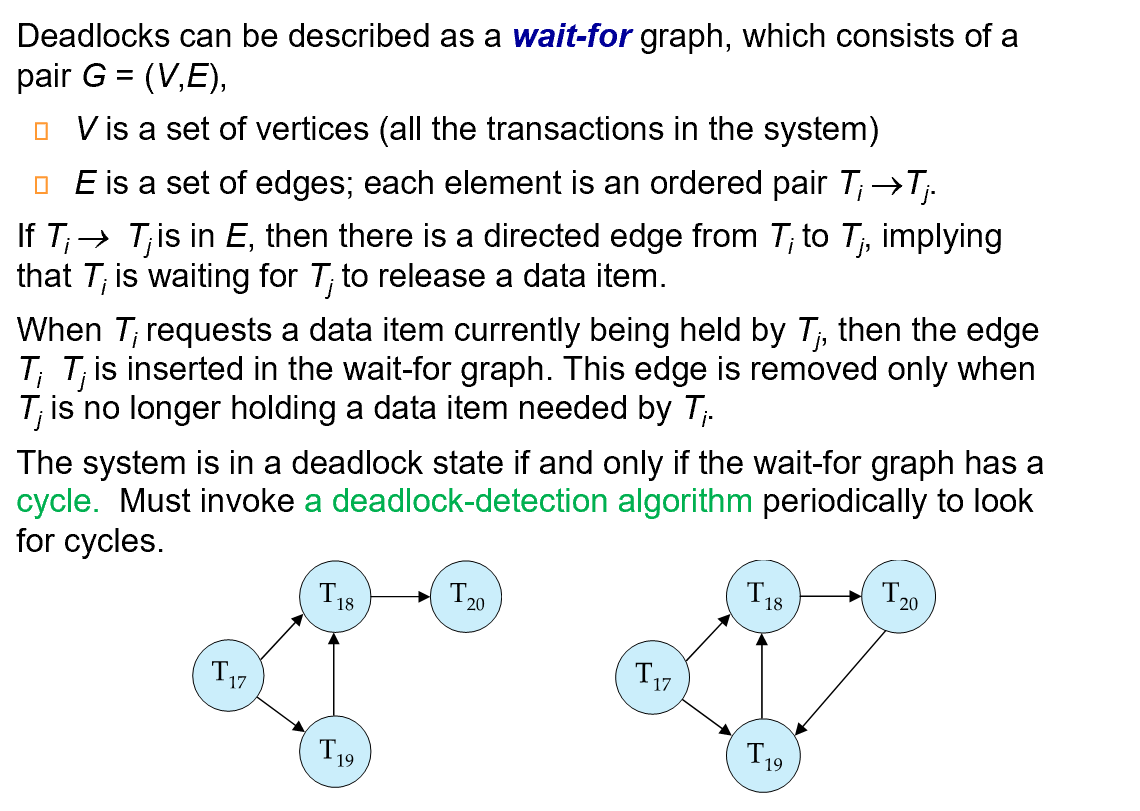
死锁检测:
每隔一定时间,数据库后台会有一个进程定期检查数据库中是否出现死锁。
在数据库中,死锁的检查利用了“等待图”。
等待图中,箭头\(T_i \rightarrow T_j\)表示,\(Ti\)在等待\(Tj\)事务的锁。
如果在等待图中存在环,表示出现了死锁。
通过刚刚的 Lock Table, 我们可以得到等待关系。(后面的 waited 等待前面的 granted)
When deadlock is detected : 当死锁发生/检测到,该如何处理?
-
Some transaction will have to rolled back (made a victim) to break deadlock. Select that transaction as victim that will incur minimum cost.
某些事务必须回滚(成为受害者)才能打破僵局。 选择该交易作为受害者,这将产生最低成本。
执行操作最少或者锁最多的 -
Rollback -- determine how far to roll back transaction
- Total rollback: Abort the transaction and then restart it.
- More effective to roll back transaction only as far as necessary to break deadlock.
-
Starvation happens if same transaction is always chosen as victim. Include the number of rollbacks in the cost factor to avoid starvation
饥饿表示同一事务被多次选为受害者,发生rollback。因此为防止此类现象,需要将回滚的次数纳入回滚对象选择的标准
Example
(a) 哪些事务产生了死锁?
作出等待图,查看环。(T1/T2/T6)
(b) 为了解决死锁问题,哪个事务需要被roll back?(假如要求为:回滚掉的事务,需要释放出最多的锁)
在环中选择一个事务进行回滚。(T2)

T1 等 T2, T2 等 T6, T6 等 T1.(注意这里 T5 是等待 T6 而不是 T2)
14.2.4 Graph-Based Protocols¶
基于图的协议
假设我们知道数据是按偏序访问的,可以有更高级的协议。
数据按照某种偏序关系访问。

The tree-protocol is a simple kind of graph protocol. 树协议是图协议的一种
-
Only exclusive locks are allowed. 只有一种锁:X锁
-
The first lock by \(T_i\) may be on any data item. Subsequently, a data Q can be locked by \(T_i\) only if the parent of Q is currently locked by \(T_i\)
第一个锁可以加在树结构的任意一个结点上。 但是,后面要在某一个结点上加锁的前提是,
父节点已经被锁住了。 -
Data items may be unlocked at any time.
一个结点上的锁,在数据访问完毕后,可以在任何时候放掉。
-
A data item that has been locked and unlocked by \(T_i\) cannot subsequently be relocked by \(T_i\)
放了之后不能再加锁了。
The tree protocol ensures conflict serializability as well as freedom from deadlock.
树协议的性质:虽然不是两阶段封锁协议,但是保证冲突可串行化的,同时,又是不存在死锁的。
Example
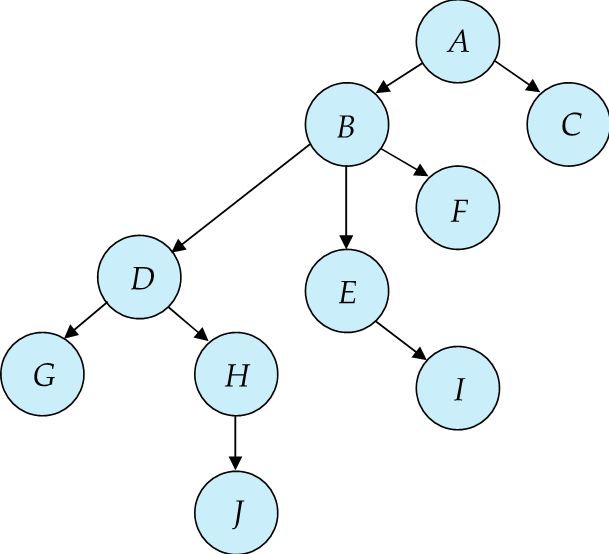
比如这里我们先锁 D, 随后锁 G, 放掉, 锁 H, (但是不能锁J,因为父结点H还没有上锁)这时 D 已经没用了可以放掉。随后我们锁 J, H 也就没用了也可以放掉。最后放掉 J.
要访问G,J,需要先对最小公共祖先上锁
-
Advantages
-
Unlocking may occur earlier in the tree-locking protocol than in the two-phase locking protocol.
shorter waiting times, and increase in concurrency
锁可以更早释放,不用等待第二阶段。用完就可以放,提高了并发度。
-
protocol is deadlock-free
树结构,显然不存在环no rollbacks are required
树协议的好处:一个数据的访问的锁,访问完毕就可以释放,因此可以提高并发度,降低锁上面的等待时间。并且,不会产生死锁。
-
-
Disadvantages
-
Protocol does not guarantee recoverability or cascade freedomNeed to introduce commit dependencies to ensure recoverability
早放锁,意味着可能会读脏数据,不可恢复。这就对 commit 顺序有要求。
-
transactions may have to
lock more data items than needed.-
increased locking overhead, and additional waiting time
比如刚刚的图中,我们访问 G, J, 需要从 D 开始访问。会锁上更多数据。
-
potential decrease in concurrency
-
树协议的缺点:1. 不能保证可恢复性,允许读脏数据。因此,基于锁的并发控制协议中,为了保证可恢复性,一个事务如果读取了另一个事务写入的数据,那么这个事务的commit操作,一定要在另一个事务之后。2. 会锁上更多不需要的数据,降低并发度
-
14.3 Multiple Granularity¶
Multiple Granularity 多粒度
可以锁在记录上(如 update table set ...;),也可以锁在整个表上(如 select * from table;)。
Granularity of locking (level in tree where locking is done):
- fine granularity(细粒度) (lower in tree): high concurrency, high locking overhead
- coarse granularity(粗粒度) (higher in tree): low locking overhead, low concurrency
Example "Example of Granularity Hierarchy"
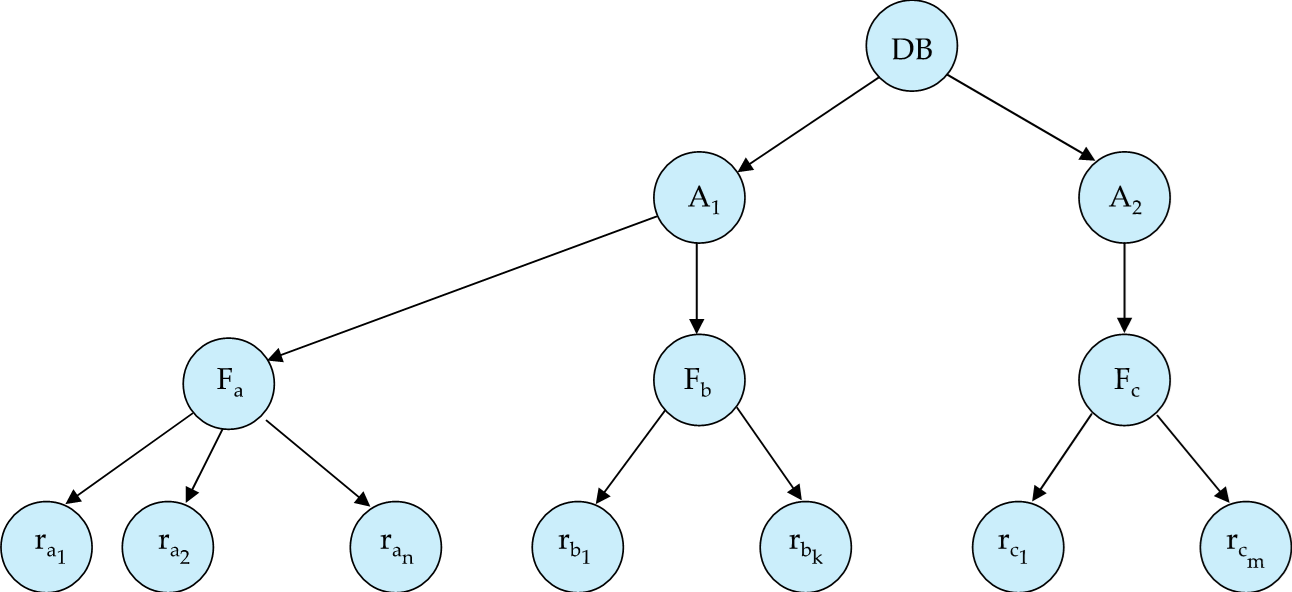
The levels, starting from the coarsest (top) level are
- database
- area
- File(table)
- record
S锁、X锁可以加到细粒度的层面上,也可以加到粗粒度的层面上。
14.3.1 Intention Lock Modes¶
有一个问题:粗粒度上面的锁和细粒度上面的锁如何进行有效的判断?细粒度上假如已经加了一个S锁或X锁,那么粗粒度上加锁是否冲突?
记录和表上都可以加 S/X 锁。但是当事务涉及到多个粒度,如何判断是否冲突,如一个表的 S 锁和一个记录的 X 锁是冲突的。 我们引入了其他锁,意向锁(IS, IX, SIX)
- 如果一个事务,要在某一个细粒度数据(如记录)上面加上S锁,那么这个事务必须要在这个细粒度数据的父节点(如表)这一粗粒度数据上加上IS锁。
(意向共享锁) - 如果一个事务,要在某一个细粒度数据(如记录)上面加上X锁,那么这个事务必须要在这个细粒度数据的父节点(如表)这一粗粒度数据上加上IX锁。
(意向排他锁) - SIX锁,是S锁和IX锁的结合。例如,一个表的某些记录需要直接读取,有些记录可能产生更改,就在表层级上加上SIX锁,
这样表中需要读的记录不用再加上S锁了,表中需要写的记录需要加上X锁。(共享意向排他)
如果粗粒度(如表)上已经加了IX锁,表示表的子节点的某条记录加上 X锁。此时如果想对整个表加上S锁,那么S锁会和IX锁产生冲突。
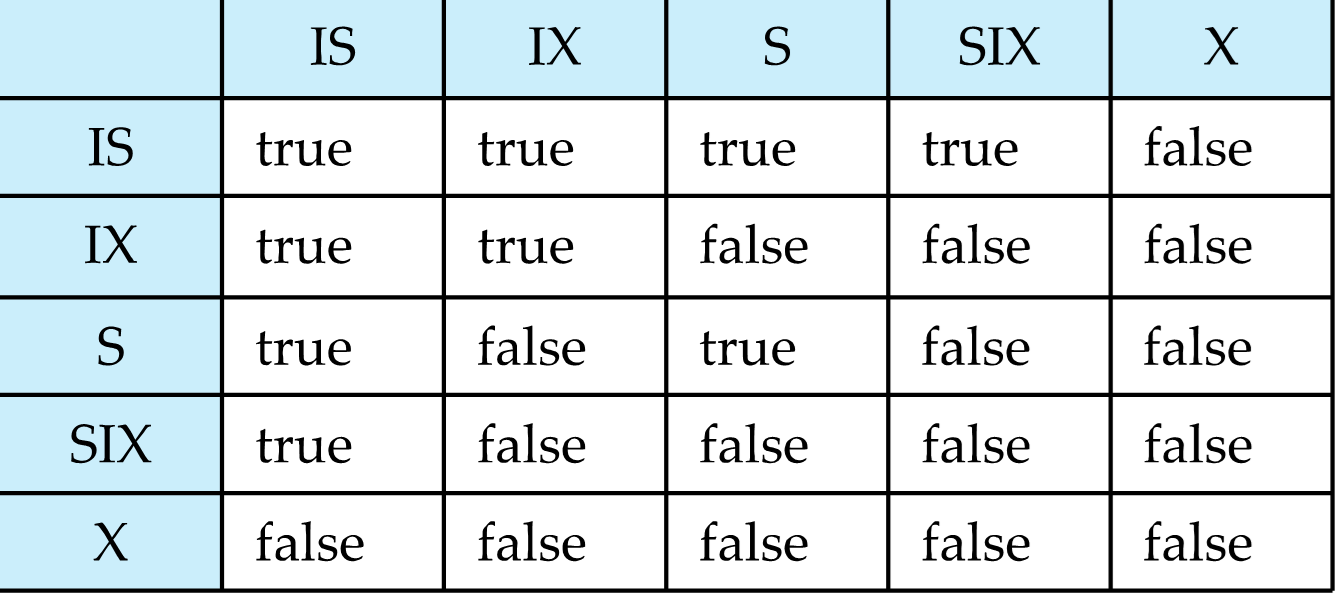
- IS 和 IX 是不冲突的。在表上是不冲突的,可能在记录上冲突(
即对一个记录又读又写,冲突发生在记录层面而非表)。- S和X是对当前粒度加锁,表示所有的子粒度全部被加上当前的锁
- IS和IX表示子粒度中一些数据被加上S锁或者X锁
- SIX 表示当前粒度加S锁,子粒度有些加上了X锁,也就是所有子粒度都加上S锁,部分加上X锁(需要后续申请,取代之前的S锁,这样就不会冲突)。
为什么同一个结点,SIX锁会和S锁冲突呢?因为当前结点加上SIX锁表示存在部分子结点是X锁,当前结点S锁表示所有的子结点都被加上S锁,这时存在孩子既有S锁又有X锁,造成冲突。
为什么同一个结点,IX锁会和X锁冲突呢?针对X锁比较特殊,没锁但是硬加X锁就会错误。但是IS和S就不冲突example:
① 如果要在一个结点Q上加上S或者IS锁,那么其父节点一定要加上IX锁或者IS锁:
如果一个结点要加上S或者IS锁,表明这个结点的全部子节点或者部分子节点上加S锁。那么父节点不可能加S锁,因为S锁会加在父节点的更低层级。此时,父节点只能加IS锁或者IX锁。
② 如果要在一个结点Q上加上X锁、SIX锁或IX锁,那么其父节点一定要加上IX锁或SIX锁。
如果要在一个结点Q上加上X锁、SIX锁或者IX锁,表示这个结点的全部子节点或者部分子节点上加X锁。那么父节点不可能加X锁,因为X锁会加在父节点的更低层级。此时,父节点只能加上IX锁或者SIX锁。
-
intention-shared (IS): indicates explicit locking at a lower level of the tree but only with shared locks. 在下面会加 S 锁。
-
intention-exclusive (IX): indicates explicit locking at a lower level with exclusive or shared locks 在下面会加 X 锁。
-
shared and intention-exclusive (SIX): the subtree rooted by that node is locked explicitly in shared mode and explicit locking is being done at a lower level with exclusive-mode locks.

事务T用如下规则锁定结点Q:
1. 必须遵守锁的兼容性矩阵。
2. 首先,要锁定树的根,即最粗的粒度,可以以任何方式进行锁定。假如只读,就加上S锁,如果要进行修改,就加上X锁。
3. 如果要在一个结点Q上加上S或者IS锁,那么其父节点一定要加上IX锁或者IS锁。
4. 如果要在一个结点Q上加上X锁、SIX锁或IX锁,那么其父节点一定要加上IX锁或SIX锁。
5. 事务T遵循两阶段封锁协议。
6. 解锁结点Q的时候,必须保证Q没有孩子正在被锁定(所以解锁是从下往上)。
要符合相容矩阵。从最粗的粒度开始访问。要加锁的时候注意,对父亲的锁有要求。
example:
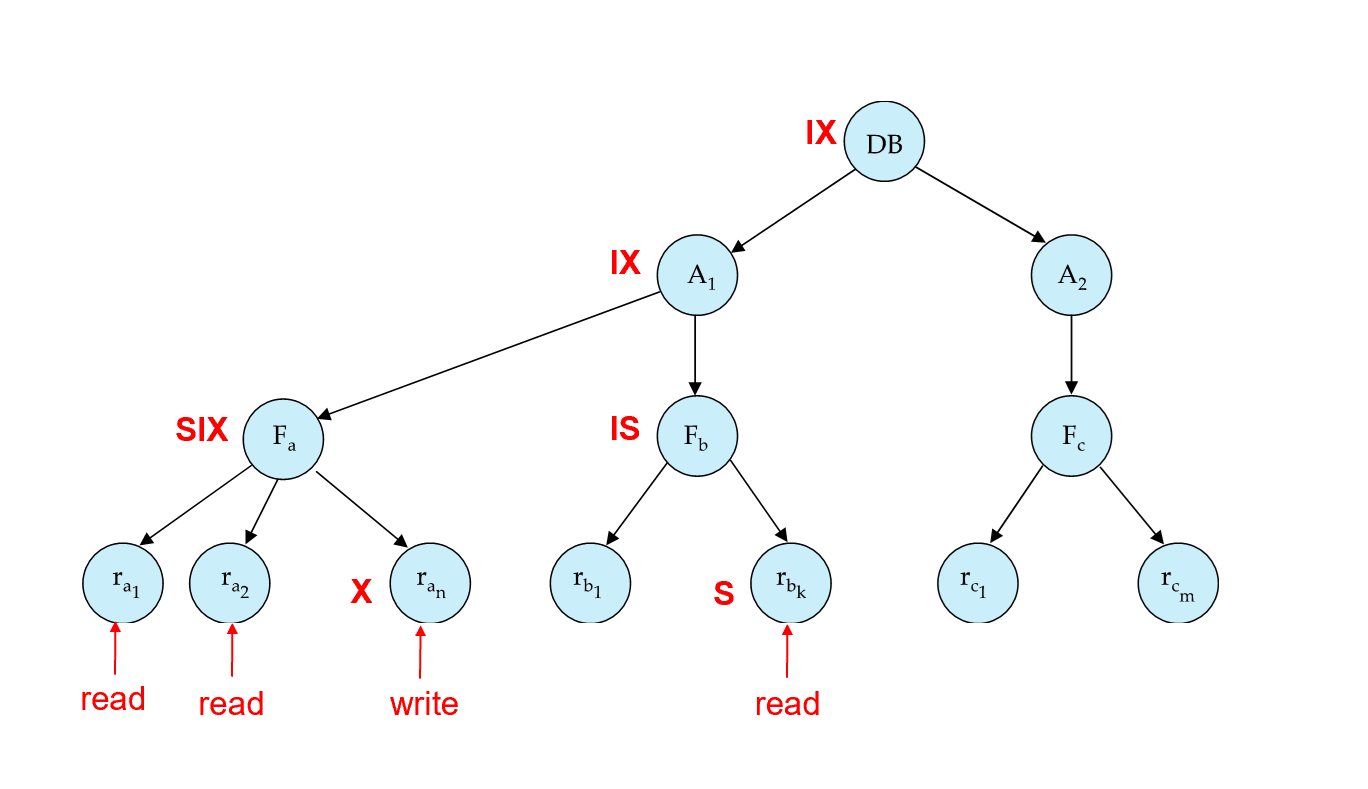
直观来说,上锁是从根节点向下上锁的,放锁是从叶子结点一层层向上放锁的。
先在根节点上加上IX锁,表明下面的结点可能会产生修改。再在左子节点上加上IX锁,表明下面的结点可能会产生修改。
然后,在表这个粒度上,对表Fa加上SIX锁,表明要读取整个表的信息,同时可能对表中某些记录产生更改。
最后,在记录这个细粒度上,对某些记录上加上X锁,表示要更改这条记录。对于加了X锁的这条记录,可以去更改;但是对于其他的记录,不用再加上S锁了,可以直接去读。
14.4 Insert and Delete Operations¶
数据库里除了 R/W 还有插入、删除等操作。
需要定义 R/W 和插入/删除是否冲突。
If two-phase locking is used :
- A delete operation may be performed only if the transaction deleting the tuple has an exclusive lock on the tuple to be deleted.
删除前需要加 X 锁。
- A transaction that inserts a new tuple into the database is given an X-mode lock on the tuple
插入之前是没有这个数据的,无法先加锁。应该插入之后马上加上 X 锁。
Insertions and deletions can lead to the phantom phenomenon.
插入和删除会导致幽灵问题,该如何解决?将data与relation相关联,以表示已知关系包含哪些元组的信息。
添加谓词锁,例如我现在select age=18的学生,那么我就不能插入或者删除age=18的学生,需要添加lock_S(age=18)
14.4.1 Index Locking Protocol¶
其实插入/删除操作隐含地修改了信息,只是没有被表示出来。我们可以这个信息显示化,加锁。 如果表上有索引,我们在扫描索引的时候会在叶子修改,我们在这里进行检测。

Index Locking on a B+ -Tree
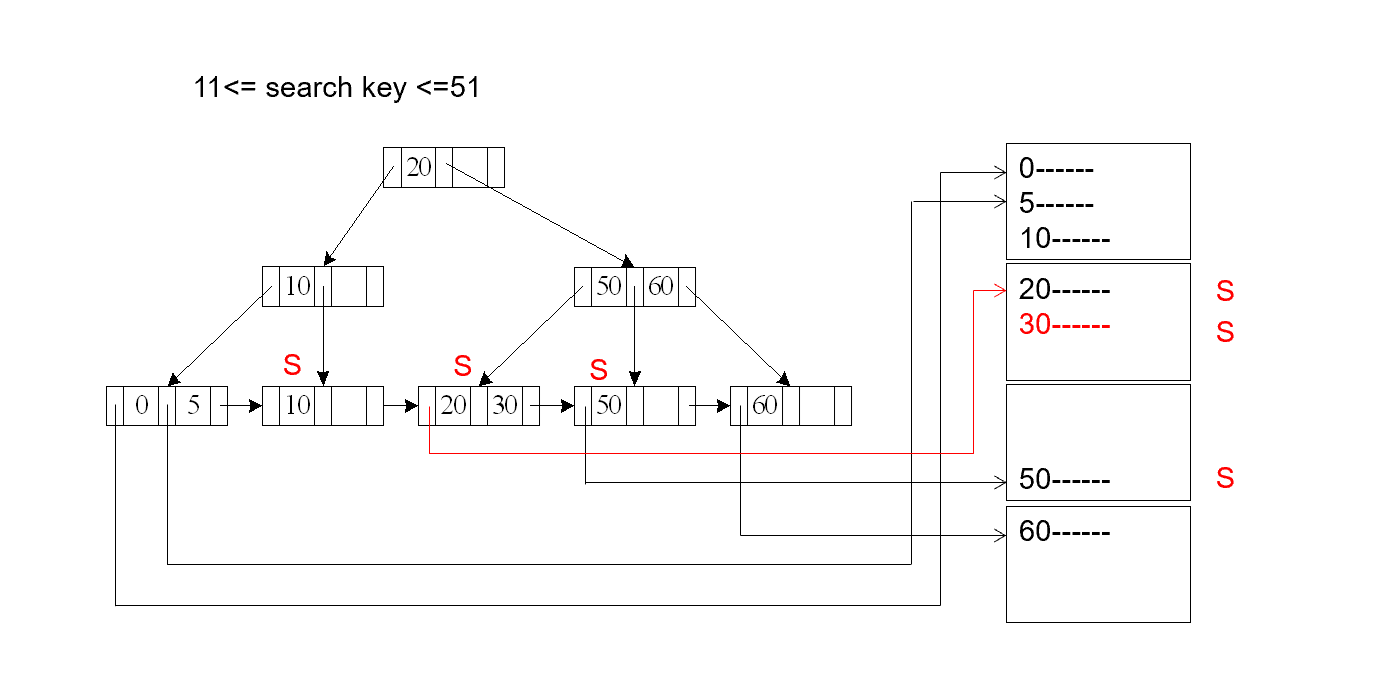
先在叶子页加锁,再在记录上加锁。
Index-locking protocol to prevent phantoms required locking entire leaf 索引锁协议为了防止幽灵问题需要将符合条件的整个叶子锁起来,会降低并发度(缺点)
如果我们要插入,比如 18. 这时插入到了 10 这页,发现这页被锁住了,无法插入,这样就确保了这个范围内无法被插入,不会有幽灵问题。
也可以使用谓词锁。把这个位置锁上(比如刚刚 11 到 50 这个区间),后续如果要插入 18 落入这个区间,我们就能检查出来。但这样实现是比较复杂的。
14.4.2 Next-Key Locking To Prevent Phantoms¶
Index-locking protocol to prevent phantoms required locking entire leaf 索引锁协议为了防止幽灵问题需要将符合条件的整个叶子锁起来,会降低并发度(缺点)
刚刚的例子中, 10 不在范围内,但我们把这页都锁住了,仍然插不进去,影响了并发度。
Next-key locking protocol: provides higher concurrency
-
Lock all values that satisfy index lookup (match lookup value, or fall in lookup range)
锁定所有满足索引查找的值(匹配查找值,或落在查找范围内)
-
Also lock next key value in index
同时锁定索引中的下一个键值even for inserts/deletes
-
Lock mode: S for lookups, X for insert/delete/update
锁定模式:S 用于查找,X 用于插入/删除/更新
Next-Key Locking
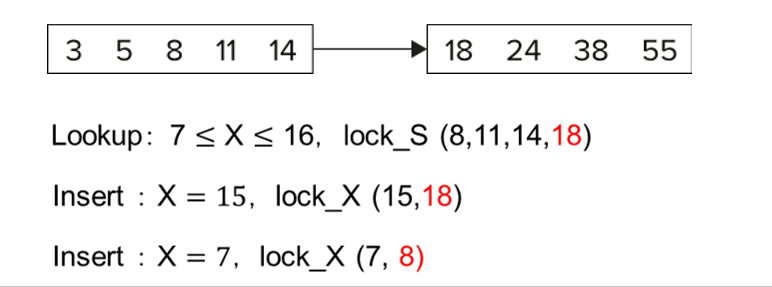
查询 7 到 16, 我们把索引项锁起来,把下一个索引值 18 也锁起来。
插入的时候要申请这个锁和比插入值大的下一个值的锁,这里插入 15 时就要申请 15 和 18 的锁,冲突无法插入。插入 7 同理。
14.5 Multiversion Concurrency Control Schemes¶
Multiversion schemes keep old versions of data item to increase concurrency.
多版本方案保留旧版本的数据项以增加并发性。
Each successful write results in the creation of a new version of the data item written.
每次成功写入都会创建写入的数据项的新版本。
Use timestamps to label versions.
使用时间戳标记版本。
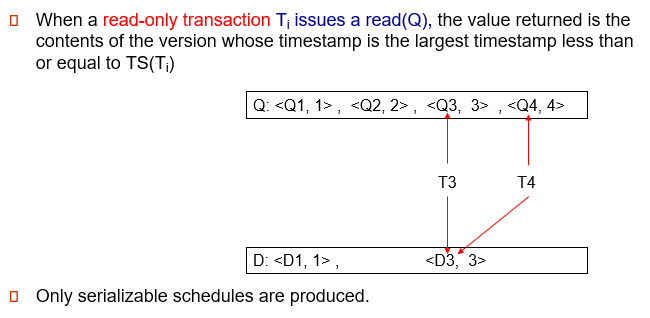
When a read(Q) operation is issued, select an appropriate version of Q based on the timestamp of the transaction, and return the value of the selected version.
发出 read(Q) 操作时,根据事务的时间戳选择适当的 Q 版本,并返回所选版本的值。
Read only transactions never have to wait as an appropriate version is returned immediately for every read operation..
只读事务永远不必等待,因为每次读取操作都会立即返回适当的版本。
read-only transactions and update transactions
SET TRANSACTIOIN READ ONLY;
SET TRANSACTION READ WRITE;(
update操作既需要read也需要write)
-
更新事务的操作:
申请read and write锁,遵守强两阶段封锁协议,所有的S锁和X锁需要在事务即将commit或者abort的时候才能释放。每次成功写入后会创建一个新的版本号,对应的时间戳为正无穷(防止读取脏数据),知道commit的时候,时间戳变为最新版本号+1
Each version of a data item has a single timestamp whose value is obtained from a counter ts-counter that is incremented during commit processing.
数据项的每个版本都有一个时间戳,其值是从在提交处理期间
递增的计数器 ts计数器中获取的。
-
只读事务的操作
在开始执行之前,通过读取 ts-counter 的当前值来分配时间戳。
当只读事务 \(T_i\) 发出 read(Q) 时,返回的值是时间戳为小于或等于 TS(\(T_i\)) 的最大时间戳的版本的内容
创建多个版本会增加存储开销
额外元组
每个元组中都有额外的空间用于存储版本信息
过时的版本应该被垃圾回收在时间戳小于或等于系统中最早的只读事务时间戳的所有版本中,保留最年轻的版本 \(Qk\),其他所有早于 \(Qk\) 的版本都可以删除。
