三. Introduction to SQL¶
约 10289 个字 496 行代码 预计阅读时间 58 分钟
3.1 Data Definition¶
3.1.1 Domain Types in SQL¶
-
char(n).Fixed length character string, with user-specified length n.定长字符串. C 语言里字符串结尾有
\0, 但数据库里没有,长度由定义而得。 -
varchar(n).Variable length character strings, with user-specified maximum length n. 不定长字符串。不同的数据类型比较可能有问题(比如定长和不定长的字符串)设定一个最长的长度,小于则按真实长度存储
-
int.Integer (a finite subset of the integers that is machine-dependent). -
smallint.Small integer (a machine-dependent subset of the integer domain type). -
numeric(p,d).Fixed point number, with user-specified precision of p digits, with d digits to the right of decimal point.p 表示有效数字位数, d 表示小数点后多少位。 e.g.
numeric(3,1)allows 44.5 to be store exactly, but neither 444.5 or 0.32 -
real, double precision.Floating point and double-precision floating point numbers, with machine-dependent precision. -
float(n).Floating point number, with user-specified precision of at least n digits.
3.1.2 Built-in Data Types in SQL¶
系统自带的数据类型
- date: Dates, containing a (4 digit) year, month and date
e.g. date ‘2005-7-27’ 日期(年月日) - time: Time of day, in hours, minutes and seconds. e.g. time ‘09:00:30’ time ‘09:00:30.75’ 时间(时分秒)
- timestamp: date plus time of day e.g. timestamp ‘2005-7-27 09:00:30.75’ 日期+时间
- interval: period of time
e.g. interval ‘1’ day
- Subtracting a date/time/timestamp value from another gives an interval value.
- Interval values can be added to date/time/timestamp values
- built-in date, time functions:
current_date(), current_time(), year(x), month(x), day(x), hour(x), minute(x), second(x)

3.1.3 Create Table Construct¶
An SQL relation is defined using the create table command:
create table r (A1 D1, A2 D2, ..., An Dn, (integrity-constraint_1),
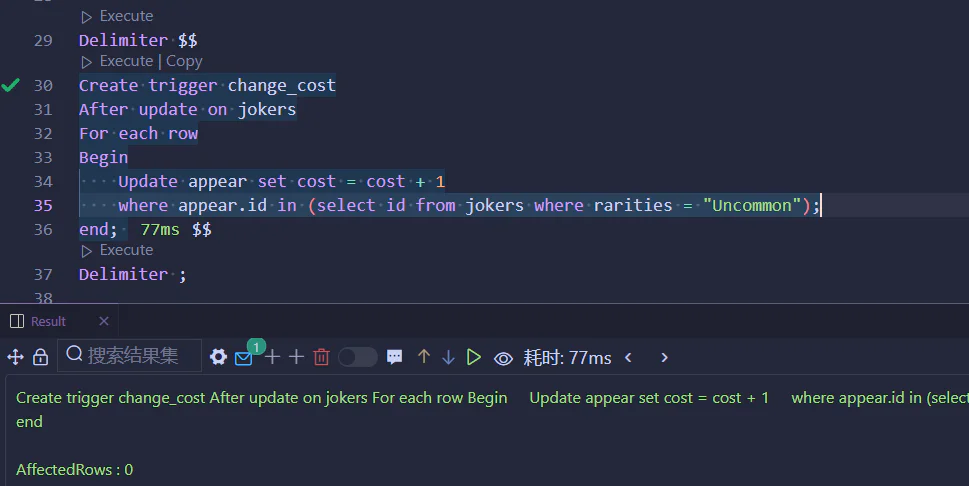
..,
(integrity-constraint_k))
create table instructor(
ID char(5),
name varchar(20),not null,
dept_name varchar(20),
salary numeric(8,2),
primary key(ID),
foreign key(dept_name)reference department
);
- \(r\) is the name of the relation
- each \(Ai\) is an attribute name in the schema of relation \(r\)
- \(Di\) is the data type of values in the domain of attribute \(Ai\)

Integrity Constraints in Create Table 完整性约束
-
not null 要求插入的数据非空 -
primary key \((A_1,\ldots,A_n)\)
不能为空; 表内不能有相同的 keys. 否则这样的数据是插入不进去的。
-
foreign key \((A_m,\ldots,A_n)\) references r
隐含:引用对应表的主键。
如果不符合完整性约束条件,插入可能会失败。

dept_name 指向department表中的Primary key。在instructor表中所有的dept_name的值,都要存在与department这个表的dept_name列中

缺省值default。如果插入学生的时候,没有给tot_cred一个给定的值,那么该值为default给定的值。

sec_idcan be dropped from primary key above, to ensure a student cannot be registered for two sections of the same course in the same semestersec_id 可以从上面的主键中删除,以确保学生不能在同一学期上同一门课程的两个班级
如果引用的表中有条目被删除,可能会破坏完整性约束条件。有下面的方法:
-
restrict: 如果有条目是被引用的,那么不允许删除。
-
cascade: 引用的条目被删了之后,引用者也一并删除
-
set null: 引用者的指针设为
null.如果即将要被置为null的元素,在完整性约束条件下已经被约束为“not null“,这样做就是不合法的。
-
set default : 引用者的指针设为默认值
如果引用的表中有更新,也有类似上面的四种方法。
在 create table 中定义
-
on delete cascade |set null |restrict |set default被引用的表发生删除
cascade可能会造成连锁反应,多次foreign key 引用
-
on update cascade |set null |restrict |set default被引用的表发生更改
实现方式:在create table中完成完整性约束定义

3.1.4 Drop and Alter Table Constructs¶
删除和更改表的结构
-
drop table student Deletes the table and its contents
把内容和表全删了,之后不能再往表里插入。表都没了
-
delete from student
Deletes all contents of table, but retains table
删除表的所有内容,但保留表
-
alter table
可以用于更改表中的列(添加或者删除)
-
alter table r add A D-
where A is the name of the attribute to be added to relation r and D is the domain of A.
A 是属性, D是A的域
e.g.
alter table student add resume varchar(256); -
All tuples in the relation are assigned null as the value for the new attribute.
对于新添加的列,所有的元素都设为NULL
-
还可以增加外键约束条件,也可以删掉
-
-
alter table r drop A-
where A is the name of an attribute of relation r
-
Dropping of attributes not supported by many databases
可以生成一个新的表,然后把除了要删的列以外的列搬移过去。
-
"关系数据库的三层抽象"
- 用户层:由 DML 定义操作, 如
select语句。 - 逻辑层:由
create table决定,我们定义了表的元素,以及各种键,构成了模式图。
3.2 Basic Query Structure¶
3.2.1 The select Clause¶
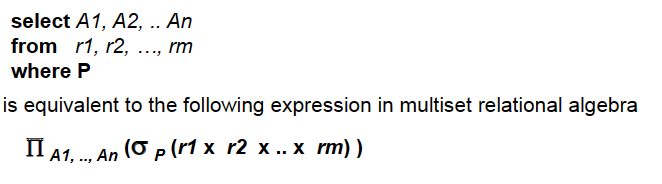
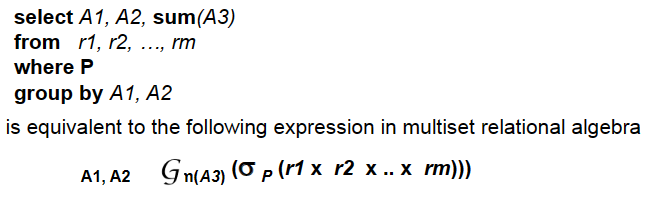
The select clause list the attributes desired in the result of a query.
SQL names are case insensitive 大小写不敏感。(属性名字、表的名字等)
-
To force the elimination of duplicates, insert the keyword
distinctafter select.e.g.
select distinct dept_name from instructor加 distinct能够去重
可以加 all 表示不去重,
加不加无所谓 -
An asterisk in the select clause denotes “all attributes”
e.g.select * from instructor -
The select clause can contain arithmetic expressions involving the operation, +, –, \(\div\), and /, and operating on constants or attributes of tuples.
可以有加减乘除运算 e.g.
select ID, name, salary/12 from instructor
3.2.2 The where Clause¶
The where clause specifies conditions that the result must satisfy.
该 where 子句指定结果必须满足的条件。
Corresponds to the selection predicate of the relational algebra.
-
SQL includes a
betweencomparison operator -
Tuple comparison
元组相等等价于各个元素都相等。
select name
from instructor
where salary between 90000 and 100000
select name, course_id
from instructor, teaches
where (instructor.ID, dept_name)=(teaches.ID, ’Biology’)
3.2.3 The from clause¶
The from clause lists the relations involved in the query.
Corresponds to the Cartesian product operation of the relational algebra.
from 多个 table 表示 笛卡尔积
3.2.4 Natural Join¶
e.g. select * from instructor natural join teaches;
select name, course_id
from instructor, teaches
where instructor.ID = teaches.ID;
select name, course_id
from instructor natural join teaches;
上面两条语句是等价的。
自然联接将所有公共属性的元组与相同值进行匹配,并且仅保留每个公共列的一个副本
natural join 可以使用 using 规定匹配的是哪个公共属性
course(course_id,title, dept_name,credits),
teaches(ID, course_id,sec_id,semester, year),
instructor(ID, name, dept_name,salary)
这里的 department 含义各有不同,不能直接自然连接。
instructor dept_name 表示老师所在的系
course dept_name 表示开课的系
可以写成 `` 即规定连接的属性,对应于 \(\sigma_\theta\)
select title, name
from (instructor natural join teaches) join course using(course_id);
select title, name
from instructor, teaches, course
where instructor.id teaches.id
adn teaches.course_id = course.course_id;
Find students who takes courses across his/her department.
寻找跨系选课
student(id, name, dept_name, tot_cred)
takes(id, course_id, sec_id, semester, year, grade)
course(course_id, title, dept_name, credits)
select distinct student.id
from (student natural join takes)
join course using (course_id)
where student.dept_name <> course.dept_name
请注意此处,第二个是使用join,附带条件使用course_id,这是因为第一处natural join之后得到的表,与course表的共有属性有course_id, dept_name。而我们要找的是dept_name不同的,所以不能使用natural join

3.2.5 The Rename Operation¶
The SQL allows renaming relations and attributes using the as clause.
old-name as new-name
select ID, salary/12 as monthly_salary
from instructor
select distinct T. name
from instructor as T, instructor as S
where T.salary > S.salary and S.dept_name = ‘Comp. Sci.’`
-
Keyword
asis optional and may be omitted.as可以省略
3.2.6 String Operations¶
SQL includes a string-matching operator for comparisons on character strings. The operator like uses patterns that are described using two special characters.
注意单引号表示字符串。
-
percent (%). The % character matches any substring.
e.g.
select name from instructor where name like '%dar%';找名字里面含有
dar的字符串。 -
underscore (_). The _ character matches any character.
匹配字符串
'100 %'但是%符号被我们作为了通配符,这里我们需要用到转义符\.\%即将%作为正常字符匹配。\也可以是一个基本符号,我们需要在后面写出escape表示其在这里作为转义符。类似地我们还可以将转义符定义为#.
like ‘100 \%' escape '\'
like ‘100 #%' escape ‘#'
SQL supports a variety of string operations such as
- concatenation (using
||) - converting from upper to lower case (and vice versa)
- finding string length, extracting substrings, etc.

3.2.7 Ordering the Display of Tuples¶
关系是无序的,但我们可能规定显示出来的顺序。
-
We may specify desc for descending order or asc for ascending order, for each attribute; ascending order is the default.
desc——descending 降序, asc——ascendin 升序。不指定默认升序
e.g.
order by name desc可以排序的类型,如字符串、数字。 -
Can sort on multiple attributes
e.g.
order by dept_name, name先按第一个排,如果第一个元素相同再按第二个排。
3.2.8 The limit Clause¶
The limit clause can be used to constrain the number of rows returned by the select statement.
限制 select 语句返回的行数。
limit clause takes one or two numeric arguments, which must both be nonnegative integer constants:
limit 子句采用一个或两个数值参数,这两个参数都必须是非负整数常量:
-
limit offset, row_count表示从下标为offset的地方开始,保留row_count个
-
limit row_count == limit 0, row_count
select name
from instructor
order by salary desc
limit 3; // limit 0,3
3.2.9 Set Operations¶
union, intersect, except 是严格的集合操作,会对结果去重.
- 如果不想去除重复的元素,可以使用
union all,intersect allandexcept all. 保持多重集。
3.2.10 Null Values¶
null signifies an unknown value or that a value does not exist.
-
The result of any arithmetic expression involving null is null.
任何涉及 null 的算术表达式的结果都是 null。
e.g.
5 + nullreturns null -
The predicate
is nullcan be used to check for null values.谓词 is null 可用于检查 null 值。
e.g. Find all instructors whose salary is null.
select name from instructor where salary is null -
Comparisons with null values return the special truth value: unknown.

- Result of select predicate is treated as false if it evaluates to unknown
3.2.11 Aggregate Functions¶
聚合函数:常见的包括:avg,min,max,sum,count
# Find the average salary of instructors in the Computer Science department
select avg(salary)
from instructor
wher dept_name = "Comp.Sci"
# Find the total number of instructors who teach a course in the Spring 2010 semester
select count (distinct ID)
from teaches
where semester = ’Spring’ and year = 2010
# Find the number of tuples in the course relation
select count (*)
from course;
在select挑选出来的属性中,除了聚合函数计算得到的属性以外,其余的属性必须在分组属性group by后面出现
/* erroneous query */
select dept_name, ID, avg (salary)
from instructor
group by dept_name;
# 此处的ID不合规
3.2.11.1 Having Clause¶
对分组后的组进行筛选。
select dept_name, count (*) as cnt
from instructor
where salary >=100000
group by dept_name
having count (*) > 10
order by cnt;
# 先对每个系中工资大于100000的选出来,再计算数量,再按照数量将cnt > 10 留下来, 最后按照cnt 排序
select dept_name
from student
group by dept_name
having count(distinct name) = count(distinct id)
# 找出没有重名学生的系
select dept_name
from student
group by dept_name
having 1-count(distinct name)/count(distinct id) < 0.001
# 找出重名率小于0.001 的系得名字
关于having 和 where的区别
predicates in the having clause are applied after the formation of groups whereas predicates in the where clause are applied before forming groups.
having是在分组之后,对分好的组进行筛选
where是在分组之前,对表中的行进行筛选,筛掉的行不参与分组
3.2.11.2 Null Values and Aggregates¶
select sum (salary) from instructor
-
Above statement ignores null amounts
-
Result is null if there is no non-null amount
如果没有非 null 金额,则结果为 null
-
All aggregate operations except
count(*)ignore tuples with null values on the aggregated attributes
如果使用count(*),输出的是非空值的个数
3.2.12 Nested Subqueries¶
A subquery is a select-from-where expression that is nested within another query.
Set Membership¶
in, not in
in 是 集合成员的判断
# Find courses offered in Fall 2009 and in Spring 2010
select distinct course_id
from section
where semester = ’Fall’ and year= 2009 and
course_id in (select course_id
from section
where semester = ’Spring’ and year= 2010);
# Find courses offered in Fall 2009 but not in Spring 2010
select distinct course_id
from section
where semester = ’Fall’ and year= 2009 and
course_id not in (select course_id
from section
where semester = ’Spring’ and year= 2010);
in或not in语句也可以判断一个元组是否在给定表的行当中:
# Find the total number of (distinct) students who have taken course sections taught by the instructor with ID 10101
select count (distinct ID)
from takes
where (course_id, sec_id, semester, year) in
(select course_id, sec_id, semester, year
from teaches
where teaches.ID= ‘10101’);
Set Comparison¶
some某些成员all所有成员
工资大于生物系中的某些老师的老师.
select name
from instructor
where salary > some (select salary
from instructor
where dept_name = ’Biology’);
select name
from instructor
where salary > all (select salary
from instructor
where dept_name = ’Biology’);
Scalar Subquery¶
Scalar (标量) subquery is one which is used where a single value is expected.
此处由于department.dept_name 定下来了,所以budget也唯一确定,保证了嵌套查询的子查询中仅仅返回一个数值。
如果不能保证子查询返回的值只有一个,需要使用some或者all
select name
from instructor
where salary * 10 >
(select budget
from department
where department.dept_name = instructor.dept_name)
```
这里 `dept_name` 是这个表的主键,只返回一个元组,这种情况下是可以不用 `some, all` 的。
Runtime error if subquery returns more than one result tuple.
Test for Empty Relations¶
The exists construct returns the value true if the argument subquery is nonempty.
exists r\(\Leftrightarrow r \neq \emptyset\)not exists r\(\Leftrightarrow r = \emptyset\)
select course_id
from section as S
where semester = ’Fall’ and year= 2009 and
exists (select *
from section as T
where semester = ’Spring’ and year= 2010
and S.course_id= T.course_id);
只要不空,存在就是True
# Find all students who have taken all courses offered in the Biology department.
# SQL 语句往往需要逆向考虑,即找到这样的学生,不存在他没选过的生物系的课。
select distinct S.ID, S.name
from student as S
where not exists ( (select course_id
from course
where dept_name = ’Biology’)
except
(select T.course_id
from takes as T
where S.ID = T.ID));
不存在学生没选过的生物课。
也就是让生物系所有的课程id 减去 这位同学上过的所有课的id,只要最后的集合为空,那么表明这个学生上过生物系中所有的课程。
exist 和 in/not in 的区别
exist 测试的是,后面的集合是否为空,只要不为空就返回true
in/not in, 前置会有一个属性,需要检测前置的属性是否在后面的集合中
Test for Absence of Duplicate Tuples¶
The unique construct tests whether a subquery has any duplicate tuples in its result.
验证是否是一个集合,而非多重集。
-
Evaluates to “true” on an empty set.
可以将 unique 理解为 at most once.
只要unique后面跟的括号中的子查询返回的结果没有重复的元素,返回值就是True。
如果返回值为空,unique仍然为True例如下方,假设选择出的课程在2009年没有开过,那么unique后面跟着的子查询返回的结果为null,也同样没有重复的元素,因此结果也是True
# Find all courses that were offered at most once in 2009 select T.course_id from course as T where unique (select R.course_id from section as R where T.course_id= R.course_id and R.year = 2009) ;
如果想要查询在2009年恰好开过一次的课程,需要同时使用unique和exist
select T.course_id
from course as T
where exist(select R.course_id
from section as R
where R.course_id = T.course_id
and R.year = 2009)
and unique(select R.course_id
from section as R
where R.course_id = T.course_id
and R.year = 2009)
-- exist 和 in 可以等价替换
select T.course_id
from course as T
where course_id in (select R.course_id
from section as R
where R.course_id = T.course_id
and R.year = 2009)
and unique(select R.course_id
from section as R
where R.course_id = T.course_id
and R.year = 2009)
如果不加 exist, 可能有没开过的课也被算进去。我们这里求得是恰好只开过一次的。

也可以用 group by count(*) <= 1 实现。
3.2.13 With Clause¶
The with clause provides a way of defining a temporary view whose definition is available only to the query in which the with clause occurs.
with 子句提供了一种定义临时视图的方法,该临时视图的定义仅适用于出现 with 子句的查询。
# Find all departments with the maximum budget.
with max_budget (value) as
(select max(budget)
from department)
# max_budget 是 临时表的名字, value是表中的属性
select dept_name
from department, max_budget
where department.budget = max_budget.value;
select dept_name
from department
where budget = (select max(budget)
from department)
# 查找总工资大于所有部门总工资平均值的所有部门
with dept_total (dept_name, value) as
(select dept_name, sum(salary)
from instructor
group by dept_name),
dept_total_avg(value) as
(select avg(value)
from dept_total)
select dept_name
from dept_total, dept_total_avg
where dept_total.value >= dept_total_avg.value;
3.2.14 Modification of the Database¶
Deletion¶

delete from instructor
where salary < (select avg(salary) from instructor)
// First, compute avg salary and find all tuples to delete
// Next, delete all tuples found above (without recomputing avg or retesting the tuples)
Insertion¶

第二种写法,可以不用严格按照定义的元素顺序,只要和自己写的对应即可。
除了基本写法,我们还可以在
insert后跟查询语句,把查询结果插入到表里去。

insert into table
select * from tabel
// 如果没有primary key,则所有元素重复一次
// 否则,出现错误,重复
Updates¶
update ... set ... 
此处强调顺序,如果对工资小于100000的,先进行×1.05的操作,将会导致运算后的工资大于100000,再×1.03,造成重复计算
order is important,否则会多次运算进阶: 使用 case 语句

// 计算总学分且要求该门课的成绩不是F
update student S
set tot_cred = ( select sum(credits)
from takes natural join course
where S.ID= takes.ID and
takes.grade <> ’F’ and
takes.grade is not null);
四. Intermediate SQL¶
中级SQL语言
4.1 Joined Relations¶
-
Join operations take two relations and return as a result another relation.
连接操作采用两个关系,并返回另一个关系。
-
Join operations are typically used as subquery expressions in the from clause
连接操作通常用作 from 子句中的子查询表达式
-
Join condition – defines which tuples in the two relations match, and what attributes are present in the result of the join.
连接条件 – 定义两个关系中的哪些元组匹配,以及连接结果中存在哪些属性。
-
Join type – defines how tuples in each relation that do not match any tuple in the other relation (based on the join condition) are treated.

- using 是一个等值连接,类似于自然连接,这些属性相同才能连接
table a natural join table b
自然连接,所有的共有属性
table a join table b on 某个条件
条件连接,仅保留满足条件的tuple
table a join table b using some attribute
等值连接,仅仅提到的共有属性
natural join 包括 natural left outer join, natural right outer join, natural full outer join
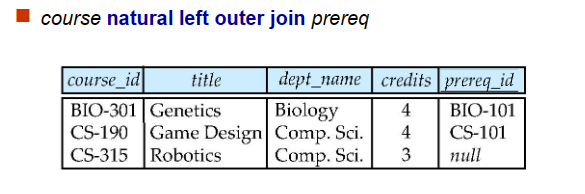
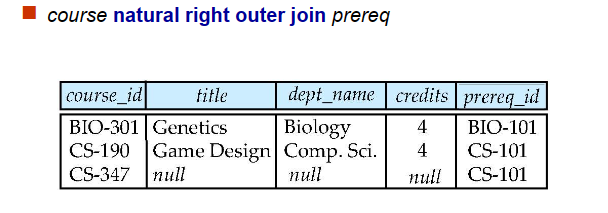

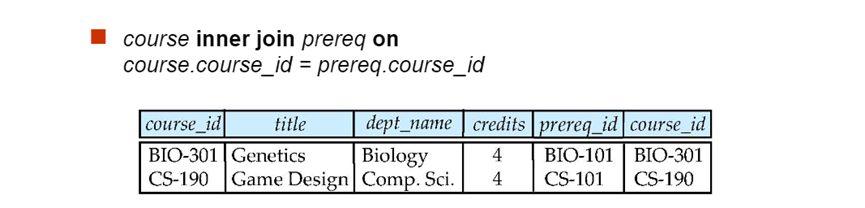
只对on后面的条件说明的属性做条件连接,其他不满足条件的tuple全部舍弃
4.2 SQL Data Types and Schemas¶
4.2.1 User-Defined Types¶
自定义数据类型
create type construct in SQL creates user-defined type.
create type Dollars as numeric (12,2) final
定义了 Dollars 这个类型后,我们就可以把它当作元类型使用。
create table department
(dept_name varchar (20),
building varchar (15),
budget Dollars);
这样可以支持强类型检查,可以防止如 200 美元 + 300 RMB 得到 500 元的错误。
4.2.2 Domains¶
create domain construct in SQL-92 creates user-defined domain types.
自定义值域
Domains can have
constraints(约束), such asnot null, specified on them.
create domain person_name char(20) not null
create domain degree_level varchar(10)
constraint degree_level_test
check (value in (’Bachelors’, ’Masters’, ’Doctorate’));
这里的 constraint 可以对 domain 的取值进行限制。
不同 type 的变量,即使定义相同,也不能进行运算。不同 domain 的变量(基础类型相同)可以运算。
4.2.3 Large-Object Types¶
大对象类型
Large objects (photos, videos, CAD files, etc.) are stored as a large object:
-
blob:
binary large object-- object is a large collection of uninterpreted binary data (whose interpretation is left to an application outside of the database system)二进制大型对象 -- 对象是大量未解释的二进制数据
存储大对象数据类型,实际上只是存放指针。
Example "BLOB in MySQL"
- TinyBlob : 0 ~ 255 bytes.
- Blob: 0 ~ 64K bytes.
- MediumBlob : 0 ~ 16M bytes.
- LargeBlob : 0 ~ 4G bytes.
-
clob: character large object -- object is a large collection of character data
字符大对象 -- 对象是字符数据的大型集合
对于大对象类型。当查询操作返回一个大对象类型的结果时,将会返回大对象的指针,而不是大对象本身
4.3 Integrity Constraints¶
-
not null -
primary key -
uniqueunique(A1, A2, ..., Am)The unique specification states that the attributesA1, A2, ..., Amform a super key (不一定是 candidate key)unique 后面用括号括起来的属性组合,表明这些属性的组合能够唯一确定一个元组。构成一个super key,不一定是最小的主键。
回忆一下什么是super key, 什么是 candidate key?
super key : super key 能够唯一确定tuple,但是具有冗余性
candidate key : candidate key 是最小的super ky
primary key : candidate key 中的一种
比如学生个人信息,我们知道 ID 是主键,但实际上邮箱、电话号码等也不能相同的,所以我们要通过语句告诉数据库,数据库会为我们维护这些约束条件。
Candidate keys are permitted to be null (in contrast to primary keys).
候选键允许为 null(与主键相反)。
-
check (P), where P is a predicate检验条件,元组的值需要满足约束条件

-
foreign key"Integrity Constraint Violation During Transactions"

在一个人的父母还没插入的时候,无法插入这个人,依次类推。
可以规定,在这个事务结束时再检查完整性约束条件,中间状态可以不满足。
-
assertion(尚未实现)create assertion <assertion-name> check <predicate>;

不存在一个学生的总学分不等于他的学分总和,双重否定
验证一个学生获得的总学分,要等于获得的每门课的学分的总和。
但使用
assert后,每个元组的每次状态更新时都要进行检查,开销过大,数据库一般不支持。
注意:以上条件一般只能用于create table阶段,单独使用
4.4 Views¶
A view provides a mechanism to hide certain data from the view of certain users.
视图提供了一种机制,用于从某些用户的视图中隐藏某些数据。
4.4.1 View Definition¶
A view is defined using the create view statement which has the form create view v as < query expression >
-- a view of instructor without their salary(学院)
create view faculty as
select ID, name, dept_name
from instructor;
-- Find the name of all instructor in the Biology department
select name
from faculty
where dept_name = 'Biology'
-- create a view of department salary total
create view department_total_salary(dept_name, total_salery) as
select dept_name, sum(salary)
from instructor
group by dept_name
create view
(attribute_name) as select …..
在创建view之后,如果view名字后面没有添加属性的名字,就按照select语句的属性名来
view 可以隐掉一些细节,或者加上一些统计数据。可以把 view 当作表进行查询。
- 隐藏不必要的细节,简化用户视野
- 方便查询书写
- 有利于权限控制(如用户可以看到工资总和,但不能看到每个人的工资)
- 有独立性,使得数据库应用具有较强的适应性。
可以基于视图再定义视图。Example "Views Defined Using Other Views"
```sql
create view physics_fall_2009 as
select course.course_id, sec_id, building, room_number
from course,section
where course.course_id = section.course_id
and course.dept_name = 'Physics'
and section.semester = 'Fall'
and section.year = '2009'
create view physics_fall_2009_watson as
select course_id, room_number
from physics_fall_2009
where building = "Waston"
```
基于视图再定义视图的执行方式
select course_id, room_number
from physics_fall_2009
where building = 'Waston'
->
select course_id, room_number
from(select course.course_id, building, room_number
from course, section
where course.course_id = section.course_id
and course.dept_name = ’Physics’
and section.semester = ’Fall’
and section.year = ’2009’)
where building= ’Watson’;
->
select course_id, room_number
from course, section
where course.course_id = section.course_id
and course.dept_name = ’Physics’
and section.semester = ’Fall’
and section.year = ’2009’
and building= ’Watson’;
4.4.2 Update of a View¶
对一个 view 进行修改,相当于通过这个窗口对原表继续修改。
-- add a new tuple to faculty view
create view faculty as
select ID, name, dept_name
from instructor
insert into faculty values(......)
向view中插入一行,相当于向实际的表中插入一行,缺失的属性填写null。但如果实际的表中对应属性有完整性约束not null,则无法插入这一行。
如果视图中有统计的属性,那么是不可修改的,聚合函数部分涉及到计算,不能直接插入数据。同理不能使用distinct,group by, having clause
涉及到单个表,只是选出了部分属性(去掉非主属性)的行列视图是可更新的。
4.4.3 *Materialized Views¶
物化视图
Materializing a view: create a physical table containing all the tuples in the result of the query defining the view.
物化视图:创建一个物理表,其中包含定义视图的查询结果中的所有元组。
本来的视图是一个虚的表,为了查询执行效率,我们可以把 view 定义为 Materializing view, 即生成一张临时表与其对应。
If relations used in the query are updated, the materialized view result becomes out of date.
如果更新了查询中使用的关系,则实例化视图结果将过期。
这是因为此时物化视图与原表之间是两个存在,不存在联系
-
Need to maintain the view, by updating the view whenever the underlying relations are updated.
需要维护视图,每当基础关系更新时,都会更新视图。

4.4.4 View and Logical Data Indepencence¶
If relation \(S(a, b, c)\) is split into two sub relations \(S1(a,b)\) and \(S2(a,c)\)
How to realize the logical data independence(逻辑独立性)?
- create table \(S1\)...;
create table \(S2\)...; - insert into \(S1\) select a, b from S;
insert into \(S2\) select a, c from S; - drop table S;
- create view S(a, b, c) as select a, b, c from \(S1\) natural join \(S2\);`
select * from S where... 实际上是在做 select * from S1 natural join S2 where ... (系统会帮我这样做,程序不用改,只是执行改变了)
insert into S values (1,2,3) 实际上是在做 insert into S1 values (1,2) 和 insert into S2 values (1,3)
delete 同理
4.5 Indexes¶
Indices are data structures used to speed up access to records with specified values for index attributes.
Index 相当于在数据上建立了 B+ 树索引。(物理层面)
create table student
(
ID varchar (5),
name varchar (20) not null,
dept_name varchar (20),
tot_cred numeric (3,0) default 0,
primary key (ID)
)
create index studentID_index on student(ID)
select *
from student
where ID = ‘12345
-- can be executed by using the index to find the required record, without looking at all records of student
在数据库内不同的物理实现有不同的查找方法。
如果没有定义索引,只能顺序查找。
如果有索引,系统内会利用索引查找。
4.6 Transactions(事务)¶
原子事务:要么完全被执行,要么向从未发生过一样回退。
并发事务具有相关性。例如银行转账,一个账户的钱减少,必然伴随另外一个账户钱增加。如果另一个账户的钱还没有增加的时候,就被打断,此时第一个账户的钱必须加回来,就像没有发生转账操作过一样。
-
Transactions begin implicitly 事务隐式开始
Ended by commit work or rollback work
-
By default on most databases: each SQL statement commits automatically
默认情况下,在大多数数据库上:每个 SQL 语句都会自动提交
- Can turn off auto commit for a session 关闭自动提交
e.g. in MySQL,
SET AUTOCOMMIT=0;SET AUTOCOMMIT = 0 UPDATE account SET balance=balance-100 WHERE ano=‘1001’; UPDATE account SET balance=balance+100 WHERE ano=‘1002’; COMMIT; UPDATE account SET balance=balance -200 WHERE ano=‘1003’; UPDATE account SET balance=balance+200 WHERE ano=‘1004’; COMMIT; UPDATE account SET balance=balance+balance*2.5%; COMMIT;commit或者rollback标志着事务的结束
如果没有commit,那么推出数据库重新进入,数据会恢复到没有改变的状态
火车票的预定和支付钱,是两个不同的事务,最后利用第三个事务退票来弥补预定事务
4.6.1 ACID Properties¶
A transaction is a unit of program execution that accesses and possibly updates various data items. To preserve the integrity of data the database system must ensure: (原子性、一致性、独立性、持续性)
-
Atomicity. Either all operations of the transaction are properly reflected in the database or none are.
要么同时进行,要么同时不进行
-
Consistency. Execution of a transaction in isolation preserves the consistency of the database.
数据库执行事务前后都是一致的。
-
Isolation. Although multiple transactions may execute concurrently, each transaction must be unaware of other concurrently executing transactions. Intermediate transaction results must be hidden from other concurrently executed transactions.
很多事情共同执行,他们不能互相影响,每个事务必须不知道其他并发执行的事务。。
- That is, for every pair of transactions \(T_i\) and \(T_j\), it appears to \(T_i\) that either \(T_j\), finished execution before \(T_i\) started, or \(T_j\) started execution after \(T_i\) finished.
-
Durability(持久性). After a transaction completes successfully, the changes it has made to the database persist, even if there are system failures.
数据库的事务一旦提交,这个修改就要持续地保存到数据库中去,不能丢失。如磁盘出问题了,断电了等会引发这个问题。
通常使用日志。
4.7 Authorization(授权)¶
-
Forms of authorization on parts of the database
对数据库各部分的授权形式
-
Select - allows reading, but not modification of data.
选择 - 允许读取数据,但不允许修改数据。
-
Insert - allows insertion of new data, but not modification of existing data.
插入 - 允许插入新数据,但不允许修改现有数据。
-
Update - allows modification, but not deletion of data.
更新 - 允许修改,但不允许删除数据。
-
Delete - allows deletion of data.
删除 - 允许删除数据。
-
-
Forms of authorization to modify the database schema
修改数据库schema的形式-
Index - allows creation and deletion of indices.
索引 - 允许创建和删除索引
-
Resources(create) - allows creation of new relations.
允许创建新关系
-
Drop - allows deletion of relations.
允许删除关系。
-
Alteration - allows addition or deletion of attributes in a relation.
允许在关系中添加或删除属性
-
create view
-
4.7.1 Authorization Specification in SQL¶
授权规范:
grant <privilege list>
on <relation name or view name>
to <user list>
把某个表或者视图上的权限授权给用户
<user list> is:
-
a user-id
-
public, which allows all valid users the privilege granted允许所有有效用户获得授予的权限
-
A role (more on this later)

精细化控制到某一列(update (budget))
update 可以细化到具体可以对哪列进行修改。
4.7.2 Revoking Authorization in SQL¶
回收权限
The revoke statement is used to revoke authorization.
revoke <privilege list>
on <relation name or view name>
from <user list>
revoke select on branch from U1,U2,U3
grant to——revoke from
4.7.3 Roles¶
角色role:角色可以看成是一组权限的集合
可以利用create role <role_name>来创造一个角色
可以将权力授予给某个角色grant select on takes to instructor
可以将角色授予给某个用户grant role_name to user
当然角色还能授予给其他角色,被授予的角色将继承授予角色的一切权力

create role instructor;
grant select on takes to instructor; -- 授予权限给角色
grant instructor to Amit; -- 将角色的权限授予给用户
-- 角色授予角色
create role teaching_assistant
grant teaching_assistant to instructor
-- instructor 将继承 teaching_assistant 所有的群里
-- 可以构造角色链
还可以将视图上的权力授予给某个用户
```sql
create view geo_instructor as
(select *
from instructor
where dept_name = ’Geology’);
grant select on geo_instructor to geo_staff
```
4.7.4 Other Authorization Features¶
引用的权限比较特殊
references privilege to create foreign key
grant reference (dept_name) on department to Mariano;

如果不作为权限,我们可以通过间接的外键约束和 cascade 删掉被引用的数据。(删掉饮用者,则被引用者也要被删除)因此这也是个权限
transfer of privileges 权限的传递
* grant select on department to Amit with grant option;
加上 `with grant option` 后,**用户可以把获得的权限传递下去。**
-
revoke select on department from Amit, Satoshi cascade;cascade把该用户及其授予的权限全部收回,级联反应。 -
revoke select on department from Amit, Satoshi restrict;restrict只收回该用户的权限,不产生级联反应 -
revoke grant option for select on department from Amit;收回Amit传递相应权限的权力,但没有收回Amit在表上查询的权力。

五. Advanced SQL¶
5.1 Accessing SQL from a Programming Language¶
-
并非所有查询都可以用 SQL 表示,因为 SQL 不提供通用语言的全部表达能力。
-
用户交互是图形界面,语音、图像,数据库不具备这方面的功能。
从高级语言(如 C)访问数据库,主要是下面两种方式:
-
API(Application Program Interface) -- A general-purpose program can connect to and communicate with a database server using a collection of functions.
API:用于程序与数据库服务器的交互
应用程序调用数据库的过程:
① 连接数据库服务器。
② 向数据库服务器发送SQL命令。
③ 将结果的元组一个一个提取到程序变量中。
-
Embedded SQL -- provides a means by which a program can interact with a database server.
嵌入式 SQL -- 提供程序与数据库服务器交互的方法。
- The SQL statements are translated at compile time into function calls.
SQL 语句在编译时转换为函数调用。
- At runtime, these function calls connect to the database using an API that provides dynamic SQL facilities.
在运行时,这些函数调用使用提供动态 SQL 工具的 API 连接到数据库。

5.1.1 JDBC and ODBC¶
API (application-program interface) for a program to interact with a database server
API(应用程序-程序接口),用于程序与数据库服务器交互
Application makes calls to
-
Connect with the database server
与数据库服务器连接
-
Send SQL commands to the database server
将 SQL 命令发送到数据库服务器
-
Fetch tuples of result one-by-one into program variables
将结果的元组逐个提取到程序变量中
SQL 与 C 语言存在鸿沟(如 select 得到的是集合,但是 C 语言没有这种类型)会返回指针/迭代器
-
ODBC
(Open Database Connectivity) works with C, C++, C#ODBC(开放式数据库连接)适用于 C、C++、C#
-
JDBC
(Java Database Connectivity) works with Java通过类定义,将数据库操作封装到 Java 内
-
Embedded SQL in C C语言中的嵌入式SQL
-
SQLJ - embedded SQL in Java Java语言中的嵌入式SQL
-
JPA(Java Persistence API) - OR mapping of Java
5.1.1.1 JDBC¶
JDBC is a Java API for communicating with database systems supporting SQL.
JDBC 是一个 Java API,用于与支持 SQL 的数据库系统进行通信。
public static void JDBCexample(String dbid, String userid, String passwd)
{
try {
Connection conn = DriverManager.getConnection("jdbc:oracle:thin:@db.yale.edu:2000:univdb", userid, passwd);
Statement stmt = conn.createStatement();
... Do Actual Work ...
stmt.close();
conn.close();
}
catch (SQLException sqle) {
System.out.println("SQLException : " + sqle);
}
}
-
Open a connection
上述程序中,Connection是一个类,conn是一个类中的对象,获得一个Java程序与数据库之间的连接。
-
Create a “statement” object
statement 也是一个类,stmt是一个类中的对象,程序真正要做的事情在Do Actual Work处
-
Execute queries using the Statement object to send queries and fetch results
做完后,要先将对象stmt关闭掉,再将对象conn关闭掉。
-
Exception mechanism to handle errors
try……catch语句是一种异常处理的机制,在try部分中所有的函数与方法的错误,都会抛出到catch中被捕获。
Update to database 更新数据库
Update to database
try
{
stmt.executeUpdate(
"insert into instructor values(’77987’, ’Kim’, ’Physics’, 98000)");
}
catch (SQLException sqle)
{
System.out.println("Could not insert tuple. " + sqle);
}
Execute query and fetch and print results 执行查询以及获取和打印结果
ResultSet rset = stmt.executeQuery(
"select dept_name, avg (salary)
from instructor
group by dept_name");
while (rset.next()) {
System.out.println(rset.getString("dept_name") + " " + rset.getFloat(2));
}
ResultSet 是一个类,里面有一个对象 rset,用来获得select的结果。
\(while(rset.next())\)循环中,指针最开始指向第一个元组的上一个,\(rset.next()\)让指针指向下一个元组。
rset.getstring(“dept_name”)表示拿到字符串类型的列名为dept_name的一个元素;
System.out.printin 是用来打印的函数
Getting result fields 获取结果字段
rset.getString(“dept_name”)
rset.getString(1)
两者等价如果dept_name是结果的第一个变量
Dealing with Null values 处理 Null 值
int a = rset.getInt(“a”);
if (rset.wasNull()) Systems.out.println(“Got null value”);
如果返回值是空的(rset.wasNull),那么就打印出一行:Got Null value。
Prepared Statement 预编译声明
PreparedStatement pStmt = conn.prepareStatement(
"insert into instructor values(?,?,?,?)");
pStmt.setString(1, "88877");
pStmt.setString(2, "Perry");
pStmt.setString(3, "Finance");
pStmt.setInt(4, 125000);
pStmt.executeUpdate();
pStmt.setString(1, "88878");
pStmt.executeUpdate();
这里问号是占位符,表示执行时需要提供四个参数。
setString, setInt就是把第几个占位符设置为参数,并executeUpdate进行插入。
预编译的时候开始留出占位符,在实际使用的时候,利用setString函数,直接在相应的位置上填入值。
pStmt.setString(1,“88877”)表示,给第一个参数的位置放上88877。
pStmt.executeUpdate()表示运行,插入四个参数。
Always use prepared statements when taking an input from the user and adding it to a query. NEVER create a query by concatenating strings which you get as inputs.
在从用户那里获取输入并将其添加到查询时,始终使用预准备语句。切勿通过连接作为输入获取的字符串来创建查询。
SQL Injection(SQL 注入攻击)
通过用户的输入来构造一条完整的SQL语句,可能会对数据库造成攻击
-
Suppose query is constructed using select * from instructor where name =
‘ ” + name + “ ’表示要求name =‘ ” + name + “ ’ -
Suppose the user, instead of entering a name, enters:
X’ or ’Y’ = ’Y
-
then the resulting string of the statement becomes:
select * from instructor where name = ’" + "X’ or ’Y’ = ’Y" + “’、 which is:select * from instructor where name = ’X’ or ’Y’ = ’Y’这样就会造成对Y选择出错
-
User could have even used X’; update instructor set salary = salary + 10000;
从而使字符串变为:
select * from instructor where name = ’X’;
update instructor set salary = salary + 10000;
这样就会造成,额外执行指令
解决方法:
Always use prepared statements, with user inputs as parameters
始终使用预处理语句,并将用户输入作为参数
Metadata Features
- finding all the relations in the database and 查找数据库中的所有关系,并
- finding the names and types of columns of a query result or a relation in the database. 查找数据库中查询结果或关系的列的名称和类型。
-
ResultSet metadata
after executing query to get a ResultSet rs:
在运行一条语句,得到了一个ResultSet类中的对象rs,
可以通过调用
rs.getMetaData()函数,来获取元数据。ResultSetMetaData rsmd = rs.getMetaData(); for(int i = 1; i <= rsmd.getColumnCount(); i++) { System.out.println(rsmd.getColumnName(i)); System.out.println(rsmd.getColumnTypeName(i)); }利用上述的代码,可以实现返回属性名和属性的类型(不知道有多少列,用getColumnCount())
getColumnCount()表示获取结果集合中列的数目;
getColumnName(i)表示获取第i列的列名;
getColumnTypeName(i)表示获取第i列的列类型。

这个的前提是,已知属性和类型,得到对应的数据
-
Database metadata
DatabaseMetaData dbmd = conn.getMetaData(); ResultSet rs = dbmd.getColumns(null, "univdb", "department", "%"); // Arguments to getColumns: Catalog, Schema-pattern, Table-pattern, // and Column-Pattern // Returns: One row for each column; row has a number of attributes // such as COLUMN_NAME, TYPE_NAME while( rs.next()) { System.out.println(rs.getString("COLUMN_NAME"), rs.getString("TYPE_NAME");dbmd.getColumns中,先是目录的名字(null),再是Schema的名字“univdb”,再是表的名字“department”,“%”表示返回这个表的全部列。最后将结果保存在类ResultSet的对象rs中。如果要遍历结果表中所有的行元组,仍然可以用
ResultSet类中rs对象的next()函数遍历:
前面我们获得的是ResultSet的元数据,这里我们获得的是数据库detabase的元数据
对于ResultSet的元数据,可以使用
ResultSetMetadata rsmd = rs.getMetadata获取。我们将得到,ResultSet所有的属性名和属性的类型对于Database的元数据,可以使用
ResultSet rs = dbmd.getColumns(目录名, 视图名, 表名, %)获取表的全部列保存在rs中,
Transaction Control in JDBC
JDBC 中的事务控制
- Can turn off automatic commit on a connection
conn.setAutoCommit(false); - Transactions must then be committed or rolled back explicitly
conn.commit();orconn.rollback(); conn.setAutoCommit(true)turns on automatic commit.
所有的数据库功能都是通过 Java 封装好的类来实现的。
5.1.1.2 SQLJ¶
SQLJ : embedded SQL in Java
#sql iterator deptInfoIter ( String dept name, int avgSal);
// 定义一个类
deptInfoIter iter = null;
// 类的实例
#sql iter = { select dept_name, avg(salary) as avgSal
from instructor
group by dept name };
while (iter.next()) {
String deptName = iter.dept_name();
int avgSal = iter.avgSal();
System.out.println(deptName + " " + avgSal);
}
iter.close();
#sql,最后会被编译器转化为 Java 的类。
5.1.1.3 ODBC¶
Open DataBase Connectivity
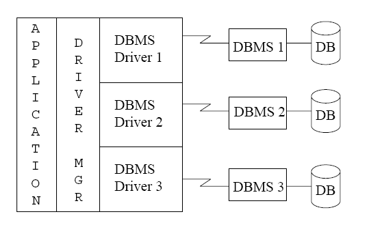
Each database system supporting ODBC provides a "driver" library that must be linked with the client program.
每个支持 ODBC 的数据库系统都提供了一个必须与客户端程序链接的“驱动程序”库
int ODBCexample()
{
RETCODE error;
HENV env; /* environment */
HDBC conn; /* database connection */
SQLAllocEnv(&env);
SQLAllocConnect(env, &conn);
// NTS null terminate string
SQLConnect(conn, “db.yale.edu", SQL_NTS, "avi", SQL_NTS, "avipasswd", SQL_NTS);
…. Do actual work …
SQLDisconnect(conn);
SQLFreeConnect(conn);
SQLFreeEnv(env);
}
首先,调用SQLAllocEnv(&env),获得一个环境。然后,调用SQLAllocConnect(env,&conn);在这个环境中,生成一个连接。
同一个数据库可能服务于多个用户,而且使用的编程语言可能不同,如字符串的结束标志可能也不同,因此需要用 SQL_NTS 标识。
SEL_NTS 表示 null terminate string,用null来终止字符串
当实际的工作做完以后,要将conn关闭掉、回收掉,要将env回收掉。
-
Program sends SQL commands to database by using
SQLExecDirect程序向数据库发送SQL指令
-
Result tuples are fetched using
SQLFetch()结果元组的获取方式
-
SQLBindCol()binds C language variables to attributes of the query result将 C 语言变量绑定到查询结果的属性
-
When a tuple is fetched, its attribute values are automatically stored in corresponding C variables.
当提取元组时,其属性值会自动存储在相应的 C 变量中。
-
Arguments to SQLBindCol()
SQLBindCol() 的参数
-
ODBC stmt variable, attribute position in query result
ODBC stmt 变量
-
The type conversion from SQL to C.
从 SQL 到 C 的类型转换
-
The address of the variable.
变量的地址
-
For variable-length types like character arrays,
-
The maximum length of the variable 变量的最大长度
-
Location to store actual length when a tuple is fetched.
获取元组时存储实际长度的位置
-
-
Note: A negative value returned for the length field indicates null value
当传入到C变量的值为空时,存储实际长度的位置置为-1
如果结果为空,则
lenOut为 -1.
char deptname[80];
float salary;
int lenOut1, lenOut2;
HSTMT stmt;
char * sqlquery = "select dept_name, sum (salary)
from instructor
group by dept_name";
// stmt statement
SQLAllocStmt(conn, &stmt);
error = SQLExecDirect(stmt, sqlquery, SQL_NTS);
if (error == SQL SUCCESS) {
// bindcol 绑定列
// 1 表示第一列, 80表示字符数组长度, &lenout1表示实际长度
SQLBindCol(stmt, 1, SQL_C_CHAR, deptname , 80, &lenOut1);
SQLBindCol(stmt, 2, SQL_C_FLOAT, &salary, 0 , &lenOut2);
while (SQLFetch(stmt) == SQL_SUCCESS) {
printf (" %s %g\n", deptname, salary);
}
}
SQLFreeStmt(stmt, SQL_DROP);
SQLAllocStmt(conn, &stmt)表示在conn这个连接中,分配一个代表语句的对象
SQLExecDirect用来执行sqlquery字符串表达的语句,其中的参数SQL_NTS表明,这个字符串是以‘\0’结尾结束的。SQLExecDirect的返回值保存在变量error中
如果error为SQL SUCCESS,表示上述语句已经执行成功了,返回的两列dept_name与sum(salary)已经存在了
然后,SQLBindCol函数将C语言的变量绑定到查询返回的结果。
-
SQLBindCol(stmt, 1, SQL_C_CHAR, deptname, 80, &lenOut1);
把语句stmt的第一列,传到变量deptname,变量deptname的最大长度是80,实际长度填写到 lenOut1中
-
SQLBindCol(stmt, 2, SQL_C_FLOAT, &salary, 0 , &lenOut2);
把语句stmt中的第二列,传到变量salary中,将变量salary的长度传到lenOut2中。
如果变量salary为空,那么lenOut2中置为-1,否则置为它实际的长度。
然后,利用SQLFetch函数,将返回结果stmt利用循环,将一行一行的元组依次抓取,如果抓取成功,那么就打印出这一行的deptname、salary的值。
ODBC Prepared Statements
预编译的时候可以留出占位符
-
SQL statement prepared: compiled at the database
-
To prepare a statement 准备声明
SQLPrepare(stmt, <SQL String>); -
To bind parameters 绑定参数
SQLBindParameter(stmt, <parameter#>, ... type information and value omitted for simplicity..) -
To execute the statement 执行语句
retcode = SQLExecute(stmt);
-
-
Can have placeholders(占位符): e.g.
insert into account values(?,?,?) -
Repeatedly executed with actual values for the placeholders

More ODBC Features
-
Metadata features
-
finding all the relations in the database and
查找数据库中的所有关系 (Database Metadata)
-
finding the names and types of columns of a query result or a relation in the database.
查找数据库中查询结果或关系的列的名称和类型 (ResultSet Metadata)
-
-
By default, each SQL statement is treated as a separate transaction that is committed automatically.
默认情况下,每个 SQL 语句都被视为自动提交的单独事务。
-
Can turn off automatic commit on a connection
SQLSetConnectOption(conn, SQL_AUTOCOMMIT, 0)可以关闭连接的自动提交 SQLSetConnectOption(conn, SQL_AUTOCOMMIT, 0)
-
Transactions must then be committed or rolled back explicitly by
SQLTransact(conn, SQL_COMMIT)orSQLTransact(conn, SQL_ROLLBACK)事务必须由
SQLTransact(conn, SQL_COMMIT)或SQLTransact(conn, SQL_ROLLBACK)显式提交或回滚
-
5.1.1.4 Embedded SQL¶
A language to which SQL queries are embedded is referred to as a host language, and the SQL structures permitted in the host language comprise embedded SQL.
如把 SQL 嵌入到 C 语言,那么 C 语言是 host.
在编译前,有一个预编译器,将 SQL 语句翻译。
EXEC SQL statement is used in the host language to identify embedded SQL request to the preprocessor (in Java, # SQL { ... };)
Issues with Embedded SQL
- Mark the start point and end point of Embedded SQL
EXEC SQL <statement>; //C
Before executing any SQL statements, the program must first connect to the database. This is done using: EXEC-SQL connect to server user user-name using password;
在执行任何SQL指令之前,需要先连接数据库
Variables of the host language can be used within embedded SQL statements. They are preceded by a colon (:) to distinguish from SQL variables (e.g., :credit_amount )
host语言的变量可以在嵌入式 SQL 语句中使用。 它们前面有一个冒号 (:) 以区别于 SQL 变量(例如 :credit_amount )
要使用host语言的变量,需要先进行申明DECLARE
EXEC-SQL BEGIN DECLARE SECTION
int credit-amount ;
EXEC-SQL END DECLARE SECTION;
insert、delete、update、select(single record)
main( )
{
EXEC SQL INCLUDE SQLCA; //声明段开始
EXEC SQL BEGIN DECLARE SECTION;
char account_no [11]; //host variables(宿主变量)声明
char branch_name [16];
int balance;
EXEC SQL END DECLARE SECTION;//声明段结束
EXEC SQL CONNECT TO bank_db USER Adam Using Eve;
// EXEC SQL CONNECT TO语句连接上了数据库
scanf (“%s %s %d”, account_no, branch_name, balance);
// EXEC SQL 语句后面直接接上SQL语句即可
// 插入
EXEC SQL insert into account
values (:account_no, :branch_name, :balance);
If (SQLCA.sqlcode ! = 0) printf ( “Error!\n”);
else printf (“Success!\n”);
// 删除
EXEC SQL delete from account
where account_number = :account_no;
If (SQLCA.sqlcode ! = 0) printf ( “Error!\n”);
else printf (“Success!\n”);
// 更新
EXEC SQL update account
set balance = balance + :balance
where account_number = :account_no;
If (SQLCA.sqlcode ! = 0) printf ( “Error!\n”);
else printf (“Success!\n”);
}
SQLCA.sqlcode表达的是运行上述语句时是否发生错误,如果不为0则发生错误
5.2 Procedural Constructs in SQL¶
SQL provides a module language
Permits definition of procedures in SQL, with if-then-else statements, for and while loops, etc.
允许在 SQL 中定义过程,包括 if-then-else 语句、for 和 while 循环等
Stored Procedures
-
Can store procedures in the database
将过程存储在数据库中
-
then execute them using the call statement
使用 call 语句执行它们
-
permit external applications to operate on the database without knowing about internal details
允许外部应用程序在不了解内部详细信息的情况下对数据库进行操作
5.2.1 SQL Functions¶

dept_count的作用是:上传一个系的名字,返回该系的老师的数量

SQL 函数的返回值可以是一个 table.
5.2.2 SQL Procedures¶
有输入参数(in)和输出参数(out)

输入的是 dept_name, 输出的是d_count
调用过程使用call
5.2.3 Procedural Constructs¶
Compound statement: begin ... end,
-
May contain multiple SQL statements between
beginandend.begin end之间可以有多个SQL语句
-
Local variables can be declared within a compound statements
局部变量可以在复合语句中声明
-
Whileandrepeatstatements
declare n integer default 0; while n < 10 do set n = n + 1 end while repeat set n = n – 1 until n = 0 end repeatwhile 和 repeat能够达到相同的效果,一个条件在前,一个条件在后
-
Forloop Permits iteration over all results of a query允许遍历查询的所有结果
r 表示返回的每一行,对返回结果的每一行执行指令declare n integer default 0; for r as select budget from department where dept_name = ‘Music’ do set n = n - r.budget end for -
条件判断语句
if boolean expression
then statement or compound statement
elseif boolean expression
then statement or compound statement
else statement or compound statement
end if

5.2.4 External Language Functions/Procedures¶
SQL 可以访问由 C 语言定义的函数(过程)
create procedure dept_count_proc(in dept_name varchar(20), count integer)
language C
external name ’ /usr/avi/bin/dept_count_proc’
create function dept_count(dept_name varchar(20))
returns integer
language C
external name ‘/usr/avi/bin/dept_count’
缺点:
实现功能的代码可能需要加载到数据库系统中并在数据库系统的地址空间中执行。
- 数据库结构意外损坏的风险
- 安全风险,允许用户访问未经授权的数据
5.3 Triggers¶
A trigger is a statement that is executed automatically by the system as a side effect of a modification to the database.
A trigger 是系统自动执行的语句,作为修改数据库的副作用。
Trigger - ECA rule
- E: Event ( insert, delete ,update)
- C: Condition
- A: Action
To design a trigger mechanism, we must: 设计触发机制
-
Specify the conditions under which the trigger is to be executed.
指定执行触发器的条件
-
Specify the actions to be taken when the trigger executes.
指定触发器执行时要执行的操作。

定义了一个触发器,触发发生在我们对account表的balance属性做更新后。
如果存款金额超过200000元,或者取款金额超过50000元,那么就要在account_log表中插入一行数据,记录下这次存款/取款操作。
for each row表示针对每一行发生的变化
for each statement 表示针对每一条指令

属性time_slot_id不是表time_slot的主键
我们不能利用属性time_slot_id创造一个从课程section表指向time_slot的表的外键
课程表中的time_slot_id又必须存在于表time_slot中,这属于参照完整性。
我们可以利用触发器,在进行不符合参照完整性的操作发生后进行回退,从而维护这一点。

如果旧的这一行的time_slot_id不能在表timeslot中找到,说明被删除的一个time_slot_id是最后的一个。如果此时并且旧的这一行的time_slot_id同时在课程表section中,那么就会引发参照完整性的问题。
因此,触发器在对表timeslot做删除操作后触发,如果出现了上述的情况,就会回退,不让这个删除操作发生。
等价于 on delete restrict,由于不是主键(外键),不能用on delete cascade / restrict/ default
-
Triggering event can be insert, delete or update
-
Triggers on update can be restricted to specific attributes
e.g. after(before) update of takes on grade -
Values of attributes before and after an update can be referenced
可以引用更新前后的属性值
-
referencing old row as: for deletes and updates
将旧行引用为:用于删除和更新
-
referencing new row as: for inserts and updates
将新行引用为:用于插入和更新
-

如果本来挂科,或者没有成绩,更新后不再挂科而且有成绩,就把学分加上去。
要慎用触发器,用在刀刃上,可能会引发连锁反应。
Instead of executing a separate action for each affected row, a single action can be executed for all rows affected by a transaction
-
Use
for each statementinstead offor each row假设是for each row,那么更新表account的每一行的balance值时,都会触发一次触发器,做相应的操作。
假设时for each statement,那么尽管一次update语句能够更新多行的balance值,但是执行这一个语句,触发器只会在语句执行完毕后触发一次
-
Use
referencing old tableorreferencing new tableto refer to temporary tables (called transition tables) containing the affected rows如果使用for each statement,那么就没有old row与new row的概念了,而是old table与new table
-
Can be more efficient when dealing with SQL statements that update a large number of rows

每次对表takes的属性grade做更新后(不管更新了几条数据),如果有平均成绩小于六十分的教学班,那么就回退。这个触发器在执行完update语句后,触发一次。